+tcpdump -nn icmp
+```
+
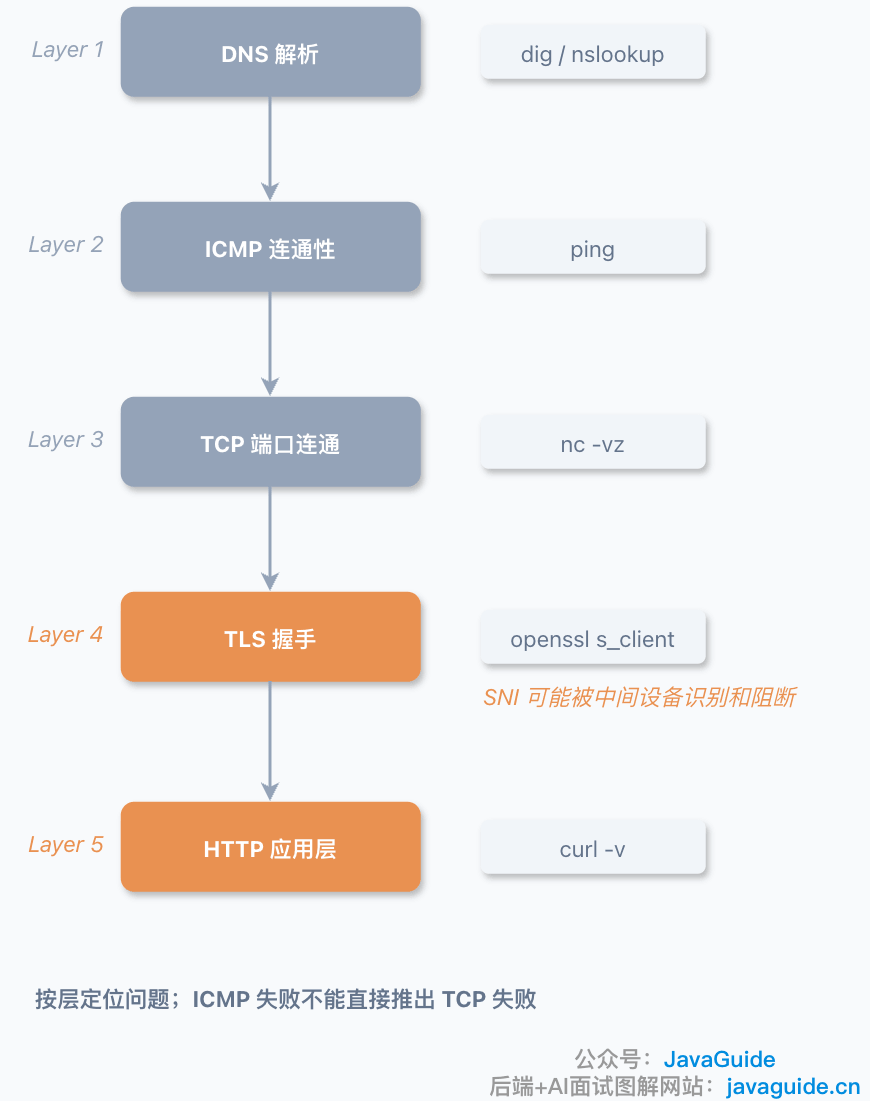
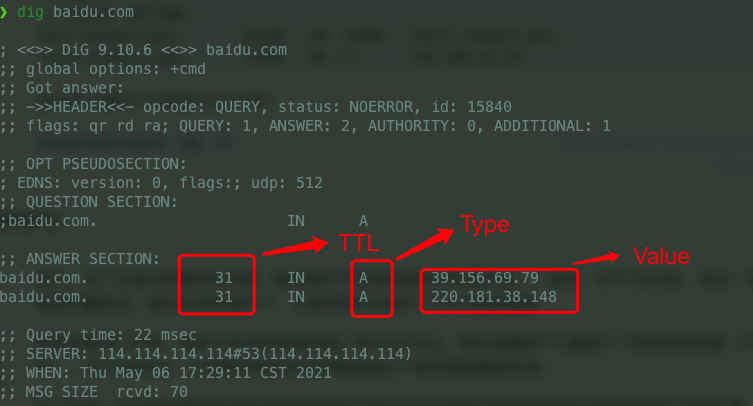
+只看到 `SYN` 重传,通常说明 TCP 层还没通;TCP 已建立但 TLS 卡住,再继续看 `ClientHello`、SNI、证书、代理和安全策略。
+
+## HTTPS 也可能卡在 SNI
+
+还有个容易误判的地方:同样是 `443`,同样是 HTTPS,也不代表一定能过。
+
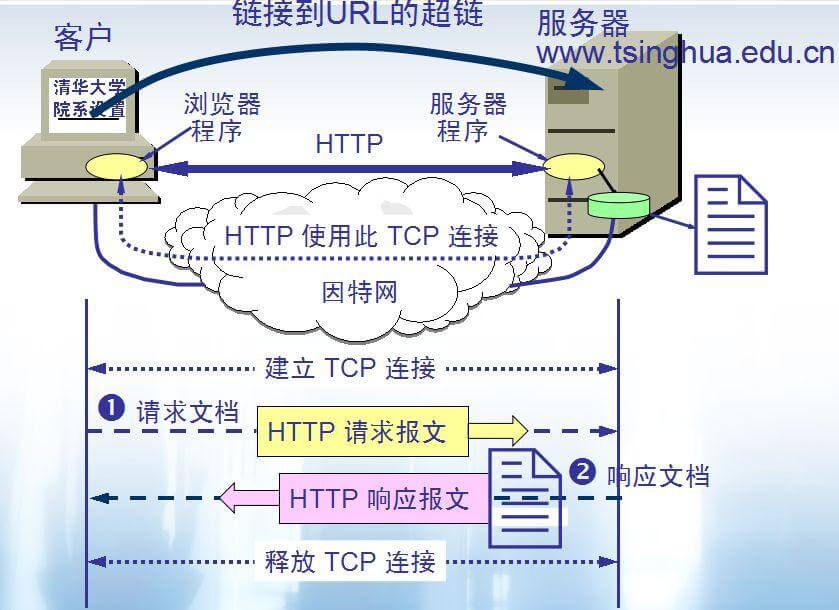
+HTTPS 的正文内容会加密,但 TLS 握手一开始的 `ClientHello` 里,通常会带 SNI(Server Name Indication,TLS 扩展)。SNI 的作用是告诉服务器“我要访问哪个域名”,这样同一个 IP 才能挂多个 HTTPS 站点。
+
+问题是,传统 SNI 通常是明文的。
+
+
+
+从上图可以看到,TLS 握手分为多个阶段:ClientHello(携带 SNI、支持的密码套件)→ ServerHello(选定密码套件)→ 证书 → 密钥交换 → 双方计算共享秘密 → 握手完成。中间设备不需要解密 HTTPS 内容,只需要看一眼 `ClientHello`,就可能知道你要访问哪个域名,并按域名策略处理这条连接。
+
+TLS 生态后来引入了 ECH(Encrypted ClientHello)来加密更多 `ClientHello` 信息,包括真实 SNI。不过 ECH 是否生效取决于客户端、服务端、DNS `HTTPS` / SVCB 记录和网络环境,不能默认所有 HTTPS 都已经隐藏 SNI。
+
+命中策略后,中间设备可能静默丢弃、注入 `RST`、终止 TLS、返回拦截页,或者让连接卡在 TLS 握手阶段。具体表现取决于防火墙、代理或安全设备实现。
+
+这类问题抓包时会比较迷惑:TCP 三次握手可能已经成功,连接看起来也建立了,但 `ClientHello` 发出去之后就没响应,或者很快被重置。
+
+所以,“TCP 通了”和“HTTPS 能正常访问”也不是同一句话。前者看三次握手,后者还要看 TLS 握手、SNI、证书、代理和安全策略。
+
+## 小结
+
+`ping` 测的是 ICMP;TCP 要看目标端口有没有监听、三次握手能不能完成、中间设备有没有放行;HTTPS 还可能卡在 TLS 握手,尤其是 SNI 这一步。
+
+反过来也一样:Ping 不通,不代表 TCP 一定不通。有些服务器或云安全组会直接禁 ICMP,但业务端口仍然正常。所以排查时不要用一个命令下结论,要按层验证。
+
+小 G 一般会按这个顺序查:如果是域名,先看 DNS;再用 `ping` 看 ICMP;然后用 `nc` 测端口;最后用 `curl` 或 `openssl s_client` 看 HTTPS/TLS。别让一个 `ping` 过早把问题定性了。
+
+
diff --git a/docs/cs-basics/network/can-tcp-and-udp-use-the-same-port.md b/docs/cs-basics/network/can-tcp-and-udp-use-the-same-port.md
new file mode 100644
index 00000000000..b04b97cf26c
--- /dev/null
+++ b/docs/cs-basics/network/can-tcp-and-udp-use-the-same-port.md
@@ -0,0 +1,129 @@
+---
+title: TCP 和 UDP 可以使用同一个端口吗?
+description: 讲清 TCP 和 UDP 是否可以使用同一个端口,以及端口空间、绑定规则和常见例子。
+category: 计算机基础
+tag:
+ - 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: TCP,UDP,端口,socket,bind,DNS 53,HTTP3,QUIC,UDP 443
+---
+
+面试里经常会碰到这个问题:一台机器上,TCP 已经监听了 `8080`,UDP 还能不能再监听 `8080`?
+
+先说结论:**可以。TCP 和 UDP 的端口绑定命名空间按传输层协议区分,同一个数字端口在不同协议下不冲突。** 一个进程监听 `TCP/8080`,另一个进程监听 `UDP/8080`,内核会根据协议栈分别分发。
+
+## 端口号到底归谁管?
+
+端口是传输层用来区分应用进程的编号。IP 地址定位主机,端口号定位这台主机上的具体应用。
+
+TCP 和 UDP 报文头里都有源端口和目的端口字段,字段长度都是 16 位(16 bits),所以端口号范围都是 `0~65535`。不过端口 `0` 在实际 API 里通常有特殊含义,比如让系统自动分配临时端口,不适合作为普通服务监听端口讲解。
+
+**数字范围相同,不代表绑定对象相同**。服务注册、监听、抓包、防火墙和安全组规则里,通常都要把传输层协议和端口一起看,比如 `TCP/53`、`UDP/53`、`TCP/443`、`UDP/443`。
+
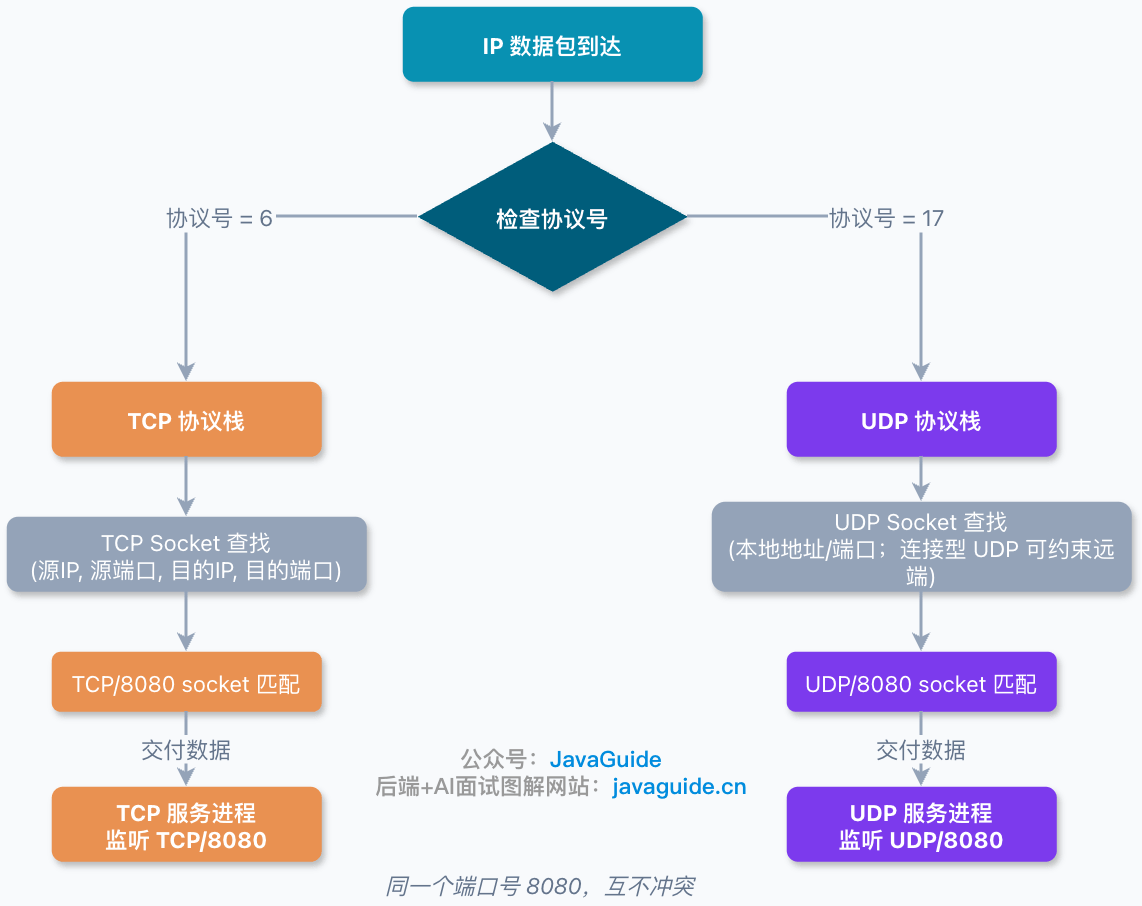
+`TCP/443` 和 `UDP/443` 只是数字一样,协议栈处理路径不同。收到 IP 包后,内核会先看 IP 层的协议标识:IPv4 里是 Protocol 字段,IPv6 里对应 Next Header。TCP 的协议号是 `6`,UDP 是 `17`。在进入端口分发之前,内核已经根据协议号把报文交给对应的 TCP 或 UDP 协议栈。
+
+
+
+TCP 和 UDP 虽然都在传输层,但差异很大。下表从 8 个维度对比一下,方便建立整体认知:
+
+| 特性 | TCP | UDP |
+| ------------ | --------------------------------------------- | ----------------------------------- |
+| **连接性** | 面向连接(三次握手建连、四次挥手释放) | 无连接,直接发 |
+| **可靠性** | 可靠(序列号、ACK、重传、流量控制、拥塞控制) | 不可靠,尽最大努力交付 |
+| **状态维护** | 有状态,维护连接信息 | 无状态,发完就不管了 |
+| **传输效率** | 较低(建连、确认、重传开销大) | 较高(结构简单、开销小) |
+| **传输形式** | 面向字节流,不保留消息边界 | 面向报文,天然保留消息边界 |
+| **首部开销** | 20~60 字节 | 固定 8 字节 |
+| **通信模式** | 点对点(单播) | 单播、多播、广播都支持 |
+| **常见应用** | HTTP/HTTPS、FTP、SMTP、SSH | DNS、DHCP、SNMP、TFTP、VoIP、视频流 |
+
+正因为 TCP 和 UDP 是两套完全独立的传输层协议,内核才会在端口分发之前先把它们分开处理。
+
+## socket 绑定时为什么不冲突?
+
+服务端程序通常会先创建 socket,再通过 `bind()` 绑定本地 IP 和端口。一个 TCP socket 绑定 `8080`,另一个 UDP socket 也绑定 `8080`,通常可以同时存在。内核判断冲突时,不只看端口数字,还会看协议、本地地址等信息。
+
+对于 TCP 来说,一条已建立连接通常可以用四元组标识:源 IP、源端口、目的 IP、目的端口。在防火墙、NAT、抓包和流量排查里,也常把传输层协议加进去,称为五元组:
+
+```text
+协议、源 IP、源端口、目的 IP、目的端口
+```
+
+两条通信的目的端口都可以是 `8080`,只要协议不同,内核就不会把它们当成同一条通信。UDP 没有 TCP 那种连接状态机,但收发数据时同样会带上源 IP、源端口、目的 IP、目的端口。
+
+## 简单验证一下
+
+可以用 `nc` 快速试一下。不过不同系统里的 `nc` 实现不完全一样,`-l`、`-u` 和端口参数写法可能有差异。以下是 OpenBSD netcat 常见写法,命令报错时可以先用 `nc -h` 看本机帮助。
+
+先启动 TCP 监听:
+
+```bash
+nc -l 8000
+```
+
+再启动 UDP 监听:
+
+```bash
+nc -u -l 8000
+```
+
+两个命令可以同时存在。在 Linux 上可以再查看:
+
+```bash
+ss -tulnp | grep 8000
+```
+
+通常会看到一条 `tcp` 和一条 `udp` 监听,端口号一样,但协议不同。
+
+如果想避开 `nc` 参数差异,也可以用代码验证:Java 里 `ServerSocket(8000)` 和 `DatagramSocket(8000)` 可以同时创建;Go 里 `net.Listen("tcp", ":8000")` 和 `net.ListenPacket("udp", ":8000")` 也可以同时存在。再用同一种协议重复监听一次,通常就会看到地址已被占用。
+
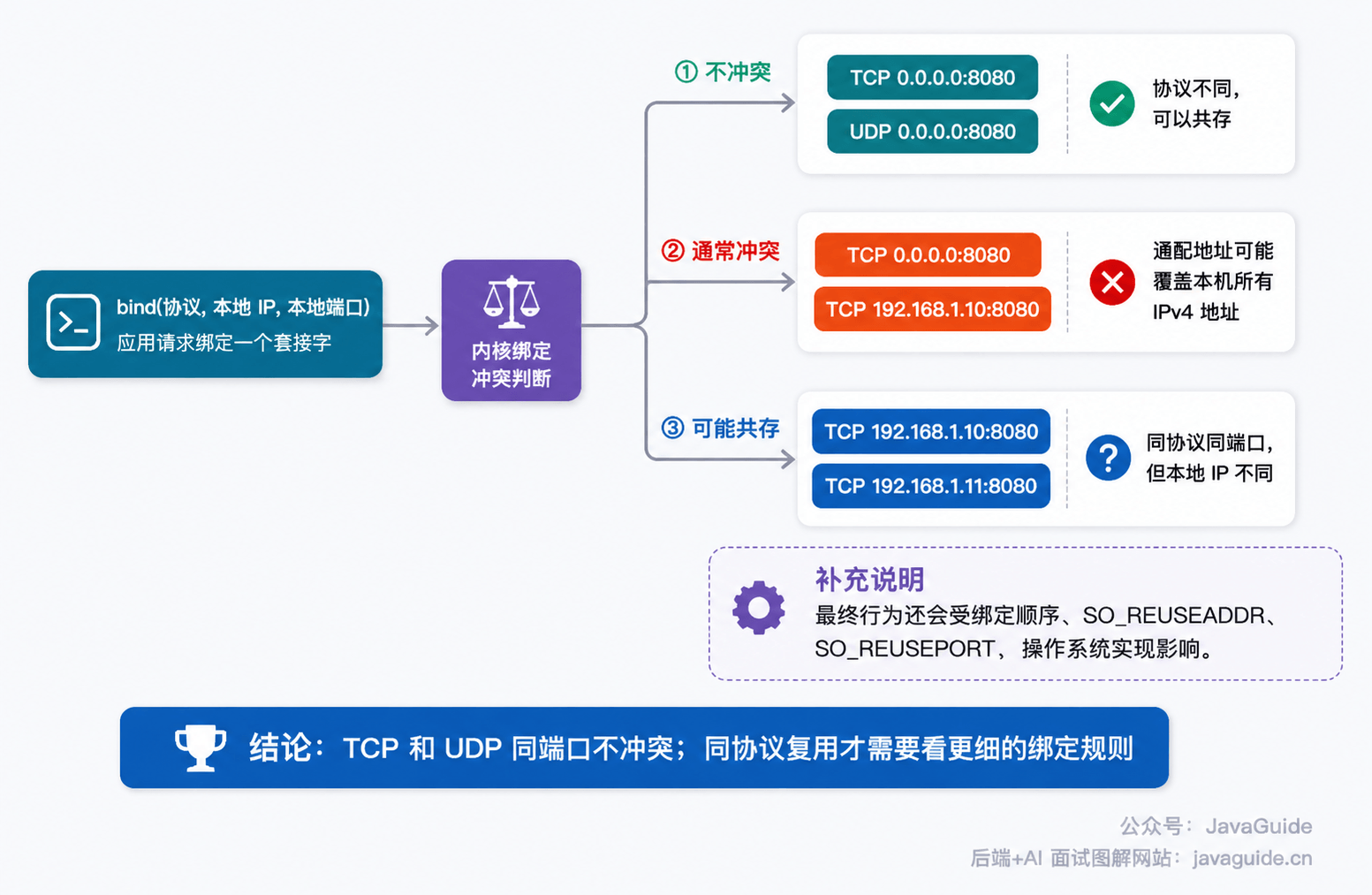
+## 什么时候会冲突?
+
+
+
+TCP 和 UDP 之间不冲突,不代表端口可以随便重复绑定。
+
+更常见的冲突发生在**同一个协议**里。比如一个进程已经绑定 `0.0.0.0:8080`,通常会覆盖本机所有 IPv4 地址上的 `8080`,另一个进程再绑定某个具体 IPv4 地址的 `TCP/8080` 往往会冲突;但最终行为还会受绑定顺序、`SO_REUSEADDR`、`SO_REUSEPORT` 和操作系统实现影响。
+
+如果两个进程绑定的是不同本地 IP,同协议同端口也可能成立,例如 `192.168.1.10:8080` 和 `192.168.1.11:8080` 都是 TCP。
+
+还有一个容易被忽略的点:IPv6 的通配地址 `[::]:8080` 在一些环境下可能同时接收 IPv6 和 IPv4-mapped 地址,`IPV6_V6ONLY` 会影响它是否和 IPv4 socket 冲突。排查时可以用 `ss -tulnp` 同时看 `0.0.0.0:端口` 和 `[::]:端口`。
+
+`SO_REUSEADDR`、`SO_REUSEPORT` 也会改变绑定规则,常用于快速重启、多进程监听、负载分摊等场景。这里小 G 建议先记住:
+
+**TCP 和 UDP 分别监听同一个数字端口,靠的是协议不同,不需要 `SO_REUSEPORT`。`SO_REUSEADDR` / `SO_REUSEPORT` 主要影响同一协议下的地址端口复用、快速重启和多进程监听,但是否允许、如何分流,要看操作系统和具体 socket 类型。**
+
+## 分享两个实际案例
+
+### DNS 为什么同时用 TCP/UDP 53?
+
+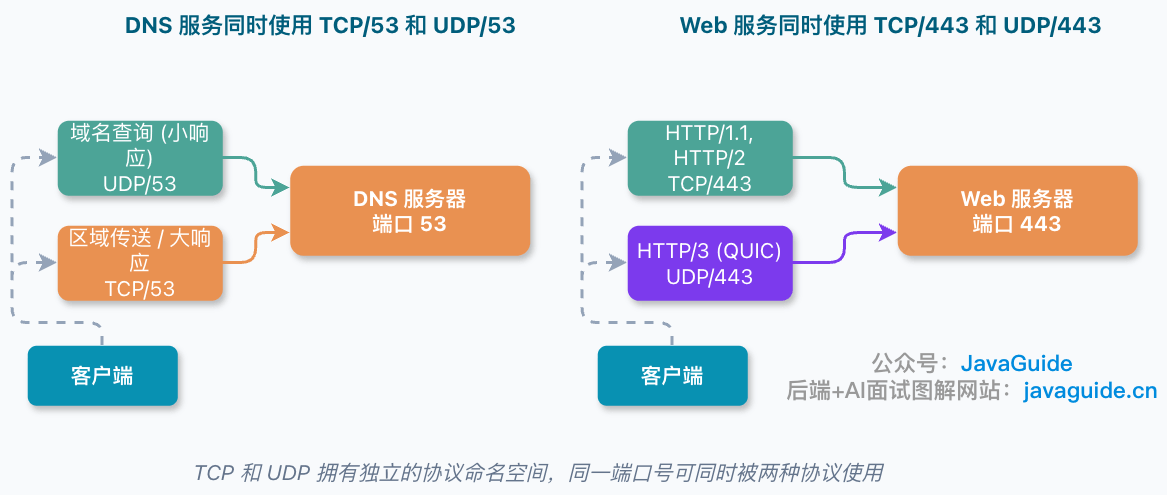
+
+DNS 是最经典的例子。IANA 注册表里,`domain` 服务同时注册了 `TCP/53` 和 `UDP/53`,实际 DNS 服务也经常同时监听这两个端口。
+
+日常域名查询通常走 UDP,因为查询和响应比较小,UDP 不需要建连,速度快。但以下几种情况会切换到 TCP:UDP 响应被截断(DNS 报文头 `TC` 标志位置 1,常见于响应超过 UDP 长度限制时)、区域传送(Zone Transfer,需要可靠传输保证数据完整性)、或者 DNSSEC 响应过大。这里不是“`UDP/53` 被占了,所以 `TCP/53` 不能用”,而是 DNS 本来就可以同时使用两套协议的 `53`。
+
+### HTTPS 和 HTTP/3 的 443 也是这个道理
+
+传统 HTTPS 通常是 HTTP/1.1 或 HTTP/2 over TLS over TCP,默认使用 `TCP/443`。HTTP/3 跑在 QUIC 上,而 QUIC 基于 UDP。浏览器通常会通过 `Alt-Svc` 或 `HTTPS` DNS 记录获知服务端支持 HTTP/3,然后尝试建立 QUIC 连接;常见部署是同时开放 `TCP/443` 和 `UDP/443`。
+
+
+
+这不会和原来的 `TCP/443` 冲突。一个服务器完全可以同时提供:
+
+```text
+HTTPS(HTTP/1.1、HTTP/2) -> TCP/443
+HTTP/3 -> UDP/443
+```
+
+从外部看都是 `443`,从协议栈看是两条路。
+
+生产环境里也要注意:只放行 `TCP/443` 时,HTTP/1.1 和 HTTP/2 可能都正常,但 HTTP/3 不会生效。云安全组、负载均衡、Nginx / 网关和主机防火墙都要分别检查 `TCP/443` 和 `UDP/443`,再用 `curl --http3` 或浏览器开发者工具确认协议是否真的切到 HTTP/3。
+
+## 面试怎么回答?
+
+TCP 和 UDP 可以使用同一个数字端口,因为它们是不同的传输层协议;内核会先按 IP 协议号分发到 TCP 栈或 UDP 栈,再在各自协议栈内按地址和端口找 socket,所以 `TCP/8080` 和 `UDP/8080` 可以共存。
+
+真正容易冲突的是同协议下的绑定,比如两个 TCP 服务通常不能同时监听同一个本地 IP 和端口;这时才会涉及 `SO_REUSEADDR`、`SO_REUSEPORT` 这类 socket 复用选项。例子记两个就够了:DNS 同时使用 `UDP/53` 和 `TCP/53`;HTTP/3 常见部署是 `UDP/443`,可以和传统 HTTPS 的 `TCP/443` 同时存在。
diff --git a/docs/cs-basics/network/computer-network-xiexiren-summary.md b/docs/cs-basics/network/computer-network-xiexiren-summary.md
index fc9f60fd39a..f82a47d56ad 100644
--- a/docs/cs-basics/network/computer-network-xiexiren-summary.md
+++ b/docs/cs-basics/network/computer-network-xiexiren-summary.md
@@ -1,22 +1,36 @@
---
title: 《计算机网络》(谢希仁)内容总结
+description: 基于《计算机网络》教材的学习笔记,梳理术语与分层模型等核心知识点,便于期末复习与面试巩固。
category: 计算机基础
tag:
- 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: 计算机网络,谢希仁,术语,分层模型,链路,主机,教材总结
---
-本文是我在大二学习计算机网络期间整理, 大部分内容都来自于谢希仁老师的[《计算机网络》第七版](https://www.elias.ltd/usr/local/etc/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C%EF%BC%88%E7%AC%AC7%E7%89%88%EF%BC%89%E8%B0%A2%E5%B8%8C%E4%BB%81.pdf)这本书。为了内容更容易理解,我对之前的整理进行了一波重构,并配上了一些相关的示意图便于理解。
+这篇笔记来自我大二学习计算机网络时的整理,大部分内容参考谢希仁老师的[《计算机网络》第七版](https://www.elias.ltd/usr/local/etc/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C%EF%BC%88%E7%AC%AC7%E7%89%88%EF%BC%89%E8%B0%A2%E5%B8%8C%E4%BB%81.pdf)。
-
+计算机网络教材内容很散:术语、分层、链路、路由、运输层、应用层都要串起来看。为了复习起来更顺,我对原来的笔记做了一次重构,并补充了一些示意图。
-相关问题:[如何评价谢希仁的计算机网络(第七版)? - 知乎](https://www.zhihu.com/question/327872966) 。
+这篇文章主要回答几个问题:
+
+1. 计算机网络里常见基础术语分别是什么意思?
+2. OSI、TCP/IP 分层模型分别如何理解?
+3. 链路层、网络层、运输层、应用层各自解决什么问题?
+4. 复习《计算机网络》这本书时,哪些概念最容易混淆?
+
+
+
+相关问题:[如何评价谢希仁的计算机网络(第七版)? - 知乎](https://www.zhihu.com/question/327872966)。
## 1. 计算机网络概述
### 1.1. 基本术语
-1. **结点 (node)**:网络中的结点可以是计算机,集线器,交换机或路由器等。
-2. **链路(link )** : 从一个结点到另一个结点的一段物理线路。中间没有任何其他交点。
+1. **结点(node)**:网络中的结点可以是计算机,集线器,交换机或路由器等。
+2. **链路(link)**:从一个结点到另一个结点的一段物理线路。中间没有任何其他交点。
3. **主机(host)**:连接在因特网上的计算机。
4. **ISP(Internet Service Provider)**:因特网服务提供者(提供商)。
@@ -28,7 +42,7 @@ tag:
https://labs.ripe.net/Members/fergalc/ixp-traffic-during-stratos-skydive
-6. **RFC(Request For Comments)**:意思是“请求评议”,包含了关于 Internet 几乎所有的重要的文字资料。
+6. **RFC(Request For Comments)**:意思是“请求评议”,包含了关于 Internet 几乎所有的重要的文字资料。
7. **广域网 WAN(Wide Area Network)**:任务是通过长距离运送主机发送的数据。
8. **城域网 MAN(Metropolitan Area Network)**:用来将多个局域网进行互连。
9. **局域网 LAN(Local Area Network)**:学校或企业大多拥有多个互连的局域网。
@@ -37,19 +51,19 @@ tag:
http://conexionesmanwman.blogspot.com/
-10. **个人区域网 PAN(Personal Area Network)**:在个人工作的地方把属于个人使用的电子设备用无线技术连接起来的网络 。
+10. **个人区域网 PAN(Personal Area Network)**:在个人工作的地方把属于个人使用的电子设备用无线技术连接起来的网络。
- https://www.itrelease.com/2018/07/advantages-and-disadvantages-of-personal-area-network-pan/
+ https://www.itrelease.com/2018/07/advantages-and-disadvantages-of-personal-area-network-pan/
-11. **分组(packet )**:因特网中传送的数据单元。由首部 header 和数据段组成。分组又称为包,首部可称为包头。
-12. **存储转发(store and forward )**:路由器收到一个分组,先检查分组是否正确,并过滤掉冲突包错误。确定包正确后,取出目的地址,通过查找表找到想要发送的输出端口地址,然后将该包发送出去。
+11. **分组(packet)**:因特网中传送的数据单元。由首部 header 和数据段组成。分组又称为包,首部可称为包头。
+12. **存储转发(store and forward)**:路由器收到一个分组,先检查分组是否正确,并过滤掉冲突包错误。确定包正确后,取出目的地址,通过查找表找到想要发送的输出端口地址,然后将该包发送出去。
- 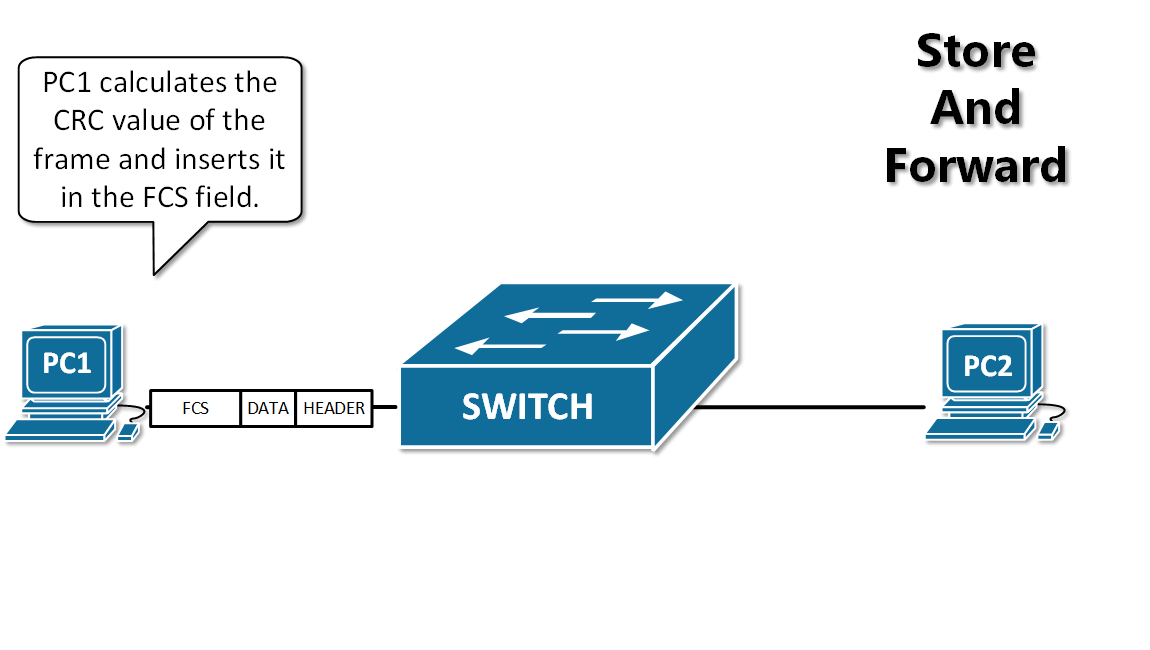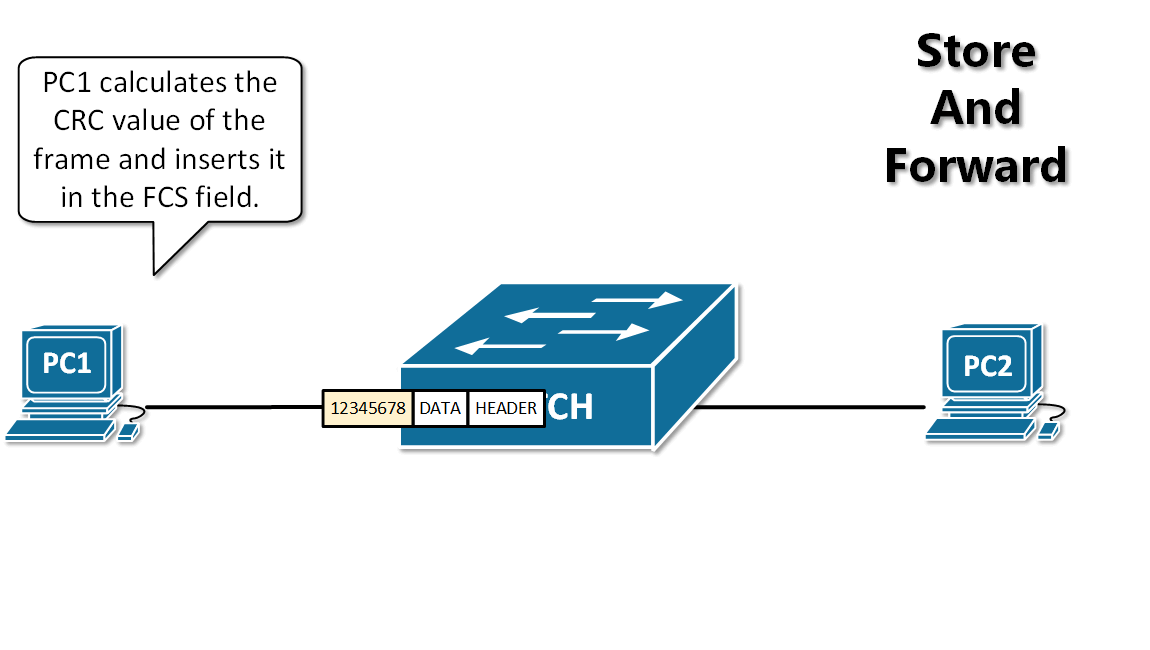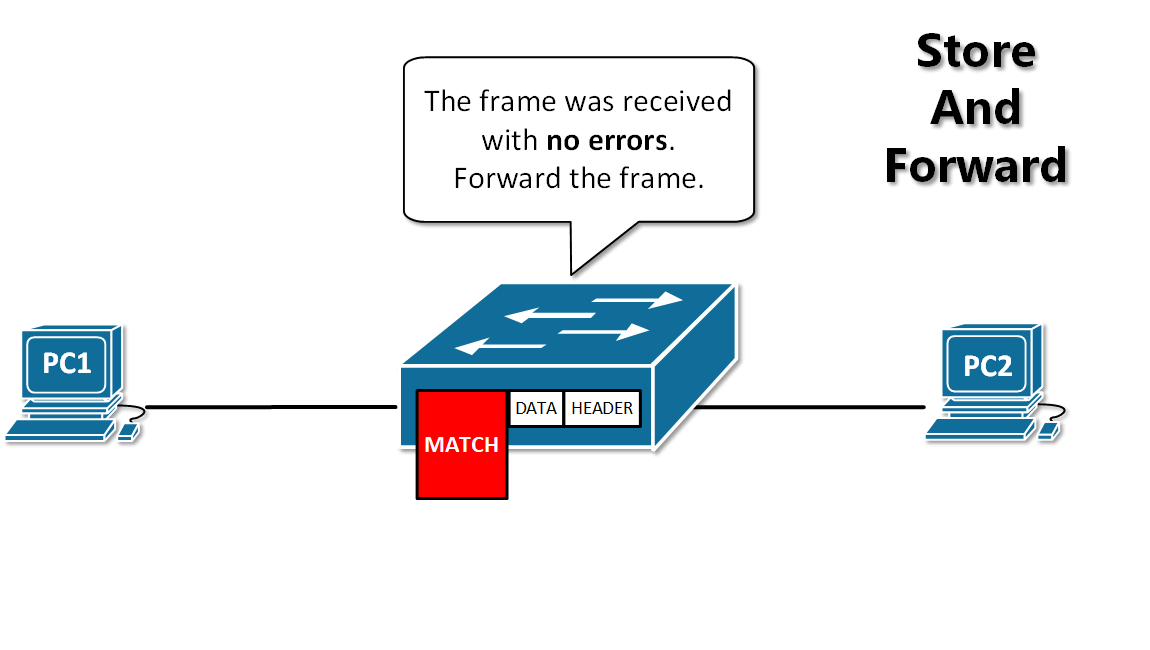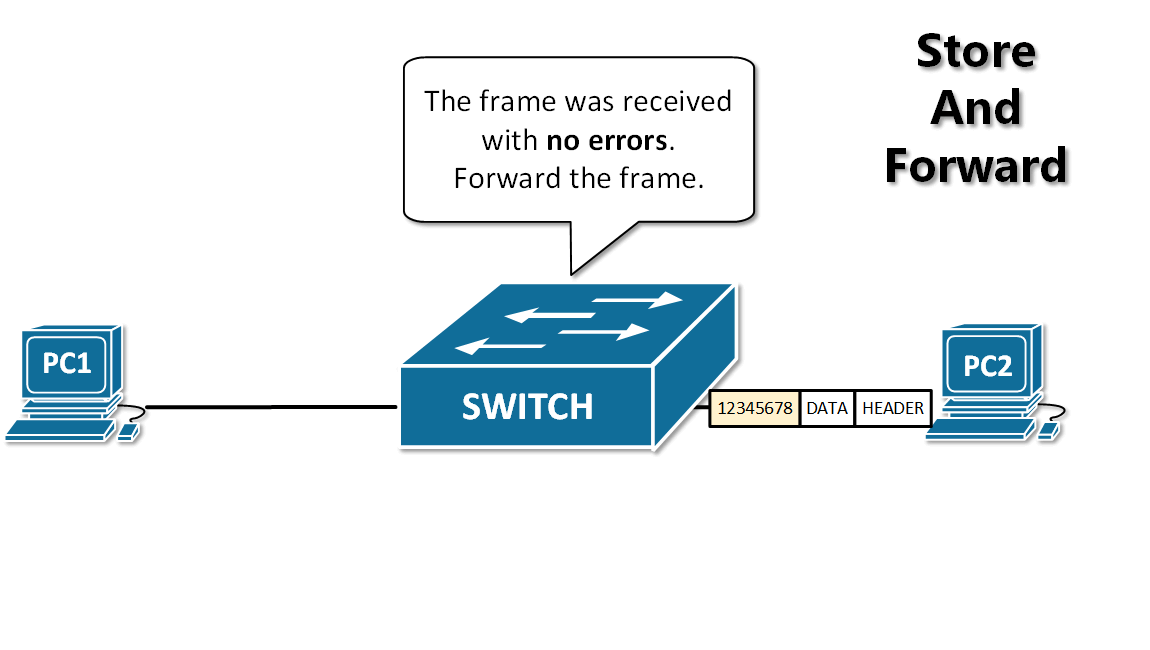
+ 
13. **带宽(bandwidth)**:在计算机网络中,表示在单位时间内从网络中的某一点到另一点所能通过的“最高数据率”。常用来表示网络的通信线路所能传送数据的能力。单位是“比特每秒”,记为 b/s。
-14. **吞吐量(throughput )**:表示在单位时间内通过某个网络(或信道、接口)的数据量。吞吐量更经常地用于对现实世界中的网络的一种测量,以便知道实际上到底有多少数据量能够通过网络。吞吐量受网络的带宽或网络的额定速率的限制。
+14. **吞吐量(throughput)**:表示在单位时间内通过某个网络(或信道、接口)的数据量。吞吐量更经常地用于对现实世界中的网络的一种测量,以便知道实际上到底有多少数据量能够通过网络。吞吐量受网络的带宽或网络的额定速率的限制。
### 1.2. 重要知识点总结
@@ -64,7 +78,7 @@ tag:
9. 网络协议即协议,是为进行网络中的数据交换而建立的规则。计算机网络的各层以及其协议集合,称为网络的体系结构。
10. **五层体系结构由应用层,运输层,网络层(网际层),数据链路层,物理层组成。运输层最主要的协议是 TCP 和 UDP 协议,网络层最重要的协议是 IP 协议。**
-
+
下面的内容会介绍计算机网络的五层体系结构:**物理层+数据链路层+网络层(网际层)+运输层+应用层**。
@@ -76,31 +90,31 @@ tag:
1. **数据(data)**:运送消息的实体。
2. **信号(signal)**:数据的电气的或电磁的表现。或者说信号是适合在传输介质上传输的对象。
-3. **码元( code)**:在使用时间域(或简称为时域)的波形来表示数字信号时,代表不同离散数值的基本波形。
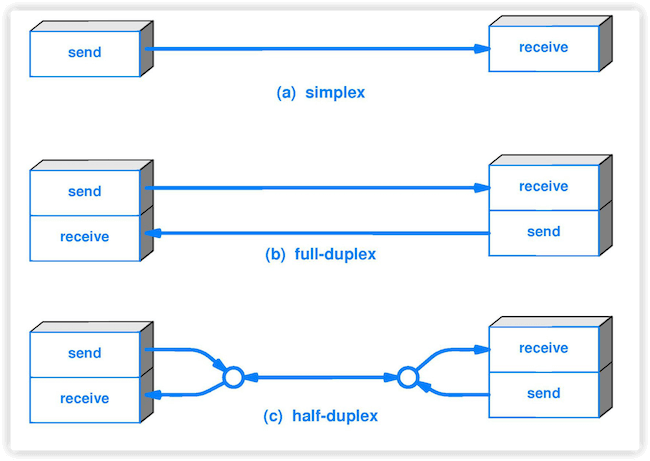
-4. **单工(simplex )**:只能有一个方向的通信而没有反方向的交互。
-5. **半双工(half duplex )**:通信的双方都可以发送信息,但不能双方同时发送(当然也就不能同时接收)。
+3. **码元(code)**:在使用时间域(或简称为时域)的波形来表示数字信号时,代表不同离散数值的基本波形。
+4. **单工(simplex)**:只能有一个方向的通信而没有反方向的交互。
+5. **半双工(half duplex)**:通信的双方都可以发送信息,但不能双方同时发送(当然也就不能同时接收)。
6. **全双工(full duplex)**:通信的双方可以同时发送和接收信息。
- 
+ 
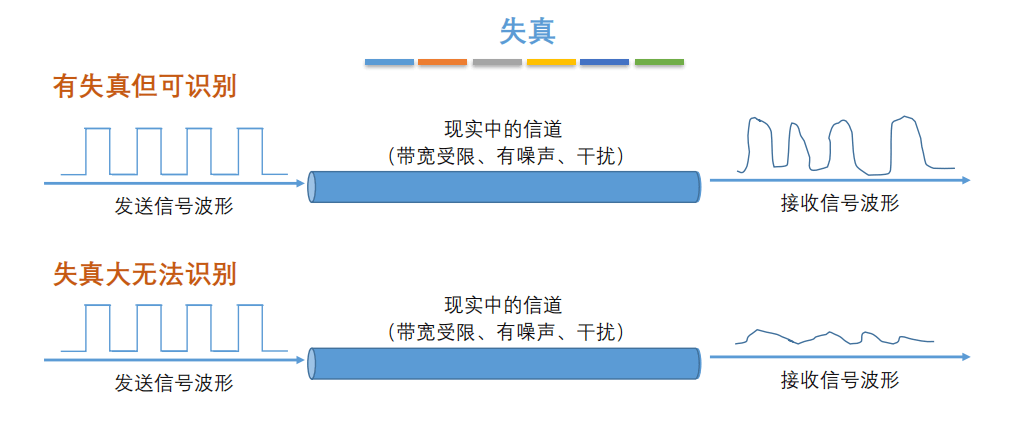
7. **失真**:失去真实性,主要是指接受到的信号和发送的信号不同,有磨损和衰减。影响失真程度的因素:1.码元传输速率 2.信号传输距离 3.噪声干扰 4.传输媒体质量
- 
+ 
8. **奈氏准则**:在任何信道中,码元的传输的效率是有上限的,传输速率超过此上限,就会出现严重的码间串扰问题,使接收端对码元的判决(即识别)成为不可能。
9. **香农定理**:在带宽受限且有噪声的信道中,为了不产生误差,信息的数据传输速率有上限值。
10. **基带信号(baseband signal)**:来自信源的信号。指没有经过调制的数字信号或模拟信号。
11. **带通(频带)信号(bandpass signal)**:把基带信号经过载波调制后,把信号的频率范围搬移到较高的频段以便在信道中传输(即仅在一段频率范围内能够通过信道),这里调制过后的信号就是带通信号。
-12. **调制(modulation )**:对信号源的信息进行处理后加到载波信号上,使其变为适合在信道传输的形式的过程。
-13. **信噪比(signal-to-noise ratio )**:指信号的平均功率和噪声的平均功率之比,记为 S/N。信噪比(dB)=10\*log10(S/N)。
-14. **信道复用(channel multiplexing )**:指多个用户共享同一个信道。(并不一定是同时)。
+12. **调制(modulation)**:对信号源的信息进行处理后加到载波信号上,使其变为适合在信道传输的形式的过程。
+13. **信噪比(signal-to-noise ratio)**:指信号的平均功率和噪声的平均功率之比,记为 S/N。信噪比(dB)=10\*log10(S/N)。
+14. **信道复用(channel multiplexing)**:指多个用户共享同一个信道。(并不一定是同时)。
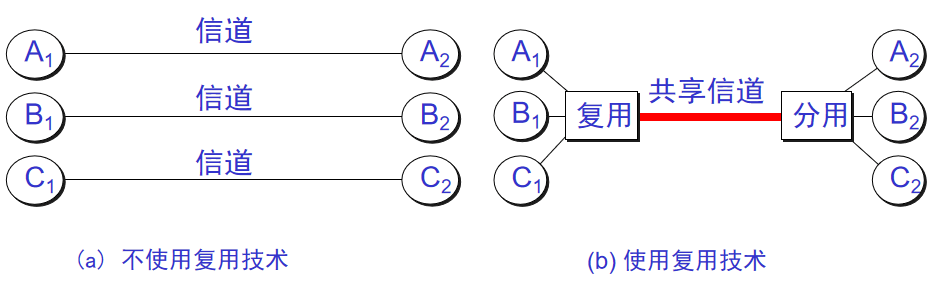
-15. **比特率(bit rate )**:单位时间(每秒)内传送的比特数。
+15. **比特率(bit rate)**:单位时间(每秒)内传送的比特数。
16. **波特率(baud rate)**:单位时间载波调制状态改变的次数。针对数据信号对载波的调制速率。
17. **复用(multiplexing)**:共享信道的方法。
-18. **ADSL(Asymmetric Digital Subscriber Line )**:非对称数字用户线。
+18. **ADSL(Asymmetric Digital Subscriber Line)**:非对称数字用户线。
19. **光纤同轴混合网(HFC 网)**:在目前覆盖范围很广的有线电视网的基础上开发的一种居民宽带接入网
### 2.2. 重要知识点总结
@@ -125,11 +139,11 @@ tag:
#### 2.3.2. 几种常用的信道复用技术
-1. **频分复用(FDM)**:所有用户在同样的时间占用不同的带宽资源。
+1. **频分复用(FDM)**:所有用户在同样的时间占用不同的带宽资源。
2. **时分复用(TDM)**:所有用户在不同的时间占用同样的频带宽度(分时不分频)。
-3. **统计时分复用 (Statistic TDM)**:改进的时分复用,能够明显提高信道的利用率。
-4. **码分复用(CDM)**:用户使用经过特殊挑选的不同码型,因此各用户之间不会造成干扰。这种系统发送的信号有很强的抗干扰能力,其频谱类似于白噪声,不易被敌人发现。
-5. **波分复用( WDM)**:波分复用就是光的频分复用。
+3. **统计时分复用(Statistic TDM)**:改进的时分复用,能够明显提高信道的利用率。
+4. **码分复用(CDM)**:用户使用经过特殊挑选的不同码型,因此各用户之间不会造成干扰。这种系统发送的信号有很强的抗干扰能力,其频谱类似于白噪声,不易被敌人发现。
+5. **波分复用(WDM)**:波分复用就是光的频分复用。
#### 2.3.3. 几种常用的宽带接入技术,主要是 ADSL 和 FTTx
@@ -145,16 +159,16 @@ tag:
2. **数据链路(data link)**:把实现控制数据运输的协议的硬件和软件加到链路上就构成了数据链路。
3. **循环冗余检验 CRC(Cyclic Redundancy Check)**:为了保证数据传输的可靠性,CRC 是数据链路层广泛使用的一种检错技术。
4. **帧(frame)**:一个数据链路层的传输单元,由一个数据链路层首部和其携带的封包所组成协议数据单元。
-5. **MTU(Maximum Transfer Uint )**:最大传送单元。帧的数据部分的的长度上限。
-6. **误码率 BER(Bit Error Rate )**:在一段时间内,传输错误的比特占所传输比特总数的比率。
-7. **PPP(Point-to-Point Protocol )**:点对点协议。即用户计算机和 ISP 进行通信时所使用的数据链路层协议。以下是 PPP 帧的示意图:
- 
-8. **MAC 地址(Media Access Control 或者 Medium Access Control)**:意译为媒体访问控制,或称为物理地址、硬件地址,用来定义网络设备的位置。在 OSI 模型中,第三层网络层负责 IP 地址,第二层数据链路层则负责 MAC 地址。因此一个主机会有一个 MAC 地址,而每个网络位置会有一个专属于它的 IP 地址 。地址是识别某个系统的重要标识符,“名字指出我们所要寻找的资源,地址指出资源所在的地方,路由告诉我们如何到达该处。”
+5. **MTU(Maximum Transfer Uint)**:最大传送单元。帧的数据部分的长度上限。
+6. **误码率 BER(Bit Error Rate)**:在一段时间内,传输错误的比特占所传输比特总数的比率。
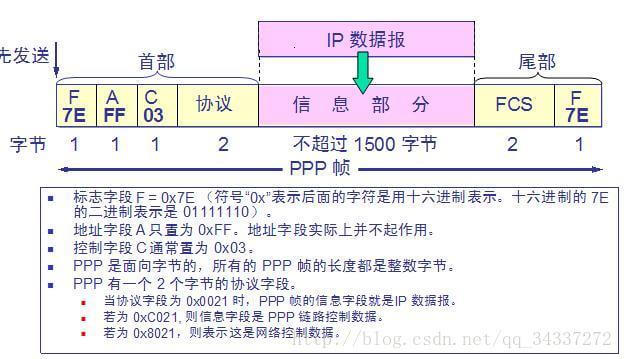
+7. **PPP(Point-to-Point Protocol)**:点对点协议。即用户计算机和 ISP 进行通信时所使用的数据链路层协议。以下是 PPP 帧的示意图:
+ 
+8. **MAC 地址(Media Access Control 或者 Medium Access Control)**:意译为媒体访问控制,或称为物理地址、硬件地址,用来定义网络设备的位置。在 OSI 模型中,第三层网络层负责 IP 地址,第二层数据链路层则负责 MAC 地址。因此一个主机会有一个 MAC 地址,而每个网络位置会有一个专属于它的 IP 地址。地址是识别某个系统的重要标识符,“名字指出我们所要寻找的资源,地址指出资源所在的地方,路由告诉我们如何到达该处。”

9. **网桥(bridge)**:一种用于数据链路层实现中继,连接两个或多个局域网的网络互连设备。
-10. **交换机(switch )**:广义的来说,交换机指的是一种通信系统中完成信息交换的设备。这里工作在数据链路层的交换机指的是交换式集线器,其实质是一个多接口的网桥
+10. **交换机(switch)**:广义的来说,交换机指的是一种通信系统中完成信息交换的设备。这里工作在数据链路层的交换机指的是交换式集线器,其实质是一个多接口的网桥
### 3.2. 重要知识点总结
@@ -185,13 +199,13 @@ tag:
### 4.1. 基本术语
1. **虚电路(Virtual Circuit)** : 在两个终端设备的逻辑或物理端口之间,通过建立的双向的透明传输通道。虚电路表示这只是一条逻辑上的连接,分组都沿着这条逻辑连接按照存储转发方式传送,而并不是真正建立了一条物理连接。
-2. **IP(Internet Protocol )** : 网际协议 IP 是 TCP/IP 体系中两个最主要的协议之一,是 TCP/IP 体系结构网际层的核心。配套的有 ARP,RARP,ICMP,IGMP。
+2. **IP(Internet Protocol)**:网际协议 IP 是 TCP/IP 体系中两个最主要的协议之一,是 TCP/IP 体系结构网际层的核心。配套的有 ARP,RARP,ICMP,IGMP。
3. **ARP(Address Resolution Protocol)** : 地址解析协议。地址解析协议 ARP 把 IP 地址解析为硬件地址。
-4. **ICMP(Internet Control Message Protocol )**:网际控制报文协议 (ICMP 允许主机或路由器报告差错情况和提供有关异常情况的报告)。
-5. **子网掩码(subnet mask )**:它是一种用来指明一个 IP 地址的哪些位标识的是主机所在的子网以及哪些位标识的是主机的位掩码。子网掩码不能单独存在,它必须结合 IP 地址一起使用。
-6. **CIDR( Classless Inter-Domain Routing )**:无分类域间路由选择 (特点是消除了传统的 A 类、B 类和 C 类地址以及划分子网的概念,并使用各种长度的“网络前缀”(network-prefix)来代替分类地址中的网络号和子网号)。
+4. **ICMP(Internet Control Message Protocol)**:网际控制报文协议(ICMP 允许主机或路由器报告差错情况和提供有关异常情况的报告)。
+5. **子网掩码(subnet mask)**:它是一种用来指明一个 IP 地址的哪些位标识的是主机所在的子网以及哪些位标识的是主机的位掩码。子网掩码不能单独存在,它必须结合 IP 地址一起使用。
+6. **CIDR(Classless Inter-Domain Routing)**:无分类域间路由选择(特点是消除了传统的 A 类、B 类和 C 类地址以及划分子网的概念,并使用各种长度的“网络前缀”(network-prefix)来代替分类地址中的网络号和子网号)。
7. **默认路由(default route)**:当在路由表中查不到能到达目的地址的路由时,路由器选择的路由。默认路由还可以减小路由表所占用的空间和搜索路由表所用的时间。
-8. **路由选择算法(Virtual Circuit)**:路由选择协议的核心部分。因特网采用自适应的,分层次的路由选择协议。
+8. **路由选择算法(Routing Algorithm)**:路由选择协议的核心部分。因特网采用自适应的、分层次的路由选择协议。
### 4.2. 重要知识点总结
@@ -222,7 +236,7 @@ tag:
6. **端口(port)**:端口的目的是为了确认对方机器的哪个进程在与自己进行交互,比如 MSN 和 QQ 的端口不同,如果没有端口就可能出现 QQ 进程和 MSN 交互错误。端口又称协议端口号。
7. **停止等待协议(stop-and-wait)**:指发送方每发送完一个分组就停止发送,等待对方确认,在收到确认之后在发送下一个分组。
-8. **流量控制** : 就是让发送方的发送速率不要太快,既要让接收方来得及接收,也不要使网络发生拥塞。
+8. **流量控制**:就是让发送方的发送速率不要太快,既要让接收方来得及接收,也不要使网络发生拥塞。
9. **拥塞控制**:防止过多的数据注入到网络中,这样可以使网络中的路由器或链路不致过载。拥塞控制所要做的都有一个前提,就是网络能够承受现有的网络负荷。
### 5.2. 重要知识点总结
@@ -230,8 +244,8 @@ tag:
1. **运输层提供应用进程之间的逻辑通信,也就是说,运输层之间的通信并不是真正在两个运输层之间直接传输数据。运输层向应用层屏蔽了下面网络的细节(如网络拓补,所采用的路由选择协议等),它使应用进程之间看起来好像两个运输层实体之间有一条端到端的逻辑通信信道。**
2. **网络层为主机提供逻辑通信,而运输层为应用进程之间提供端到端的逻辑通信。**
3. 运输层的两个重要协议是用户数据报协议 UDP 和传输控制协议 TCP。按照 OSI 的术语,两个对等运输实体在通信时传送的数据单位叫做运输协议数据单元 TPDU(Transport Protocol Data Unit)。但在 TCP/IP 体系中,则根据所使用的协议是 TCP 或 UDP,分别称之为 TCP 报文段或 UDP 用户数据报。
-4. **UDP 在传送数据之前不需要先建立连接,远地主机在收到 UDP 报文后,不需要给出任何确认。虽然 UDP 不提供可靠交付,但在某些情况下 UDP 确是一种最有效的工作方式。 TCP 提供面向连接的服务。在传送数据之前必须先建立连接,数据传送结束后要释放连接。TCP 不提供广播或多播服务。由于 TCP 要提供可靠的,面向连接的传输服务,难以避免地增加了许多开销,如确认,流量控制,计时器以及连接管理等。这不仅使协议数据单元的首部增大很多,还要占用许多处理机资源。**
-5. 硬件端口是不同硬件设备进行交互的接口,而软件端口是应用层各种协议进程与运输实体进行层间交互的一种地址。UDP 和 TCP 的首部格式中都有源端口和目的端口这两个重要字段。当运输层收到 IP 层交上来的运输层报文时,就能够根据其首部中的目的端口号把数据交付应用层的目的应用层。(两个进程之间进行通信不光要知道对方 IP 地址而且要知道对方的端口号(为了找到对方计算机中的应用进程))
+4. **UDP 在传送数据之前不需要先建立连接,远地主机在收到 UDP 报文后,不需要给出任何确认。虽然 UDP 不提供可靠交付,但在某些情况下 UDP 确是一种最有效的工作方式。TCP 提供面向连接的服务。在传送数据之前必须先建立连接,数据传送结束后要释放连接。TCP 不提供广播或多播服务。由于 TCP 要提供可靠的,面向连接的传输服务,难以避免地增加了许多开销,如确认,流量控制,计时器以及连接管理等。这不仅使协议数据单元的首部增大很多,还要占用许多处理机资源。**
+5. 硬件端口是不同硬件设备进行交互的接口,而软件端口是应用层各种协议进程与运输实体进行层间交互的一种地址。UDP 和 TCP 的首部格式中都有源端口和目的端口这两个重要字段。当运输层收到 IP 层交上来的运输层报文时,就能够根据其首部中的目的端口号把数据交付应用层的目的应用层。(两个进程之间进行通信不光要知道对方 IP 地址而且要知道对方的端口号(为了找到对方计算机中的应用进程))
6. 运输层用一个 16 位端口号标志一个端口。端口号只有本地意义,它只是为了标志计算机应用层中的各个进程在和运输层交互时的层间接口。在互联网的不同计算机中,相同的端口号是没有关联的。协议端口号简称端口。虽然通信的终点是应用进程,但只要把所发送的报文交到目的主机的某个合适端口,剩下的工作(最后交付目的进程)就由 TCP 和 UDP 来完成。
7. 运输层的端口号分为服务器端使用的端口号(0˜1023 指派给熟知端口,1024˜49151 是登记端口号)和客户端暂时使用的端口号(49152˜65535)
8. **UDP 的主要特点是 ① 无连接 ② 尽最大努力交付 ③ 面向报文 ④ 无拥塞控制 ⑤ 支持一对一,一对多,多对一和多对多的交互通信 ⑥ 首部开销小(只有四个字段:源端口,目的端口,长度和检验和)**
@@ -240,7 +254,7 @@ tag:
11. 停止等待协议是为了实现可靠传输的,它的基本原理就是每发完一个分组就停止发送,等待对方确认。在收到确认后再发下一个分组。
12. 为了提高传输效率,发送方可以不使用低效率的停止等待协议,而是采用流水线传输。流水线传输就是发送方可连续发送多个分组,不必每发完一个分组就停下来等待对方确认。这样可使信道上一直有数据不间断的在传送。这种传输方式可以明显提高信道利用率。
13. 停止等待协议中超时重传是指只要超过一段时间仍然没有收到确认,就重传前面发送过的分组(认为刚才发送过的分组丢失了)。因此每发送完一个分组需要设置一个超时计时器,其重传时间应比数据在分组传输的平均往返时间更长一些。这种自动重传方式常称为自动重传请求 ARQ。另外在停止等待协议中若收到重复分组,就丢弃该分组,但同时还要发送确认。连续 ARQ 协议可提高信道利用率。发送维持一个发送窗口,凡位于发送窗口内的分组可连续发送出去,而不需要等待对方确认。接收方一般采用累积确认,对按序到达的最后一个分组发送确认,表明到这个分组位置的所有分组都已经正确收到了。
-14. TCP 报文段的前 20 个字节是固定的,其后有 40 字节长度的可选字段。如果加入可选字段后首部长度不是 4 的整数倍字节,需要在再在之后用 0 填充。因此,TCP 首部的长度取值为 20+4n 字节,最长为 60 字节。
+14. TCP 报文段的前 20 个字节是固定的,其后有 40 字节长度的可选字段。如果加入可选字段后首部长度不是 4 的整数倍字节,需要在再在之后用 0 填充。因此,TCP 首部的长度取值为 20+4n 字节,最长为 60 字节。
15. **TCP 使用滑动窗口机制。发送窗口里面的序号表示允许发送的序号。发送窗口后沿的后面部分表示已发送且已收到确认,而发送窗口前沿的前面部分表示不允许发送。发送窗口后沿的变化情况有两种可能,即不动(没有收到新的确认)和前移(收到了新的确认)。发送窗口的前沿通常是不断向前移动的。一般来说,我们总是希望数据传输更快一些。但如果发送方把数据发送的过快,接收方就可能来不及接收,这就会造成数据的丢失。所谓流量控制就是让发送方的发送速率不要太快,要让接收方来得及接收。**
16. 在某段时间,若对网络中某一资源的需求超过了该资源所能提供的可用部分,网络的性能就要变坏。这种情况就叫拥塞。拥塞控制就是为了防止过多的数据注入到网络中,这样就可以使网络中的路由器或链路不致过载。拥塞控制所要做的都有一个前提,就是网络能够承受现有的网络负荷。拥塞控制是一个全局性的过程,涉及到所有的主机,所有的路由器,以及与降低网络传输性能有关的所有因素。相反,流量控制往往是点对点通信量的控制,是个端到端的问题。流量控制所要做到的就是抑制发送端发送数据的速率,以便使接收端来得及接收。
17. **为了进行拥塞控制,TCP 发送方要维持一个拥塞窗口 cwnd 的状态变量。拥塞控制窗口的大小取决于网络的拥塞程度,并且动态变化。发送方让自己的发送窗口取为拥塞窗口和接收方的接受窗口中较小的一个。**
@@ -265,46 +279,46 @@ tag:
### 6.1. 基本术语
-1. **域名系统(DNS)**:域名系统(DNS,Domain Name System)将人类可读的域名 (例如,www.baidu.com) 转换为机器可读的 IP 地址 (例如,220.181.38.148)。我们可以将其理解为专为互联网设计的电话薄。
+1. **域名系统(DNS)**:域名系统(DNS,Domain Name System)将人类可读的域名(例如,www.baidu.com)转换为机器可读的 IP 地址(例如,220.181.38.148)。我们可以将其理解为专为互联网设计的电话薄。
- 
+ 
https://www.seobility.net/en/wiki/HTTP_headers
-2. **文件传输协议(FTP)**:FTP 是 File Transfer Protocol(文件传输协议)的英文简称,而中文简称为“文传协议”。用于 Internet 上的控制文件的双向传输。同时,它也是一个应用程序(Application)。基于不同的操作系统有不同的 FTP 应用程序,而所有这些应用程序都遵守同一种协议以传输文件。在 FTP 的使用当中,用户经常遇到两个概念:"下载"(Download)和"上传"(Upload)。 "下载"文件就是从远程主机拷贝文件至自己的计算机上;"上传"文件就是将文件从自己的计算机中拷贝至远程主机上。用 Internet 语言来说,用户可通过客户机程序向(从)远程主机上传(下载)文件。
+2. **文件传输协议(FTP)**:FTP 是 File Transfer Protocol(文件传输协议)的英文简称,而中文简称为“文传协议”。用于 Internet 上的控制文件的双向传输。同时,它也是一个应用程序(Application)。基于不同的操作系统有不同的 FTP 应用程序,而所有这些应用程序都遵守同一种协议以传输文件。在 FTP 的使用当中,用户经常遇到两个概念:“下载”(Download)和“上传”(Upload)。 “下载”文件就是从远程主机拷贝文件至自己的计算机上;“上传”文件就是将文件从自己的计算机中拷贝至远程主机上。用 Internet 语言来说,用户可通过客户机程序向(从)远程主机上传(下载)文件。
3. **简单文件传输协议(TFTP)**:TFTP(Trivial File Transfer Protocol,简单文件传输协议)是 TCP/IP 协议族中的一个用来在客户机与服务器之间进行简单文件传输的协议,提供不复杂、开销不大的文件传输服务。端口号为 69。
4. **远程终端协议(TELNET)**:Telnet 协议是 TCP/IP 协议族中的一员,是 Internet 远程登陆服务的标准协议和主要方式。它为用户提供了在本地计算机上完成远程主机工作的能力。在终端使用者的电脑上使用 telnet 程序,用它连接到服务器。终端使用者可以在 telnet 程序中输入命令,这些命令会在服务器上运行,就像直接在服务器的控制台上输入一样。可以在本地就能控制服务器。要开始一个 telnet 会话,必须输入用户名和密码来登录服务器。Telnet 是常用的远程控制 Web 服务器的方法。
-5. **万维网(WWW)**:WWW 是环球信息网的缩写,(亦作“Web”、“WWW”、“'W3'”,英文全称为“World Wide Web”),中文名字为“万维网”,"环球网"等,常简称为 Web。分为 Web 客户端和 Web 服务器程序。WWW 可以让 Web 客户端(常用浏览器)访问浏览 Web 服务器上的页面。是一个由许多互相链接的超文本组成的系统,通过互联网访问。在这个系统中,每个有用的事物,称为一样“资源”;并且由一个全局“统一资源标识符”(URI)标识;这些资源通过超文本传输协议(Hypertext Transfer Protocol)传送给用户,而后者通过点击链接来获得资源。万维网联盟(英语:World Wide Web Consortium,简称 W3C),又称 W3C 理事会。1994 年 10 月在麻省理工学院(MIT)计算机科学实验室成立。万维网联盟的创建者是万维网的发明者蒂姆·伯纳斯-李。万维网并不等同互联网,万维网只是互联网所能提供的服务其中之一,是靠着互联网运行的一项服务。
+5. **万维网(WWW)**:WWW 是环球信息网的缩写,(亦作“Web”、“WWW”、“'W3'”,英文全称为“World Wide Web”),中文名字为“万维网”,“环球网”等,常简称为 Web。分为 Web 客户端和 Web 服务器程序。WWW 可以让 Web 客户端(常用浏览器)访问浏览 Web 服务器上的页面。是一个由许多互相链接的超文本组成的系统,通过互联网访问。在这个系统中,每个有用的事物,称为一样“资源”;并且由一个全局“统一资源标识符”(URI)标识;这些资源通过超文本传输协议(Hypertext Transfer Protocol)传送给用户,而后者通过点击链接来获得资源。万维网联盟(英语:World Wide Web Consortium,简称 W3C),又称 W3C 理事会。1994 年 10 月在麻省理工学院(MIT)计算机科学实验室成立。万维网联盟的创建者是万维网的发明者蒂姆·伯纳斯-李。万维网并不等同互联网,万维网只是互联网所能提供的服务其中之一,是靠着互联网运行的一项服务。
6. **万维网的大致工作工程:**
7. **统一资源定位符(URL)**:统一资源定位符是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。互联网上的每个文件都有一个唯一的 URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。
-8. **超文本传输协议(HTTP)**:超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议。所有的 WWW 文件都必须遵守这个标准。设计 HTTP 最初的目的是为了提供一种发布和接收 HTML 页面的方法。1960 年美国人 Ted Nelson 构思了一种通过计算机处理文本信息的方法,并称之为超文本(hypertext),这成为了 HTTP 超文本传输协议标准架构的发展根基。
+8. **超文本传输协议(HTTP)**:超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议。所有的 WWW 文件都必须遵守这个标准。设计 HTTP 最初的目的是为了提供一种发布和接收 HTML 页面的方法。1960 年美国人 Ted Nelson 构思了一种通过计算机处理文本信息的方法,并称之为超文本(hypertext),这成为了 HTTP 超文本传输协议标准架构的发展根基。
HTTP 协议的本质就是一种浏览器与服务器之间约定好的通信格式。HTTP 的原理如下图所示:
- 
+ 
-9. **代理服务器(Proxy Server)**:代理服务器(Proxy Server)是一种网络实体,它又称为万维网高速缓存。 代理服务器把最近的一些请求和响应暂存在本地磁盘中。当新请求到达时,若代理服务器发现这个请求与暂时存放的的请求相同,就返回暂存的响应,而不需要按 URL 的地址再次去互联网访问该资源。代理服务器可在客户端或服务器工作,也可以在中间系统工作。
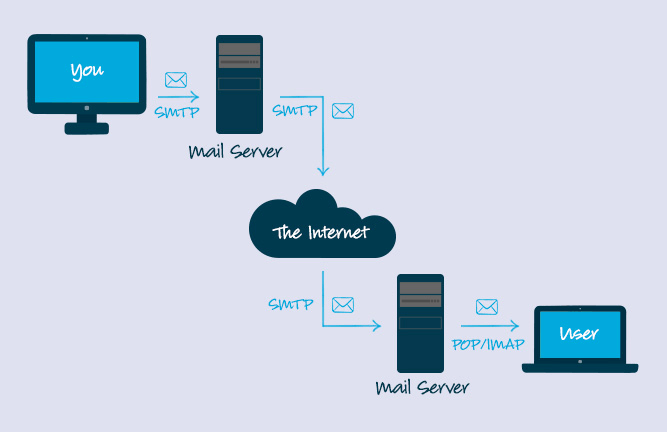
-10. **简单邮件传输协议(SMTP)** : SMTP(Simple Mail Transfer Protocol)即简单邮件传输协议,它是一组用于由源地址到目的地址传送邮件的规则,由它来控制信件的中转方式。 SMTP 协议属于 TCP/IP 协议簇,它帮助每台计算机在发送或中转信件时找到下一个目的地。 通过 SMTP 协议所指定的服务器,就可以把 E-mail 寄到收信人的服务器上了,整个过程只要几分钟。SMTP 服务器则是遵循 SMTP 协议的发送邮件服务器,用来发送或中转发出的电子邮件。
+9. **代理服务器(Proxy Server)**:代理服务器(Proxy Server)是一种网络实体,它又称为万维网高速缓存。代理服务器把最近的一些请求和响应暂存在本地磁盘中。当新请求到达时,若代理服务器发现这个请求与暂时存放的请求相同,就返回暂存的响应,而不需要按 URL 的地址再次去互联网访问该资源。代理服务器可在客户端或服务器工作,也可以在中间系统工作。
+10. **简单邮件传输协议(SMTP)**:SMTP(Simple Mail Transfer Protocol)即简单邮件传输协议,它是一组用于由源地址到目的地址传送邮件的规则,由它来控制信件的中转方式。SMTP 协议属于 TCP/IP 协议簇,它帮助每台计算机在发送或中转信件时找到下一个目的地。通过 SMTP 协议所指定的服务器,就可以把 E-mail 寄到收信人的服务器上了,整个过程只要几分钟。SMTP 服务器则是遵循 SMTP 协议的发送邮件服务器,用来发送或中转发出的电子邮件。
https://www.campaignmonitor.com/resources/knowledge-base/what-is-the-code-that-makes-bcc-or-cc-operate-in-an-email/
-11. **搜索引擎** :搜索引擎(Search Engine)是指根据一定的策略、运用特定的计算机程序从互联网上搜集信息,在对信息进行组织和处理后,为用户提供检索服务,将用户检索相关的信息展示给用户的系统。搜索引擎包括全文索引、目录索引、元搜索引擎、垂直搜索引擎、集合式搜索引擎、门户搜索引擎与免费链接列表等。
+11. **搜索引擎**:搜索引擎(Search Engine)是指根据一定的策略、运用特定的计算机程序从互联网上搜集信息,在对信息进行组织和处理后,为用户提供检索服务,将用户检索相关的信息展示给用户的系统。搜索引擎包括全文索引、目录索引、元搜索引擎、垂直搜索引擎、集合式搜索引擎、门户搜索引擎与免费链接列表等。
12. **垂直搜索引擎**:垂直搜索引擎是针对某一个行业的专业搜索引擎,是搜索引擎的细分和延伸,是对网页库中的某类专门的信息进行一次整合,定向分字段抽取出需要的数据进行处理后再以某种形式返回给用户。垂直搜索是相对通用搜索引擎的信息量大、查询不准确、深度不够等提出来的新的搜索引擎服务模式,通过针对某一特定领域、某一特定人群或某一特定需求提供的有一定价值的信息和相关服务。其特点就是“专、精、深”,且具有行业色彩,相比较通用搜索引擎的海量信息无序化,垂直搜索引擎则显得更加专注、具体和深入。
13. **全文索引** :全文索引技术是目前搜索引擎的关键技术。试想在 1M 大小的文件中搜索一个词,可能需要几秒,在 100M 的文件中可能需要几十秒,如果在更大的文件中搜索那么就需要更大的系统开销,这样的开销是不现实的。所以在这样的矛盾下出现了全文索引技术,有时候有人叫倒排文档技术。
-14. **目录索引**:目录索引( search index/directory),顾名思义就是将网站分门别类地存放在相应的目录中,因此用户在查询信息时,可选择关键词搜索,也可按分类目录逐层查找。
+14. **目录索引**:目录索引(search index/directory),顾名思义就是将网站分门别类地存放在相应的目录中,因此用户在查询信息时,可选择关键词搜索,也可按分类目录逐层查找。
### 6.2. 重要知识点总结
-1. 文件传输协议(FTP)使用 TCP 可靠的运输服务。FTP 使用客户服务器方式。一个 FTP 服务器进程可以同时为多个用户提供服务。在进行文件传输时,FTP 的客户和服务器之间要先建立两个并行的 TCP 连接:控制连接和数据连接。实际用于传输文件的是数据连接。
+1. 文件传输协议(FTP)使用 TCP 可靠的运输服务。FTP 使用客户服务器方式。一个 FTP 服务器进程可以同时为多个用户提供服务。在进行文件传输时,FTP 的客户和服务器之间要先建立两个并行的 TCP 连接:控制连接和数据连接。实际用于传输文件的是数据连接。
2. 万维网客户程序与服务器之间进行交互使用的协议是超文本传输协议 HTTP。HTTP 使用 TCP 连接进行可靠传输。但 HTTP 本身是无连接、无状态的。HTTP/1.1 协议使用了持续连接(分为非流水线方式和流水线方式)
3. 电子邮件把邮件发送到收件人使用的邮件服务器,并放在其中的收件人邮箱中,收件人可随时上网到自己使用的邮件服务器读取,相当于电子邮箱。
4. 一个电子邮件系统有三个重要组成构件:用户代理、邮件服务器、邮件协议(包括邮件发送协议,如 SMTP,和邮件读取协议,如 POP3 和 IMAP)。用户代理和邮件服务器都要运行这些协议。
diff --git a/docs/cs-basics/network/dns.md b/docs/cs-basics/network/dns.md
index 3d3ef0e2254..8ffb5832bad 100644
--- a/docs/cs-basics/network/dns.md
+++ b/docs/cs-basics/network/dns.md
@@ -1,30 +1,56 @@
---
title: DNS 域名系统详解(应用层)
+description: 详解 DNS 的层次结构与解析流程,覆盖递归/迭代、缓存与权威服务器,明确应用层端口与性能优化要点。
category: 计算机基础
tag:
- 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: DNS,域名解析,递归查询,迭代查询,缓存,权威DNS,端口53,UDP
---
-DNS(Domain Name System)域名管理系统,是当用户使用浏览器访问网址之后,使用的第一个重要协议。DNS 要解决的是**域名和 IP 地址的映射问题**。
+在浏览器地址栏输入域名之后,真正发起 HTTP 请求之前,通常要先经过 DNS 解析。
-
+DNS 要解决的是**域名和 IP 地址的映射问题**。它看起来只是“把域名翻译成 IP”,但背后涉及本地缓存、递归查询、迭代查询、权威服务器、根服务器、UDP/TCP 切换等一整套机制。
-在实际使用中,有一种情况下,浏览器是可以不必动用 DNS 就可以获知域名和 IP 地址的映射的。浏览器在本地会维护一个`hosts`列表,一般来说浏览器要先查看要访问的域名是否在`hosts`列表中,如果有的话,直接提取对应的 IP 地址记录,就好了。如果本地`hosts`列表内没有域名-IP 对应记录的话,那么 DNS 就闪亮登场了。
+这篇文章主要回答几个问题:
-目前 DNS 的设计采用的是分布式、层次数据库结构,**DNS 是应用层协议,基于 UDP 协议之上,端口为 53** 。
+1. DNS 为什么需要分层设计?
+2. 一次完整的域名解析通常会经过哪些步骤?
+3. 递归查询和迭代查询有什么区别?
+4. DNS 为什么通常基于 UDP,什么情况下会改用 TCP?
+
+
+
+在实际使用中,有一种情况下,浏览器是可以不必动用 DNS 就可以获知域名和 IP 地址的映射的。浏览器在本地会维护一个 `hosts` 列表,一般来说浏览器要先查看要访问的域名是否在 `hosts` 列表中,如果有的话,直接提取对应的 IP 地址记录,就好了。如果本地 `hosts` 列表内没有域名-IP 对应记录的话,那么 DNS 就闪亮登场了。
+
+目前 DNS 的设计采用的是分布式、层次数据库结构,**DNS 是应用层协议,通常基于 UDP 协议,端口为 53**。当响应数据超过 UDP 报文长度限制(512 字节,EDNS0 可扩展至更大)或进行区域传送(Zone Transfer)时,会改用 TCP 协议以保证数据完整性。
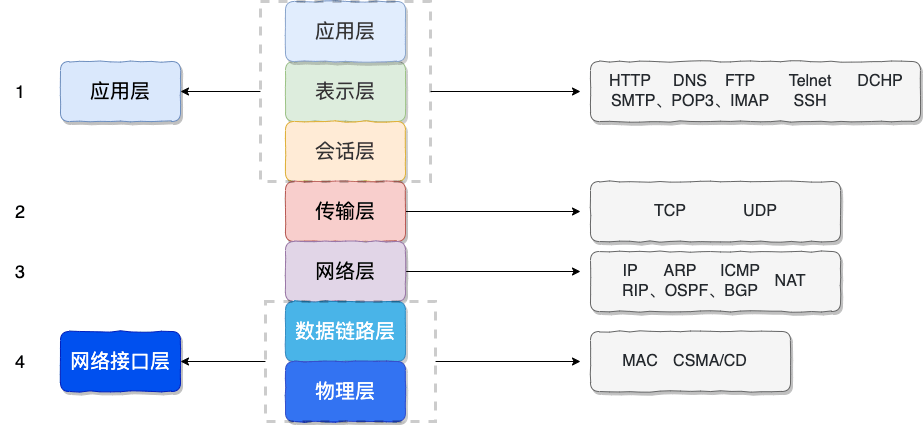
## DNS 服务器
-DNS 服务器自底向上可以依次分为以下几个层级(所有 DNS 服务器都属于以下四个类别之一):
+DNS 服务器自底向上可以依次分为以下几个层级(所有 DNS 服务器都属于以下四个类别之一):
- 根 DNS 服务器。根 DNS 服务器提供 TLD 服务器的 IP 地址。目前世界上只有 13 组根服务器,我国境内目前仍没有根服务器。
-- 顶级域 DNS 服务器(TLD 服务器)。顶级域是指域名的后缀,如`com`、`org`、`net`和`edu`等。国家也有自己的顶级域,如`uk`、`fr`和`ca`。TLD 服务器提供了权威 DNS 服务器的 IP 地址。
+- 顶级域 DNS 服务器(TLD 服务器)。顶级域是指域名的后缀,如 `com`、`org`、`net` 和 `edu` 等。国家也有自己的顶级域,如 `uk`、`fr` 和 `ca`。TLD 服务器提供了权威 DNS 服务器的 IP 地址。
- 权威 DNS 服务器。在因特网上具有公共可访问主机的每个组织机构必须提供公共可访问的 DNS 记录,这些记录将这些主机的名字映射为 IP 地址。
- 本地 DNS 服务器。每个 ISP(互联网服务提供商)都有一个自己的本地 DNS 服务器。当主机发出 DNS 请求时,该请求被发往本地 DNS 服务器,它起着代理的作用,并将该请求转发到 DNS 层次结构中。严格说来,不属于 DNS 层级结构。
-世界上并不是只有 13 台根服务器,这是很多人普遍的误解,网上很多文章也是这么写的。实际上,现在根服务器数量远远超过这个数量。最初确实是为 DNS 根服务器分配了 13 个 IP 地址,每个 IP 地址对应一个不同的根 DNS 服务器。然而,由于互联网的快速发展和增长,这个原始的架构变得不太适应当前的需求。为了提高 DNS 的可靠性、安全性和性能,目前这 13 个 IP 地址中的每一个都有多个服务器,截止到 2023 年底,所有根服务器之和达到了 600 多台,未来还会继续增加。
+**世界上真的只有 13 台根服务器吗?** 这是一个流传已久的技术误解。如果你在网上搜索,仍能看到许多陈旧文章宣称“全球仅有 13 台根服务器,且全部由美国控制”。
+
+**事实并非如此。**
+
+最初在设计 DNS(域名系统)架构时,受限于早期 IPv4 数据包的大小限制(UDP 报文需控制在 512 字节以内),预留给根服务器地址的空间确实只够容纳 13 个 IP 地址,每个 IP 地址对应一个不同的根 DNS 服务器。这 13 个地址分别被命名为 `a.root-servers.net` 到 `m.root-servers.net`。
+
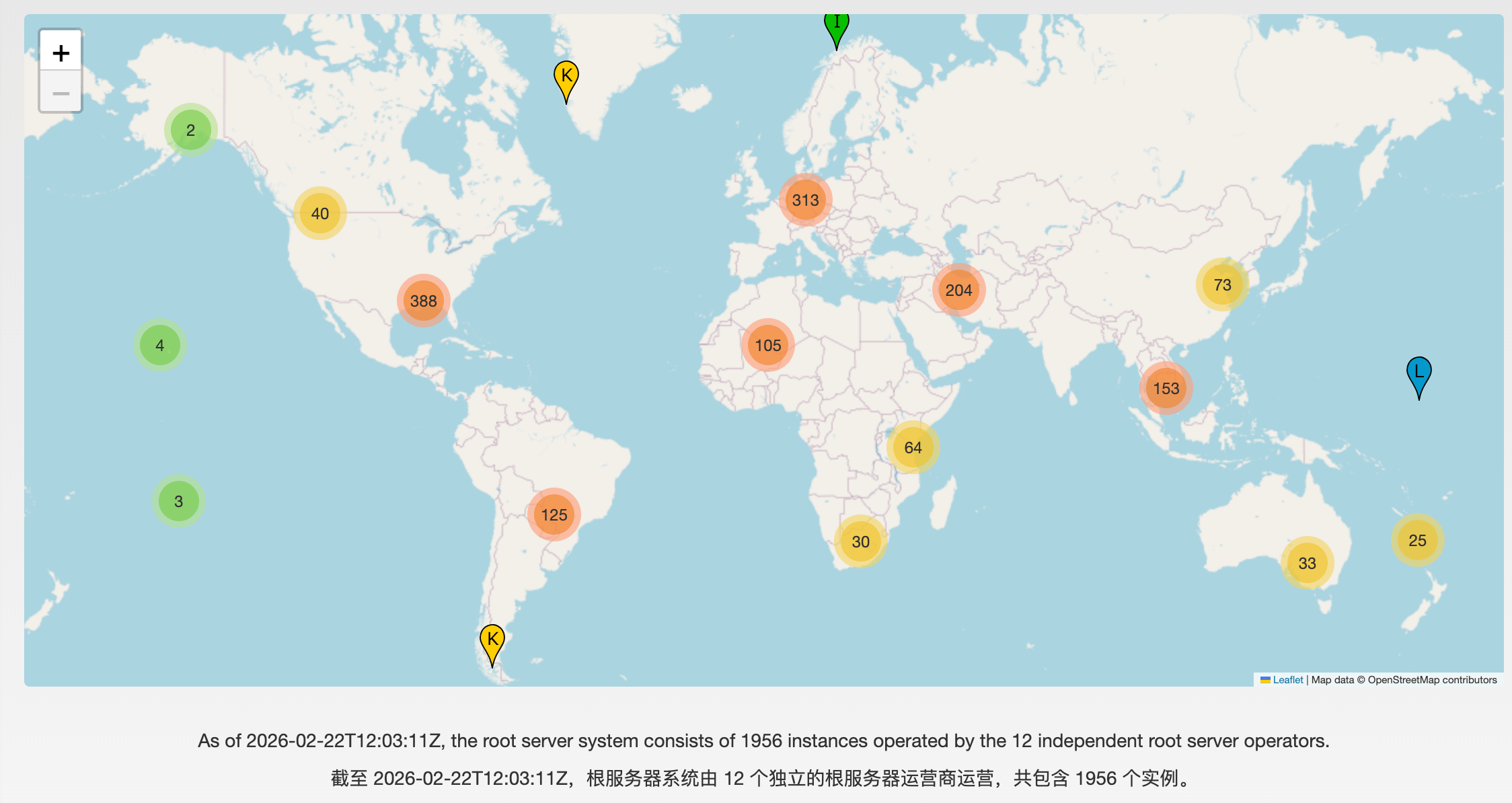
+虽然**逻辑上**只有 13 个 IP 地址,但随着互联网规模的爆发,物理上的“单一服务器”早已无法承载全球的查询压力。为了提升 DNS 的可靠性、安全性和响应速度,技术人员引入了 **IP 任播(Anycast)** 技术。
+
+通过任播技术,每一个逻辑 IP 地址背后都可以对应成百上千台分布在全球各地的物理服务器。当你发起查询请求时,互联网路由协议(BGP)会自动将请求引导至地理位置或网络路径上离你**最近**的那台物理实例。
+
+截止到 2023 年底,全球根服务器物理实例总数已超过 1700 台。根据 **[Root-Servers.org](https://root-servers.org/)** 的最新实时监测数据,到 **2026 年,全球根服务器物理实例已突破 1900+ 台**,并正向 2000 台大关迈进。
+
+
## DNS 工作流程
@@ -35,22 +61,22 @@ DNS 服务器自底向上可以依次分为以下几个层级(所有 DNS 服务
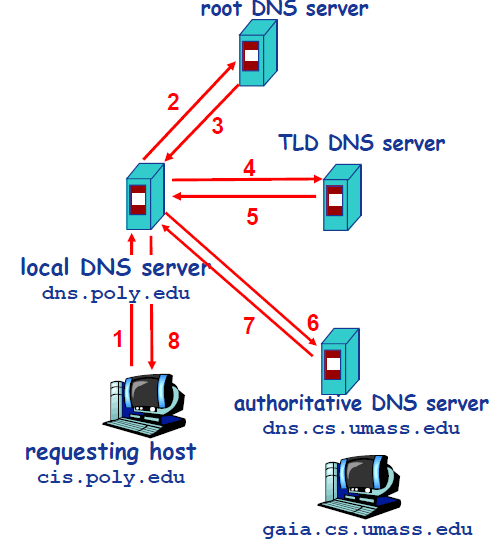
下图是实践中常采用的方式,从请求主机到本地 DNS 服务器的查询是递归的,其余的查询时迭代的。
-
+
-现在,主机`cis.poly.edu`想知道`gaia.cs.umass.edu`的 IP 地址。假设主机`cis.poly.edu`的本地 DNS 服务器为`dns.poly.edu`,并且`gaia.cs.umass.edu`的权威 DNS 服务器为`dns.cs.umass.edu`。
+现在,主机 `cis.poly.edu` 想知道 `gaia.cs.umass.edu` 的 IP 地址。假设主机 `cis.poly.edu` 的本地 DNS 服务器为 `dns.poly.edu`,并且 `gaia.cs.umass.edu` 的权威 DNS 服务器为 `dns.cs.umass.edu`。
-1. 首先,主机`cis.poly.edu`向本地 DNS 服务器`dns.poly.edu`发送一个 DNS 请求,该查询报文包含被转换的域名`gaia.cs.umass.edu`。
-2. 本地 DNS 服务器`dns.poly.edu`检查本机缓存,发现并无记录,也不知道`gaia.cs.umass.edu`的 IP 地址该在何处,不得不向根服务器发送请求。
-3. 根服务器注意到请求报文中含有`edu`顶级域,因此告诉本地 DNS,你可以向`edu`的 TLD DNS 发送请求,因为目标域名的 IP 地址很可能在那里。
-4. 本地 DNS 获取到了`edu`的 TLD DNS 服务器地址,向其发送请求,询问`gaia.cs.umass.edu`的 IP 地址。
-5. `edu`的 TLD DNS 服务器仍不清楚请求域名的 IP 地址,但是它注意到该域名有`umass.edu`前缀,因此返回告知本地 DNS,`umass.edu`的权威服务器可能记录了目标域名的 IP 地址。
-6. 这一次,本地 DNS 将请求发送给权威 DNS 服务器`dns.cs.umass.edu`。
-7. 终于,由于`gaia.cs.umass.edu`向权威 DNS 服务器备案过,在这里有它的 IP 地址记录,权威 DNS 成功地将 IP 地址返回给本地 DNS。
+1. 首先,主机 `cis.poly.edu` 向本地 DNS 服务器 `dns.poly.edu` 发送一个 DNS 请求,该查询报文包含被转换的域名 `gaia.cs.umass.edu`。
+2. 本地 DNS 服务器 `dns.poly.edu` 检查本机缓存,发现并无记录,也不知道 `gaia.cs.umass.edu` 的 IP 地址该在何处,不得不向根服务器发送请求。
+3. 根服务器注意到请求报文中含有 `edu` 顶级域,因此告诉本地 DNS,你可以向 `edu` 的 TLD DNS 发送请求,因为目标域名的 IP 地址很可能在那里。
+4. 本地 DNS 获取到了 `edu` 的 TLD DNS 服务器地址,向其发送请求,询问 `gaia.cs.umass.edu` 的 IP 地址。
+5. `edu` 的 TLD DNS 服务器仍不清楚请求域名的 IP 地址,但是它注意到该域名有 `umass.edu` 前缀,因此返回告知本地 DNS,`umass.edu` 的权威服务器可能记录了目标域名的 IP 地址。
+6. 这一次,本地 DNS 将请求发送给权威 DNS 服务器 `dns.cs.umass.edu`。
+7. 终于,由于 `gaia.cs.umass.edu` 向权威 DNS 服务器备案过,在这里有它的 IP 地址记录,权威 DNS 成功地将 IP 地址返回给本地 DNS。
8. 最后,本地 DNS 获取到了目标域名的 IP 地址,将其返回给请求主机。
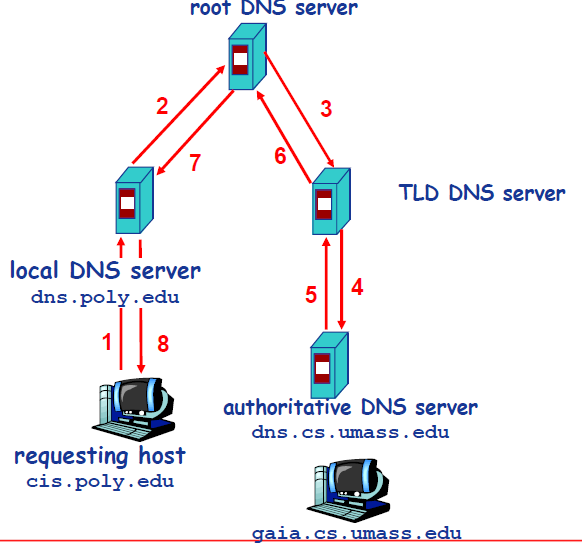
除了迭代式查询,还有一种递归式查询如下图,具体过程和上述类似,只是顺序有所不同。
-
+
另外,DNS 的缓存位于本地 DNS 服务器。由于全世界的根服务器甚少,只有 600 多台,分为 13 组,且顶级域的数量也在一个可数的范围内,因此本地 DNS 通常已经缓存了很多 TLD DNS 服务器,所以在实际查找过程中,无需访问根服务器。根服务器通常是被跳过的,不请求的。这样可以提高 DNS 查询的效率和速度,减少对根服务器和 TLD 服务器的负担。
@@ -58,12 +84,12 @@ DNS 服务器自底向上可以依次分为以下几个层级(所有 DNS 服务
DNS 的报文格式如下图所示:
-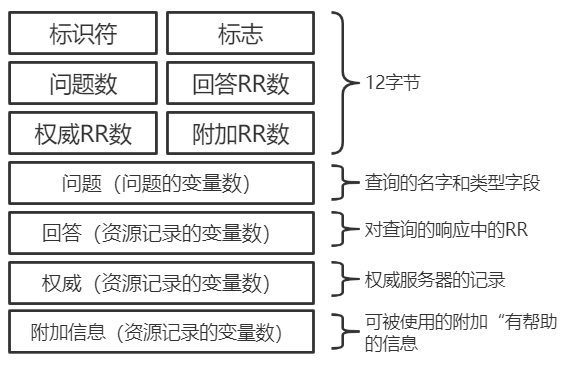
+
DNS 报文分为查询和回答报文,两种形式的报文结构相同。
- 标识符。16 比特,用于标识该查询。这个标识符会被复制到对查询的回答报文中,以便让客户用它来匹配发送的请求和接收到的回答。
-- 标志。1 比特的”查询/回答“标识位,`0`表示查询报文,`1`表示回答报文;1 比特的”权威的“标志位(当某 DNS 服务器是所请求名字的权威 DNS 服务器时,且是回答报文,使用”权威的“标志);1 比特的”希望递归“标志位,显式地要求执行递归查询;1 比特的”递归可用“标志位,用于回答报文中,表示 DNS 服务器支持递归查询。
+- 标志。1 比特的“查询/回答”标识位,`0` 表示查询报文,`1` 表示回答报文;1 比特的“权威的”标志位(当某 DNS 服务器是所请求名字的权威 DNS 服务器时,且是回答报文,使用“权威的”标志);1 比特的“希望递归”标志位,显式地要求执行递归查询;1 比特的“递归可用”标志位,用于回答报文中,表示 DNS 服务器支持递归查询。
- 问题数、回答 RR 数、权威 RR 数、附加 RR 数。分别指示了后面 4 类数据区域出现的数量。
- 问题区域。包含正在被查询的主机名字,以及正被询问的问题类型。
- 回答区域。包含了对最初请求的名字的资源记录。**在回答报文的回答区域中可以包含多条 RR,因此一个主机名能够有多个 IP 地址。**
@@ -72,23 +98,23 @@ DNS 报文分为查询和回答报文,两种形式的报文结构相同。
## DNS 记录
-DNS 服务器在响应查询时,需要查询自己的数据库,数据库中的条目被称为 **资源记录(Resource Record,RR)** 。RR 提供了主机名到 IP 地址的映射。RR 是一个包含了`Name`, `Value`, `Type`, `TTL`四个字段的四元组。
+DNS 服务器在响应查询时,需要查询自己的数据库,数据库中的条目被称为 **资源记录(Resource Record,RR)**。RR 提供了主机名到 IP 地址的映射。RR 是一个包含了 `Name`、`Value`、`Type`、`TTL` 四个字段的四元组。
-
+
-`TTL`是该记录的生存时间,它决定了资源记录应当从缓存中删除的时间。
+`TTL` 是该记录的生存时间,它决定了资源记录应当从缓存中删除的时间。
-`Name`和`Value`字段的取值取决于`Type`:
+`Name` 和 `Value` 字段的取值取决于 `Type`:
-
+
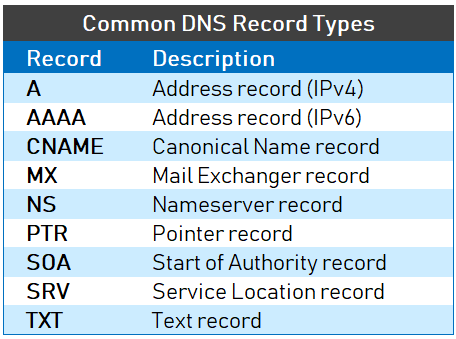
-- 如果`Type=A`,则`Name`是主机名信息,`Value` 是该主机名对应的 IP 地址。这样的 RR 记录了一条主机名到 IP 地址的映射。
-- 如果 `Type=AAAA` (与 `A` 记录非常相似),唯一的区别是 A 记录使用的是 IPv4,而 `AAAA` 记录使用的是 IPv6。
-- 如果`Type=CNAME` (Canonical Name Record,真实名称记录) ,则`Value`是别名为`Name`的主机对应的规范主机名。`Value`值才是规范主机名。`CNAME` 记录将一个主机名映射到另一个主机名。`CNAME` 记录用于为现有的 `A` 记录创建别名。下文有示例。
-- 如果`Type=NS`,则`Name`是个域,而`Value`是个知道如何获得该域中主机 IP 地址的权威 DNS 服务器的主机名。通常这样的 RR 是由 TLD 服务器发布的。
-- 如果`Type=MX` ,则`Value`是个别名为`Name`的邮件服务器的规范主机名。既然有了 `MX` 记录,那么邮件服务器可以和其他服务器使用相同的别名。为了获得邮件服务器的规范主机名,需要请求 `MX` 记录;为了获得其他服务器的规范主机名,需要请求 `CNAME` 记录。
+- 如果 `Type=A`,则 `Name` 是主机名信息,`Value` 是该主机名对应的 IP 地址。这样的 RR 记录了一条主机名到 IP 地址的映射。
+- 如果 `Type=AAAA`(与 `A` 记录非常相似),唯一的区别是 A 记录使用的是 IPv4,而 `AAAA` 记录使用的是 IPv6。
+- 如果 `Type=CNAME`(Canonical Name Record,真实名称记录),则 `Value` 是别名为 `Name` 的主机对应的规范主机名。`Value` 值才是规范主机名。`CNAME` 记录将一个主机名映射到另一个主机名。`CNAME` 记录用于为现有的 `A` 记录创建别名。下文有示例。
+- 如果 `Type=NS`,则 `Name` 是个域,而 `Value` 是个知道如何获得该域中主机 IP 地址的权威 DNS 服务器的主机名。通常这样的 RR 是由 TLD 服务器发布的。
+- 如果 `Type=MX`,则 `Value` 是个别名为 `Name` 的邮件服务器的规范主机名。既然有了 `MX` 记录,那么邮件服务器可以和其他服务器使用相同的别名。为了获得邮件服务器的规范主机名,需要请求 `MX` 记录;为了获得其他服务器的规范主机名,需要请求 `CNAME` 记录。
-`CNAME`记录总是指向另一则域名,而非 IP 地址。假设有下述 DNS zone:
+`CNAME` 记录总是指向另一则域名,而非 IP 地址。假设有下述 DNS zone:
```plain
NAME TYPE VALUE
diff --git a/docs/cs-basics/network/http-status-codes.md b/docs/cs-basics/network/http-status-codes.md
index 5550e06d5b8..0e3917b6d4a 100644
--- a/docs/cs-basics/network/http-status-codes.md
+++ b/docs/cs-basics/network/http-status-codes.md
@@ -1,11 +1,25 @@
---
title: HTTP 常见状态码总结(应用层)
+description: 汇总常见 HTTP 状态码含义与使用场景,强调 201/204 等易混淆点,提升接口设计与调试效率。
category: 计算机基础
tag:
- 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: HTTP 状态码,2xx,3xx,4xx,5xx,重定向,错误码,201 Created,204 No Content
---
-HTTP 状态码用于描述 HTTP 请求的结果,比如 2xx 就代表请求被成功处理。
+HTTP 状态码是服务端返回给客户端的处理结果摘要。看到一个状态码,基本就能判断请求是成功、重定向、客户端出错,还是服务端出错。
+
+状态码看起来只是数字,但很多码很容易混淆:比如 301 和 302、401 和 403、500 和 502、201 和 204。
+
+这篇文章主要回答几个问题:
+
+1. 1xx、2xx、3xx、4xx、5xx 分别代表什么类型的结果?
+2. 常见成功状态码如 200、201、204 有什么区别?
+3. 常见客户端错误如 400、401、403、404 应该怎么理解?
+4. 常见服务端错误如 500、502、503、504 通常意味着什么?
@@ -22,7 +36,7 @@ HTTP 状态码用于描述 HTTP 请求的结果,比如 2xx 就代表请求被
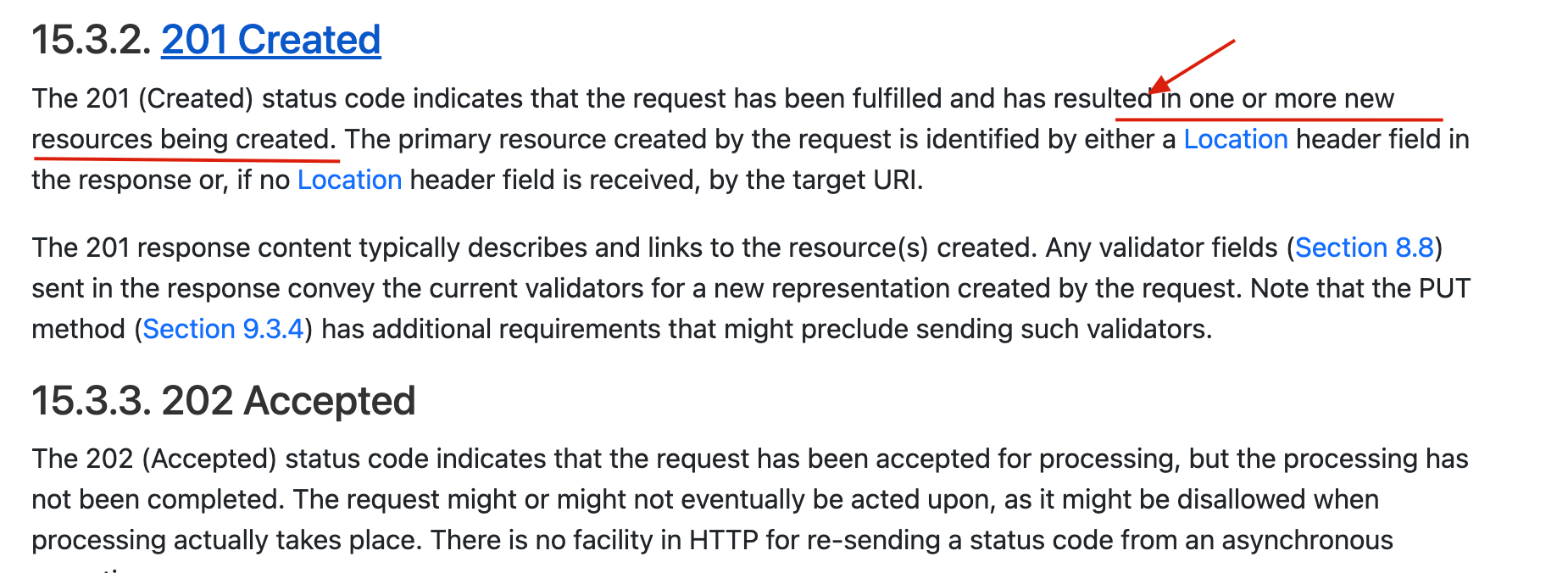
🐛 修正(参见:[issue#2458](https://github.com/Snailclimb/JavaGuide/issues/2458)):201 Created 状态码更准确点来说是创建一个或多个新的资源,可以参考:。
-
+
这里格外提一下 204 状态码,平时学习/工作中见到的次数并不多。
diff --git a/docs/cs-basics/network/http-vs-https.md b/docs/cs-basics/network/http-vs-https.md
index 71c224f1be4..7e6a521371f 100644
--- a/docs/cs-basics/network/http-vs-https.md
+++ b/docs/cs-basics/network/http-vs-https.md
@@ -1,10 +1,26 @@
---
-title: HTTP vs HTTPS(应用层)
+title: HTTP vs HTTPS:区别在哪里、HTTPS 为什么更安全(应用层)
+description: 对比 HTTP 与 HTTPS 的协议与安全机制,解析 SSL/TLS 工作原理与握手流程,明确应用层安全落地细节。
category: 计算机基础
tag:
- 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: HTTP,HTTPS,SSL,TLS,加密,认证,端口,安全性,握手流程
---
+HTTP 能传输网页内容,但默认是明文传输。请求和响应如果在网络中被监听、篡改或冒充,HTTP 本身没有足够的保护能力。
+
+HTTPS 不是一个全新的应用层协议,而是在 HTTP 和 TCP 之间加入 TLS/SSL,用加密、身份认证和完整性校验来保护通信过程。
+
+这篇文章主要回答几个问题:
+
+1. HTTP 和 HTTPS 的核心区别是什么?
+2. HTTPS 如何防止窃听、篡改和冒充?
+3. SSL/TLS 握手大致做了哪些事情?
+4. 为什么使用 HTTPS 后,证书、混合内容和性能优化仍然需要关注?
+
## HTTP 协议
### HTTP 协议介绍
@@ -13,9 +29,11 @@ HTTP 协议,全称超文本传输协议(Hypertext Transfer Protocol)。顾
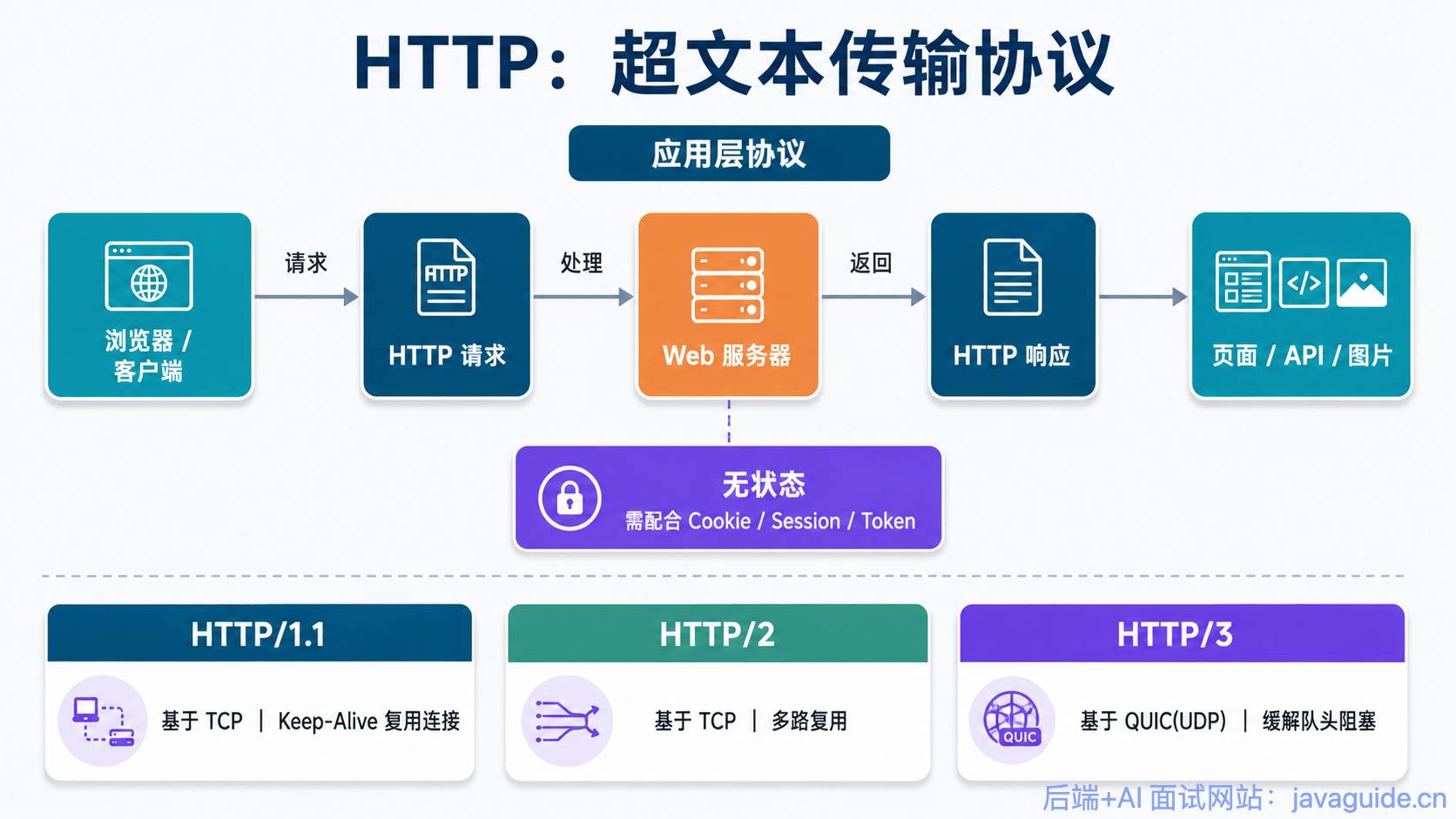
并且,HTTP 是一个无状态(stateless)协议,也就是说服务器不维护任何有关客户端过去所发请求的消息。这其实是一种懒政,有状态协议会更加复杂,需要维护状态(历史信息),而且如果客户或服务器失效,会产生状态的不一致,解决这种不一致的代价更高。
+
+
### HTTP 协议通信过程
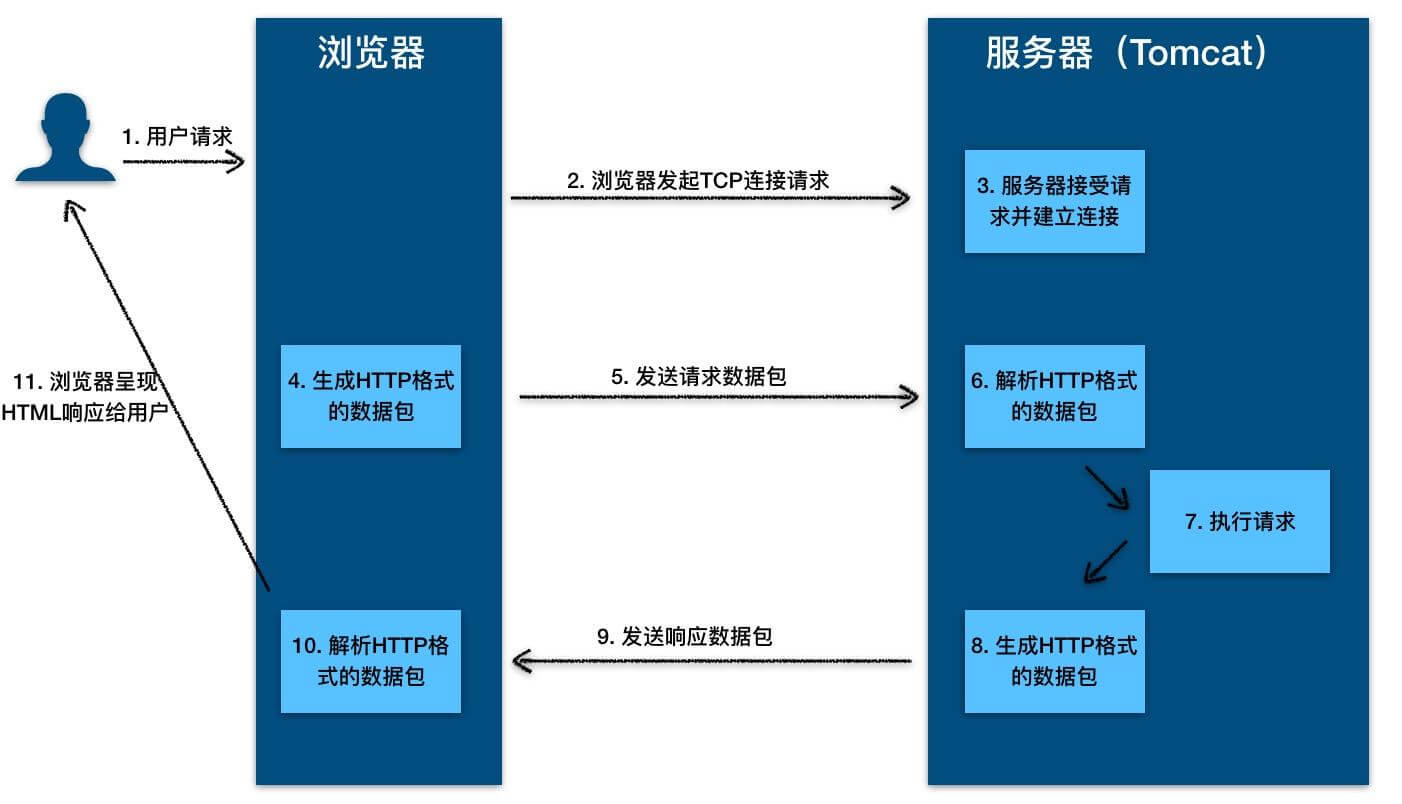
-HTTP 是应用层协议,它以 TCP(传输层)作为底层协议,默认端口为 80. 通信过程主要如下:
+HTTP 是应用层协议,它以 TCP(传输层)作为底层协议,默认端口为 80。通信过程主要如下:
1. 服务器在 80 端口等待客户的请求。
2. 浏览器发起到服务器的 TCP 连接(创建套接字 Socket)。
@@ -31,9 +49,9 @@ HTTP 是应用层协议,它以 TCP(传输层)作为底层协议,默认
### HTTPS 协议介绍
-HTTPS 协议(Hyper Text Transfer Protocol Secure),是 HTTP 的加强安全版本。HTTPS 是基于 HTTP 的,也是用 TCP 作为底层协议,并额外使用 SSL/TLS 协议用作加密和安全认证。默认端口号是 443.
+HTTPS 协议(Hyper Text Transfer Protocol Secure),是 HTTP 的加强安全版本。HTTPS 是基于 HTTP 的,也是用 TCP 作为底层协议,并额外使用 SSL/TLS 协议用作加密和安全认证。默认端口号是 443。
-HTTPS 协议中,SSL 通道通常使用基于密钥的加密算法,密钥长度通常是 40 比特或 128 比特。
+HTTPS 中,TLS 握手完成后,通信数据使用对称加密算法(如 AES-128-GCM 或 AES-256-GCM)保护,密钥通过非对称加密(如 RSA-2048/4096 或 ECDH)在握手阶段协商生成。早期 SSL 使用的 40 比特密钥因强度不足已被废弃,现代 TLS 要求对称密钥至少 128 比特。
### HTTPS 协议优点
@@ -41,19 +59,19 @@ HTTPS 协议中,SSL 通道通常使用基于密钥的加密算法,密钥长
## HTTPS 的核心—SSL/TLS 协议
-HTTPS 之所以能达到较高的安全性要求,就是结合了 SSL/TLS 和 TCP 协议,对通信数据进行加密,解决了 HTTP 数据透明的问题。接下来重点介绍一下 SSL/TLS 的工作原理。
+HTTPS 之所以能达到较高的安全性要求,就是结合 SSL/TLS 和 TCP 协议,对通信数据进行加密,解决了 HTTP 数据透明的问题。接下来重点介绍 SSL/TLS 的工作原理。
### SSL 和 TLS 的区别?
**SSL 和 TLS 没有太大的区别。**
-SSL 指安全套接字协议(Secure Sockets Layer),首次发布与 1996 年。SSL 的首次发布其实已经是他的 3.0 版本,SSL 1.0 从未面世,SSL 2.0 则具有较大的缺陷(DROWN 缺陷——Decrypting RSA with Obsolete and Weakened eNcryption)。很快,在 1999 年,SSL 3.0 进一步升级,**新版本被命名为 TLS 1.0**。因此,TLS 是基于 SSL 之上的,但由于习惯叫法,通常把 HTTPS 中的核心加密协议混称为 SSL/TLS。
+SSL 指安全套接层协议(Secure Sockets Layer),首次发布于 1996 年(SSL 3.0)。SSL 1.0 从未面世,SSL 2.0 则具有较大的缺陷(DROWN 缺陷——Decrypting RSA with Obsolete and Weakened eNcryption)。很快,在 1999 年,SSL 3.0 进一步升级,**新版本被命名为 TLS 1.0**。因此,TLS 是基于 SSL 之上的,但由于习惯叫法,通常把 HTTPS 中的核心加密协议混称为 SSL/TLS。目前 SSL 已完全废弃,TLS 1.2 和 TLS 1.3 是现代 HTTPS 的实际标准。
### SSL/TLS 的工作原理
#### 非对称加密
-SSL/TLS 的核心要素是**非对称加密**。非对称加密采用两个密钥——一个公钥,一个私钥。在通信时,私钥仅由解密者保存,公钥由任何一个想与解密者通信的发送者(加密者)所知。可以设想一个场景,
+SSL/TLS 的核心要素是**非对称加密**。非对称加密采用两个密钥:一个公钥,一个私钥。在通信时,私钥仅由解密者保存,公钥由任何一个想与解密者通信的发送者(加密者)所知。可以设想一个场景:
> 在某个自助邮局,每个通信信道都是一个邮箱,每一个邮箱所有者都在旁边立了一个牌子,上面挂着一把钥匙:这是我的公钥,发送者请将信件放入我的邮箱,并用公钥锁好。
>
@@ -61,7 +79,7 @@ SSL/TLS 的核心要素是**非对称加密**。非对称加密采用两个密
>
> 这样,通信信息就不会被其他人截获了,这依赖于私钥的保密性。
-
+
非对称加密的公钥和私钥需要采用一种复杂的数学机制生成(密码学认为,为了较高的安全性,尽量不要自己创造加密方案)。公私钥对的生成算法依赖于单向陷门函数。
@@ -81,13 +99,13 @@ SSL/TLS 的核心要素是**非对称加密**。非对称加密采用两个密
> 对称加密:通信双方共享唯一密钥 k,加解密算法已知,加密方利用密钥 k 加密,解密方利用密钥 k 解密,保密性依赖于密钥 k 的保密性。
-
+
-对称加密的密钥生成代价比公私钥对的生成代价低得多,那么有的人会问了,为什么 SSL/TLS 还需要使用非对称加密呢?因为对称加密的保密性完全依赖于密钥的保密性。在双方通信之前,需要商量一个用于对称加密的密钥。我们知道网络通信的信道是不安全的,传输报文对任何人是可见的,密钥的交换肯定不能直接在网络信道中传输。因此,使用非对称加密,对对称加密的密钥进行加密,保护该密钥不在网络信道中被窃听。这样,通信双方只需要一次非对称加密,交换对称加密的密钥,在之后的信息通信中,使用绝对安全的密钥,对信息进行对称加密,即可保证传输消息的保密性。
+对称加密的密钥生成代价比公私钥对的生成代价低得多。那么有的人会问:为什么 SSL/TLS 还需要使用非对称加密呢?因为对称加密的保密性完全依赖于密钥的保密性。在双方通信之前,需要商量一个用于对称加密的密钥。网络通信的信道是不安全的,传输报文对任何人是可见的,密钥的交换肯定不能直接在网络信道中传输。因此,使用非对称加密对对称加密的密钥进行加密,保护该密钥不在网络信道中被窃听。这样,通信双方只需要一次非对称加密,交换对称加密的密钥,在之后的信息通信中,使用绝对安全的密钥对信息进行对称加密,即可保证传输消息的保密性。
#### 公钥传输的信赖性
-SSL/TLS 介绍到这里,了解信息安全的朋友又会想到一个安全隐患,设想一个下面的场景:
+SSL/TLS 介绍到这里,了解信息安全的朋友又会想到一个安全隐患。设想下面的场景:
> 客户端 C 和服务器 S 想要使用 SSL/TLS 通信,由上述 SSL/TLS 通信原理,C 需要先知道 S 的公钥,而 S 公钥的唯一获取途径,就是把 S 公钥在网络信道中传输。要注意网络信道通信中有几个前提:
>
@@ -99,7 +117,7 @@ SSL/TLS 介绍到这里,了解信息安全的朋友又会想到一个安全隐
>
> 同样的,S 公钥即使做加密,也难以避免这种信任性问题,C 被 AS 拐跑了!
-
+
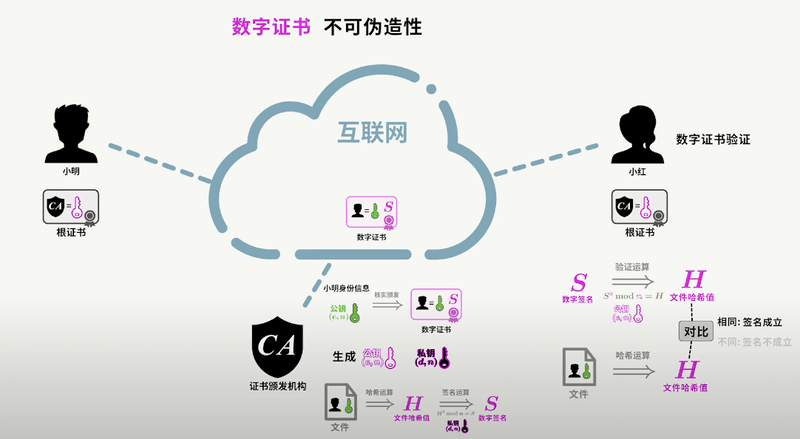
为了公钥传输的信赖性问题,第三方机构应运而生——证书颁发机构(CA,Certificate Authority)。CA 默认是受信任的第三方。CA 会给各个服务器颁发证书,证书存储在服务器上,并附有 CA 的**电子签名**(见下节)。
@@ -107,7 +125,7 @@ SSL/TLS 介绍到这里,了解信息安全的朋友又会想到一个安全隐
#### 数字签名
-好,到这一小节,已经是 SSL/TLS 的尾声了。上一小节提到了数字签名,数字签名要解决的问题,是防止证书被伪造。第三方信赖机构 CA 之所以能被信赖,就是 **靠数字签名技术** 。
+好,到这一小节,已经是 SSL/TLS 的尾声了。上一小节提到了数字签名,数字签名要解决的问题,是防止证书被伪造。第三方信赖机构 CA 之所以能被信赖,就是 **靠数字签名技术**。
数字签名,是 CA 在给服务器颁发证书时,使用散列+加密的组合技术,在证书上盖个章,以此来提供验伪的功能。具体行为如下:
@@ -117,7 +135,7 @@ SSL/TLS 介绍到这里,了解信息安全的朋友又会想到一个安全隐
>
> 客户端对证书数据(包含服务器的公钥)做相同的散列处理,得到摘要,并将该摘要与之前从签名中解码出的摘要做对比,如果相同,则身份验证成功;否则验证失败。
-
+
总结来说,带有证书的公钥传输机制如下:
@@ -127,11 +145,11 @@ SSL/TLS 介绍到这里,了解信息安全的朋友又会想到一个安全隐
4. C 获得 S 的证书,信任 CA 并知晓 CA 公钥,使用 CA 公钥对 S 证书上的签名解密,同时对消息进行散列处理,得到摘要。比较摘要,验证 S 证书的真实性。
5. 如果 C 验证 S 证书是真实的,则信任 S 的公钥(在 S 证书中)。
-
+
对于数字签名,我这里讲的比较简单,如果你没有搞清楚的话,强烈推荐你看看[数字签名及数字证书原理](https://www.bilibili.com/video/BV18N411X7ty/)这个视频,这是我看过最清晰的讲解。
-
+
## 总结
diff --git a/docs/cs-basics/network/http-vs-rpc.md b/docs/cs-basics/network/http-vs-rpc.md
new file mode 100644
index 00000000000..1bd17f4e80d
--- /dev/null
+++ b/docs/cs-basics/network/http-vs-rpc.md
@@ -0,0 +1,374 @@
+---
+title: 有了 HTTP 协议,为什么还要 RPC?HTTP 与 RPC 区别对比
+category: 计算机基础
+description: 深入对比 HTTP 与 RPC 的本质区别,解析微服务通信选型。涵盖序列化性能、连接复用、gRPC、RESTful、服务治理等核心知识点。
+head:
+ - - meta
+ - name: keywords
+ content: HTTP,RPC,HTTP vs RPC区别,微服务通信,RPC协议,TCP通信,序列化协议,RESTful,gRPC,Dubbo,Protobuf,服务调用,远程调用,HTTP协议,微服务选型
+---
+
+你好,我是小 G。在我大二下学期那年,看黑马的免费课程,第一次接触到 RPC,当时还是挺懵逼的。
+
+HTTP 接口不是已经能调了吗?
+
+前端调后端是 HTTP,服务端调服务端也可以用 HTTP。写一个 `/user/getById` 接口,传个用户 ID,返回用户信息,这不也能完成远程调用吗?
+
+那为什么还要再搞一个 RPC 增加学习成本呢?这不纯闹嘛!
+
+更容易让人混乱的是,很多文章特别喜欢把 HTTP 和 RPC 放在一起对比,好像它们是同一层的两个协议。看完之后你可能记住了几句话:**HTTP 面向资源,RPC 面向方法;HTTP 对外,RPC 对内;RPC 性能更好。**
+
+这些话不是完全错,但太粗了。
+
+真到项目里,你还是会遇到问题:**用 HTTP 行不行?用 RPC 是不是过度设计?gRPC 明明基于 HTTP/2,为什么又说它是 RPC?**
+
+这篇文章就围绕这个问题聊清楚。
+
+## RPC 不是某一个具体协议
+
+这是一个常见的误区,开始后面的文章之前,非常有必要先提一下。
+
+**HTTP 是协议。而 RPC 不是某一个具体协议,它更像是一种调用方式。**
+
+RPC 全称是 Remote Procedure Call,翻译过来就是远程过程调用。它想解决的问题很朴素:**让你调用远程服务时,尽量像调用本地方法一样。**
+
+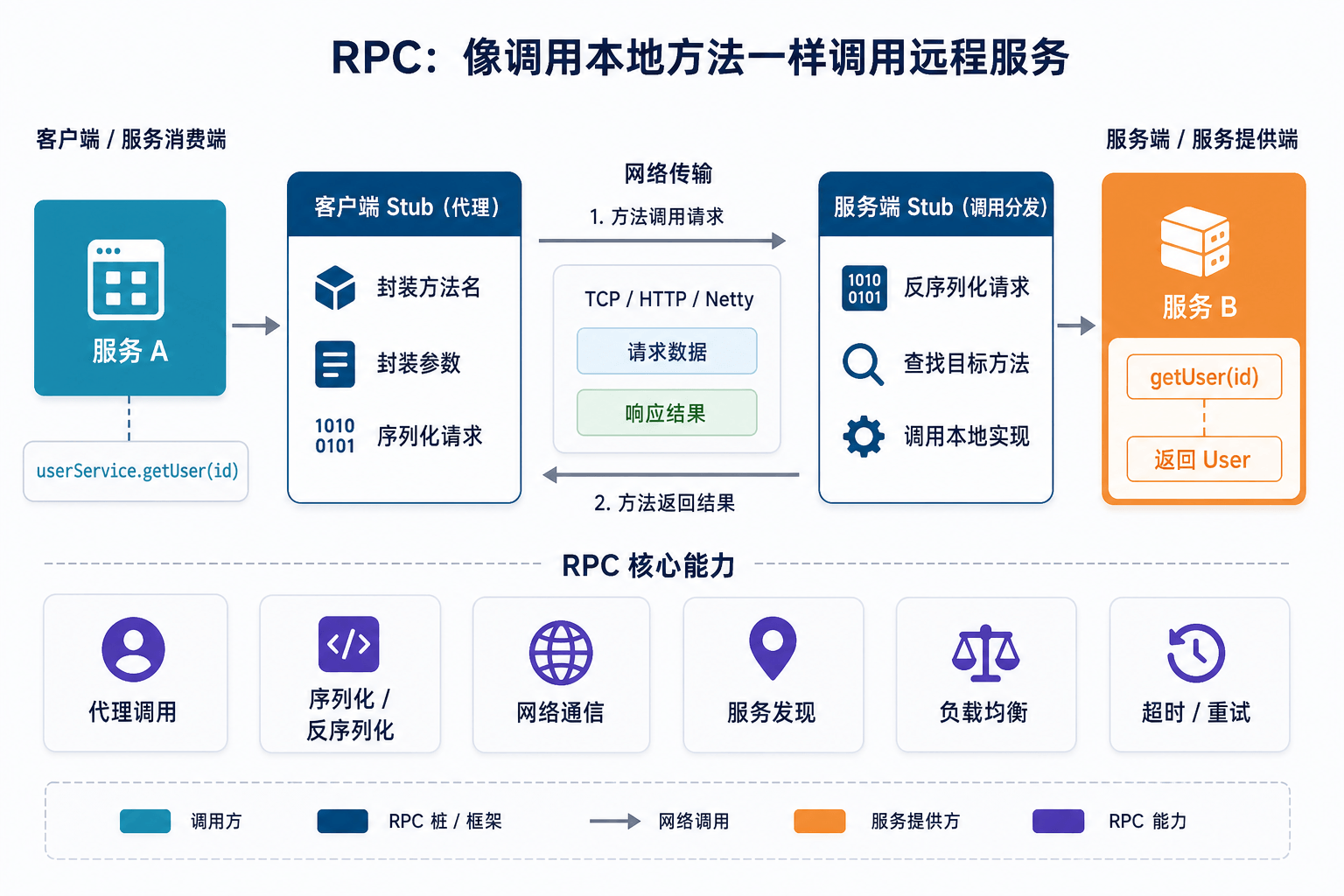
+
+比如本地代码里调用用户服务:
+
+```java
+User user = userService.getUser(1001);
+```
+
+如果 `userService` 就在当前进程里,这只是一次普通方法调用。
+
+但如果用户服务部署在另一台机器上,这件事就复杂了。你要发网络请求,要传方法名和参数,要序列化数据,要处理超时、失败、重试,还要拿到返回结果再反序列化。
+
+RPC 框架想做的事情,就是把这些麻烦尽量封装掉。调用方代码看起来还是:
+
+```java
+User user = userService.getUser(1001);
+```
+
+但底下已经完成了网络通信、序列化、服务寻址和结果返回。
+
+所以更准确的说法不是“HTTP 和 RPC 谁更强”,而是:
+
+**HTTP 是一种应用层协议,RPC 是一种远程调用模型。**
+
+
+
+具体到实现上,RPC 可以有很多种。Dubbo 是 RPC 框架,Thrift 是 RPC 框架,gRPC 也是 RPC 框架。gRPC 官方文档里也说得很直接:客户端可以像调用本地对象一样,调用另一台机器上服务端应用的方法;服务端定义可远程调用的方法以及参数和返回类型。
+
+
+
+这就解释了一个很容易绕晕的点:**gRPC 是 RPC,但它基于 HTTP/2。**
+
+它不是 HTTP 的反面,只是在 HTTP/2 之上提供 RPC 调用。
+
+gRPC 的 GitHub 上专门有一篇文章 [gRPC over HTTP2 基于 HTTP2 的 gRPC 协议](https://github.com/grpc/grpc/blob/master/doc/PROTOCOL-HTTP2.md) 详细介绍:
+
+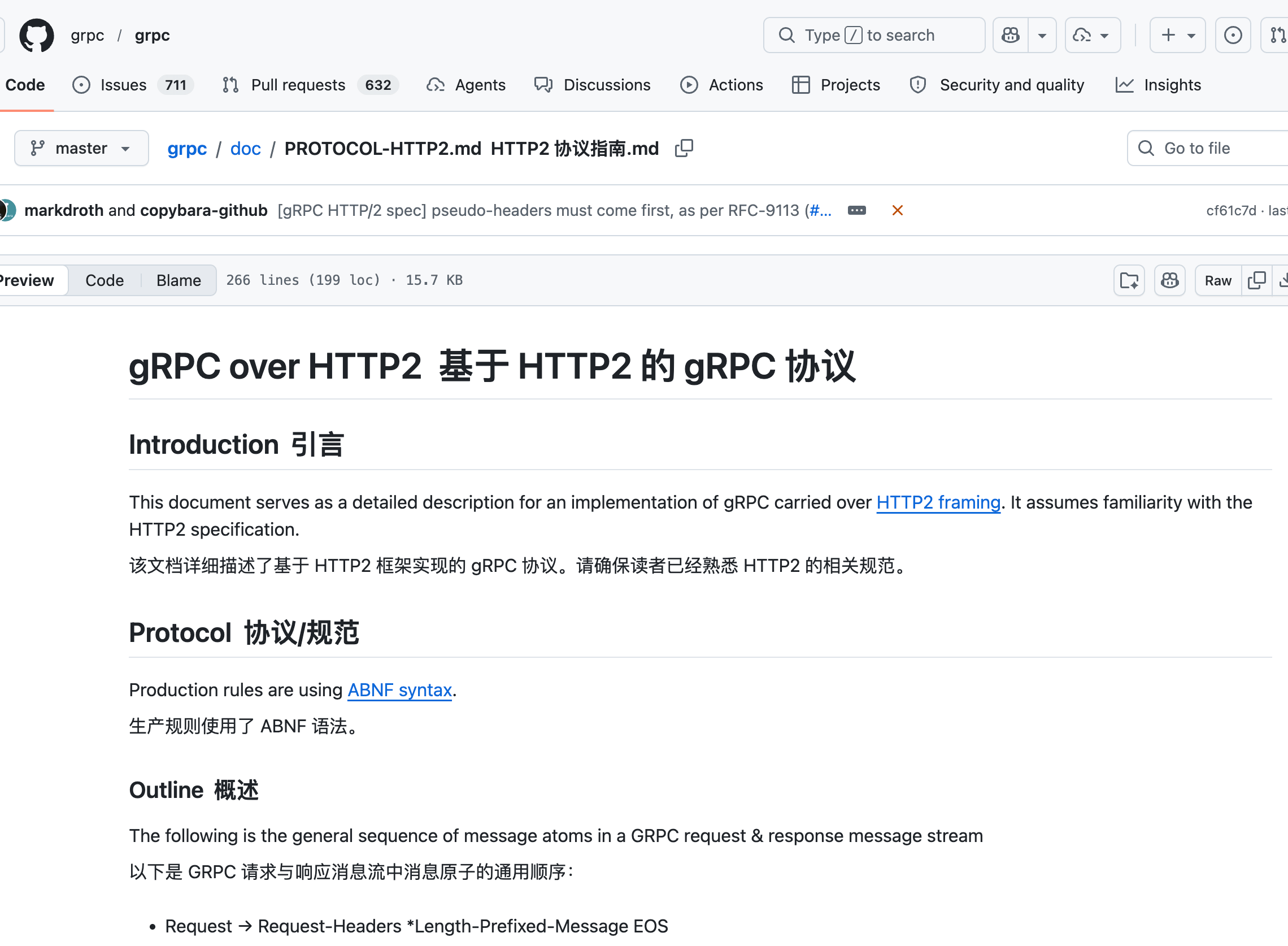
+
+## **光有 TCP 还不够**
+
+要理解 HTTP 和 RPC 的差别,最好先往下看一层。
+
+很多同学知道 HTTP 基于 TCP,RPC 也经常基于 TCP,于是会想:那我直接用 TCP 不就行了吗?
+
+理论上可以,实际很麻烦。
+
+TCP 负责的是可靠传输,它传的是一串连续的字节流。它不关心你的业务消息从哪里开始,到哪里结束。
+
+比如客户端连续发了两次请求:
+
+```text
+getUser:1001
+getOrder:8888
+```
+
+服务端收到的可能不是两段规规整整的消息,而是一段字节流。你必须自己判断:第一条消息在哪里结束,第二条消息从哪里开始。还要考虑半包、粘包、编码、超时、错误码、请求 ID 等问题。
+
+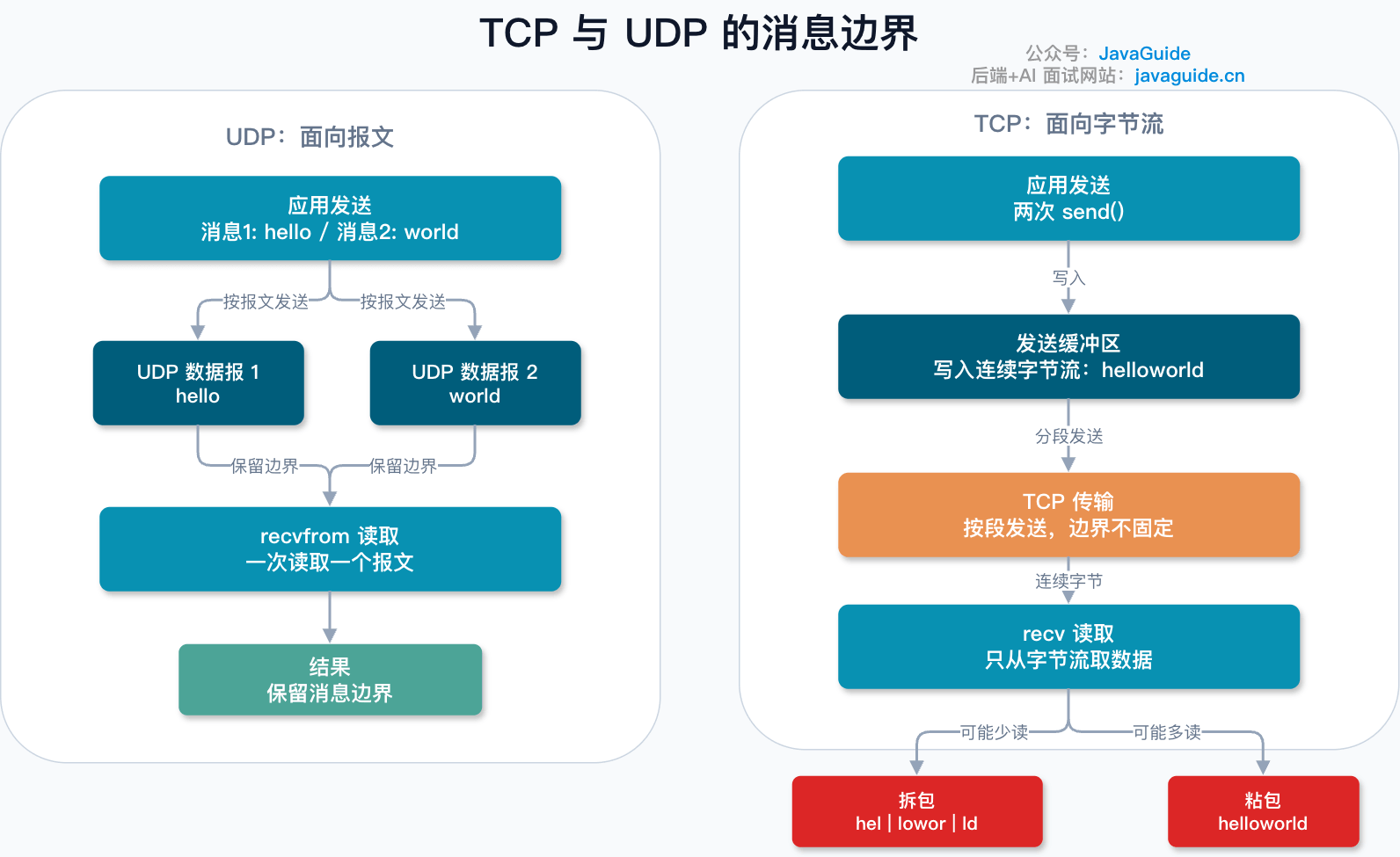
+
+这就是为什么应用层协议一定要定义消息格式。
+
+HTTP 定义了一套通用格式:请求行、Header、Body、状态码等。MDN 对 HTTP 的定义也很清楚:它是应用层协议,最初用于浏览器和 Web 服务器通信,但也可以用于机器之间通信和 API 访问。
+
+RPC 框架也会定义自己的消息格式。只不过它通常不会围绕 URL 和资源来设计,而是围绕服务、方法、参数和返回值来设计。
+
+说白了,HTTP 和 RPC 都在解决一个问题:
+
+**两个进程隔着网络,怎么把一次业务调用说清楚。**
+
+只是它们的建模方式不一样。
+
+## **HTTP 更像访问资源,RPC 更像调用方法**
+
+HTTP / REST 常见写法是这样的:
+
+```http
+GET /users/1001
+POST /orders
+PUT /orders/888/status
+DELETE /comments/9527
+```
+
+它的心智模型是资源。
+
+`/users/1001` 是一个用户资源,`GET` 表示读取它;`POST /orders` 表示创建订单;`PUT /orders/888/status` 表示修改订单状态。
+
+这种方式很适合对外开放 API。
+
+因为它通用、好理解、好调试。浏览器能访问,Postman 能调,curl 能测,网关也好处理。你给第三方提供接口时,让对方按 HTTP 文档接入,门槛比较低。
+
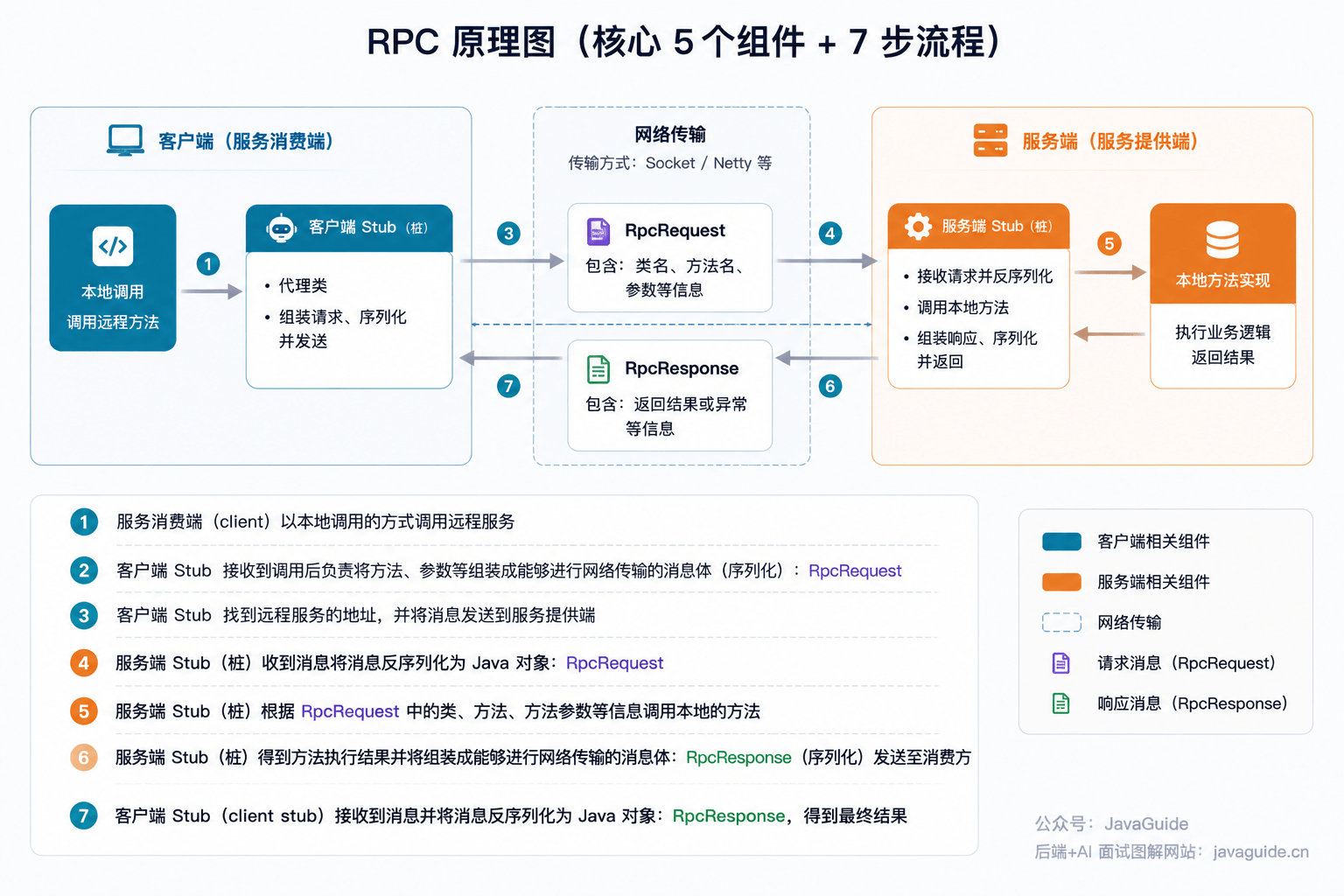
+RPC 的写法更像这样:
+
+```java
+userService.getUser(1001);
+orderService.createOrder(request);
+inventoryService.deductStock(skuId, count);
+```
+
+它的心智模型是方法调用。
+
+调用方更关心的是:我要调哪个服务?哪个方法?传什么参数?返回什么对象?
+
+
+
+这和 Java 后端平时写代码的习惯更接近。尤其是微服务内部调用时,服务和服务之间本来就是围绕业务方法协作,比如创建订单、扣库存、查询余额、校验权限。RPC 把这种调用关系表达得更直接。
+
+所以 HTTP 和 RPC 最大的区别,不是一个能不能调通,另一个能不能调通。
+
+两者都能调通。
+
+区别在于:**你是把远程交互建模成一次资源访问,还是一次方法调用。**
+
+## **公司内部为什么更常见 RPC?**
+
+HTTP 当然能做内部服务调用。
+
+很多公司内部服务全用 HTTP,也跑得好好的。尤其是服务规模不大、调用链不复杂的时候,HTTP 更简单。
+
+但服务数量上来之后,RPC 的优势会慢慢变明显。
+
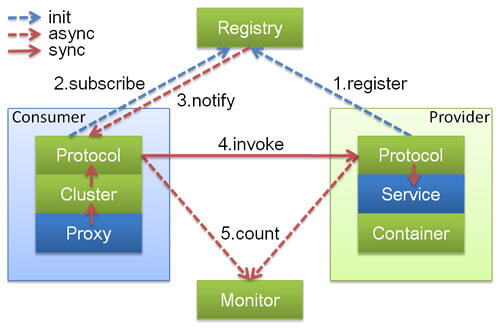
+**第一个明显变化是:调用方不想关心对方机器在哪。**
+
+你写业务代码的时候,最好只关心“我要调用用户服务”,而不是关心用户服务有几台机器、IP 是什么、哪台刚下线、哪台权重高。
+
+这就需要服务发现。
+
+Dubbo 官方文档里对服务发现的描述很典型:Provider 把地址注册到注册中心,Consumer 从注册中心读取并订阅地址列表,地址变化时注册中心通知消费者。Dubbo 支持 Nacos、Consul、ZooKeeper 等常见注册中心。
+
+
+
+这类能力当然也可以用 HTTP 做。你可以用注册中心、网关、负载均衡、SDK 自己拼一套。
+
+但 RPC 框架通常会把这些东西直接放进服务调用体系里。
+
+调用方写的是服务接口,底下自动完成服务发现、负载均衡、连接管理、超时控制。业务代码不用到处拼 URL。
+
+**第二个变化是:接口契约会变得更重要。**
+
+HTTP + JSON 很灵活,但灵活也意味着容易松散。
+
+字段名改了,类型改了,枚举值多了一个,调用方可能到运行时才炸。接口文档如果没及时更新,联调时就会很痛苦。
+
+RPC 框架通常会用更强的契约来约束双方。以 gRPC 为例,它常用 Protocol Buffers 作为接口定义语言和消息交换格式。Protocol Buffers 官方文档也说明,它是一种语言无关、平台无关、可扩展的结构化数据序列化机制,可以通过 `.proto` 定义结构并生成不同语言的代码。
+
+这带来的好处是,接口变更更容易被代码生成和编译阶段暴露出来。
+
+当然,契约强不代表不会出事故。
+
+字段怎么兼容,老版本客户端怎么处理,新字段能不能删,枚举能不能改,这些还是要认真设计。只是相比“大家约定一下 JSON 字段”,IDL 会更硬一点。
+
+**第三个变化是:高频内部调用会更在意机器处理效率。**
+
+HTTP + JSON 的好处是可读性强,人类看起来舒服。但机器处理时,它不是最省的方式。字段名、文本格式、解析成本,都会带来额外开销。
+
+RPC 框架常用二进制序列化,比如 Protobuf、Thrift。体积更小,解析也更适合机器处理。
+
+但这里不能说死。
+
+“RPC 一定比 HTTP 快”这句话不严谨。HTTP/2、连接复用、压缩、不同 JSON 库、不同网络环境,都会影响结果。gRPC 自己也基于 HTTP/2,它的优势并不是一句“不是 HTTP”就能解释完。
+
+更稳的说法是:
+
+**在高频服务互调场景里,RPC 框架通常会把序列化、连接复用、超时、重试、负载均衡、链路追踪这些能力做得更贴近内部服务调用。**
+
+这才是它在公司内部常见的原因。
+
+## **RPC 的价值不只是“调用快一点”**
+
+很多人讲 RPC,喜欢把重点放在性能上。
+
+性能当然重要,但我觉得 RPC 更大的价值是服务治理。
+
+一个内部调用真正上线后,不只是发请求、拿响应这么简单。你很快会遇到一堆问题:
+
+- 这个调用超时时间设多少?失败了要不要重试?重试会不会导致重复扣款?
+- 下游服务挂了,上游要不要降级?
+- 哪个接口最近错误率升高了?
+- 一次用户请求经过了几个服务?
+
+这些问题如果全靠业务代码处理,很快就会乱。
+
+RPC 框架通常会和治理能力绑在一起,比如超时控制、负载均衡、服务发现、熔断降级、链路追踪、调用统计等。gRPC 官方介绍里也提到,它支持负载均衡、Tracing、健康检查和认证等可插拔能力。
+
+HTTP 也能做这些。
+
+很多公司会用 API Gateway、服务网格、HTTP SDK、拦截器、链路追踪组件来补齐。做得好也没问题。
+
+所以不要把 RPC 理解成“比 HTTP 高级的东西”。它更像是把内部服务调用里常见的一堆问题,按“远程方法调用”这条路径整理了一遍。
+
+## **那 HTTP 就不适合内部调用吗?**
+
+并不是的哈。如果服务规模不大,团队人数也不多,反而用 HTTP 更省心。
+
+比如一个后台管理系统,拆了几个服务,调用频率也不高。你用 Spring Boot 写几个 REST 接口,配合 OpenAPI 文档、统一错误码、网关鉴权、日志追踪,完全够用。
+
+强上 RPC 可能还会带来额外成本,没意义。
+
+你要引入注册中心,要维护 IDL,要处理代码生成,要培训团队,还要解决本地调试和网关转发问题。服务没几个,调用链也不复杂的时候,这些成本不一定值得。
+
+HTTP 适合这些场景:
+
+- 对外开放 API,比如 Web、App、第三方合作方接入;
+- 团队更看重通用性和调试方便;
+- 服务调用频率不高;
+- 没有成熟 RPC 基础设施;
+- 已经有统一 HTTP 网关、SDK、限流、鉴权和监控体系。
+
+这里有个很简单的判断,分享给大家:
+
+**如果你的系统用 HTTP 已经稳定跑着,也没有明显的调用治理痛点,就没必要为了“微服务味更浓”换 RPC。**
+
+技术选型不是贴标签。
+
+能稳定解决问题更重要。
+
+## **gRPC 为什么容易把人绕晕?**
+
+gRPC 经常让人混乱,就是因为它同时踩在两个概念上。
+
+**一方面,它是 RPC 框架。**
+
+你定义服务和方法,生成客户端和服务端代码,然后像调用方法一样调用远程服务。
+
+**另一方面,它基于 HTTP/2 传输。**
+
+
+
+所以你不能把它简单理解成“HTTP 的对立面”。
+
+更准确地说: **gRPC 用 HTTP/2 做传输,默认使用 Protobuf 作为 IDL 和消息序列化格式,再用 RPC 模型组织调用。**
+
+这里要注意,Protobuf 是 gRPC 最常见的默认搭配,但不是 gRPC 的定义本身。gRPC 协议层允许 `application/grpc+proto`、`application/grpc+json` 或自定义编码。
+
+还有一点经常被忽略:正常 gRPC 响应里,HTTP 层通常是 `:status: 200`,真正的调用结果放在 HTTP/2 Trailers 里的 `grpc-status`、`grpc-message`。
+
+这会带来一个很实际的排查差异。
+
+看 HTTP 接口时,我们习惯先看 HTTP 状态码。`200` 基本代表请求成功,`404` 代表资源不存在,`500` 代表服务端异常。
+
+但看 gRPC 时,不能只看 HTTP 状态码。HTTP 是 200,不代表这次 RPC 业务调用一定成功,还要继续看 `grpc-status`。
+
+这也带来一个工程问题:网关、负载均衡、代理、Service Mesh 是否正确支持 HTTP/2 Trailers,会直接影响 gRPC 调用。如果链路里有组件处理不好 Trailers,问题会很隐蔽。
+
+所以,gRPC 不是“HTTP/2 + Protobuf”这么简单。
+
+HTTP 这一层,它跑在 HTTP/2 上。
+
+编码上,默认搭配 Protobuf,但协议允许其他编码。
+
+调用体验上,它让你像调本地方法一样调远程服务。
+
+状态返回上,它又用了 HTTP/2 Trailers 承载 RPC 调用结果。
+
+这些东西叠在一起,才是它容易把人绕晕的原因。
+
+## **真实选型时,别问哪个更高级**
+
+我更建议你按调用关系选:
+
+- 如果是浏览器、移动端、第三方系统调用,优先 HTTP。原因很简单:通用,接入成本低,调试工具多。对外接口最怕别人接不动。HTTP 在这方面优势太明显了。
+- 如果是公司内部微服务高频互调,可以考虑 RPC。尤其是服务数量多、接口数量多、调用链复杂,对超时、重试、注册发现、链路追踪、负载均衡要求都比较高的时候,RPC 框架会省掉很多重复工作。
+- 如果团队已经有成熟 HTTP 基础设施,也没必要强上 RPC。比如统一网关、服务发现、SDK、链路追踪、限流熔断都有了,大家也习惯用 HTTP,那继续用 HTTP 没问题。
+
+如果要用 gRPC,要提前想清楚几个问题:
+
+- 浏览器不能像后端服务一样直接使用标准 gRPC,通常需要 gRPC-Web 或代理层;
+- 网关和负载均衡是否支持;本地调试是不是方便;
+- 团队是否接受 `.proto` 和代码生成;
+- 线上排查时二进制消息是否会增加理解成本。
+
+gRPC 很强,但不是零成本。
+
+这点要提前说清楚。
+
+## 几个常见误解
+
+### HTTP 和 RPC 谁性能更好?
+
+不能一刀切。
+
+如果拿 HTTP/1.1 + JSON 去和基于 HTTP/2 + Protobuf 的 gRPC 比,在高频内部调用场景里,后者通常更省。
+
+但换个实现,结果就可能不一样。
+
+消息大小、序列化方式、连接复用、压缩、框架实现、网络环境都会影响结果。真正要比,应该拿你自己的接口、数据量和部署环境压测,而不是背一句“RPC 更快”。
+
+### RPC 是不是只能走 TCP?
+
+不是。
+
+RPC 是调用模型,不是传输协议。它可以基于 TCP,也可以基于 HTTP/2。gRPC 就是一个很典型的例子。
+
+### REST 和 RPC 是不是互斥?
+
+不完全互斥。
+
+REST 更偏资源建模,RPC 更偏方法调用。实际项目里经常混用:外部接口走 REST,内部服务走 RPC。这很正常。
+
+### 有了 HTTP/2,还需要 RPC 吗?
+
+HTTP/2 在 HTTP 这一层引入了帧、流、多路复用、头部压缩等能力,提高了同一条 TCP 连接上的并发利用率。
+
+但它不会自动帮你定义服务接口,不会自动生成客户端代码,也不会自动解决服务发现、超时重试、调用治理和版本契约。
+
+还有一个很容易被忽略的差异:调用模式。
+
+普通 HTTP API 大多是一问一答。gRPC 除了最常见的 Unary 调用,还原生支持服务端流、客户端流和双向流。gRPC 官方文档也明确列出了 Unary、Server streaming、Client streaming、Bidirectional streaming 这四种调用模式。
+
+比如日志订阅、长任务进度推送、批量上传、实时同步这类场景,用 streaming 会更自然。你当然也可以用 SSE、WebSocket,或者自己基于 HTTP/2 封装,但那就相当于又在补 RPC 框架已经做好的那部分能力。
+
+所以 HTTP/2 很重要,但它不是 RPC 框架的全部。
+
+### gRPC 是不是等于 HTTP/2 + Protobuf?
+
+不是。
+
+这句话只能用来帮助初学者快速建立印象,不能当严格定义。
+
+更准确的说法是:gRPC 基于 HTTP/2 承载 RPC 调用,默认使用 Protobuf 描述接口和消息,但协议本身允许 JSON 或自定义编码;同时,它还定义了请求路径、Content-Type、Length-Prefixed-Message、Trailers 里的 `grpc-status` 等一整套规则。
+
+所以 gRPC 不是单纯换了一个序列化格式,它是一套 RPC 调用协议和工程约定。
+
+## 最后
+
+HTTP 和 RPC 不是谁取代谁的关系,也不是谁更高级的问题。
+
+HTTP 能调服务,RPC 也能调服务。真正的区别在于,你是想把远程调用当成一次“资源访问”,还是当成一次“方法调用”。
+
+如果是对外接口,比如 Web、App、第三方系统接入,HTTP 通常更合适。它通用、好调试、接入成本低,别人拿 Postman、curl 就能测。
+如果是公司内部服务互调,尤其是服务多、调用链长、接口频繁调用,还要考虑服务发现、超时、重试、负载均衡、链路追踪这些问题,RPC 会更顺手一些。它不是单纯为了快,而是把内部服务调用里的很多麻烦事一起处理掉。
+
+所以,别再简单背“HTTP 对外,RPC 对内”了。
+
+这句话可以帮助入门,但真做项目时,还得看你的调用对象、团队基础设施、排查成本、性能要求和后续维护成本。
+
+系统规模不大,用 HTTP 已经跑得很稳,就别为了“看起来更微服务”强上 RPC。
+
+内部调用越来越复杂,HTTP SDK、网关、监控、重试这些东西越补越多,那就可以认真考虑 RPC。
+
+一句话:**HTTP 没那么弱,RPC 也没那么神。选哪个,主要看它能不能用更低成本解决你现在的问题。**
diff --git a/docs/cs-basics/network/http1.0-vs-http1.1.md b/docs/cs-basics/network/http1.0-vs-http1.1.md
index f0bb9850780..3ea333c64f0 100644
--- a/docs/cs-basics/network/http1.0-vs-http1.1.md
+++ b/docs/cs-basics/network/http1.0-vs-http1.1.md
@@ -1,17 +1,29 @@
---
-title: HTTP 1.0 vs HTTP 1.1(应用层)
+title: HTTP 1.0 vs HTTP 1.1:长连接、缓存、Host 头等核心差异(应用层)
+description: 细致对比 HTTP/1.0 与 HTTP/1.1 的协议差异,涵盖长连接、管道化、缓存与状态码增强等关键变更与实践影响。
category: 计算机基础
tag:
- 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: HTTP/1.0,HTTP/1.1,长连接,管道化,缓存,状态码,Host,带宽优化
---
-这篇文章会从下面几个维度来对比 HTTP 1.0 和 HTTP 1.1:
+HTTP/1.0 和 HTTP/1.1 名字只差一个小版本,但它们在连接复用、缓存、Host 头、状态码和带宽优化上都有明显差异。
-- 响应状态码
-- 缓存处理
-- 连接方式
-- Host 头处理
-- 带宽优化
+这些差异不是单纯的协议细节,它们直接影响浏览器如何发请求、服务器如何复用连接、缓存如何生效,以及虚拟主机如何工作。
+
+这篇文章主要回答几个问题:
+
+1. HTTP/1.1 相比 HTTP/1.0 新增了哪些常见状态码?
+2. HTTP/1.0 和 HTTP/1.1 的缓存机制有什么差异?
+3. HTTP/1.1 为什么默认支持长连接?
+4. Host 头和带宽优化分别解决了什么问题?
+
+开始之前,先简单回顾一下 HTTP 协议:
+
+
## 响应状态码
@@ -23,29 +35,29 @@ HTTP/1.0 仅定义了 16 种状态码。HTTP/1.1 中新加入了大量的状态
### HTTP/1.0
-HTTP/1.0 提供的缓存机制非常简单。服务器端使用`Expires`标签来标志(时间)一个响应体,在`Expires`标志时间内的请求,都会获得该响应体缓存。服务器端在初次返回给客户端的响应体中,有一个`Last-Modified`标签,该标签标记了被请求资源在服务器端的最后一次修改。在请求头中,使用`If-Modified-Since`标签,该标签标志一个时间,意为客户端向服务器进行问询:“该时间之后,我要请求的资源是否有被修改过?”通常情况下,请求头中的`If-Modified-Since`的值即为上一次获得该资源时,响应体中的`Last-Modified`的值。
+HTTP/1.0 提供的缓存机制非常简单。服务器端使用 `Expires` 标签来标志(时间)一个响应体,在 `Expires` 标志时间内的请求,都会获得该响应体缓存。服务器端在初次返回给客户端的响应体中,有一个 `Last-Modified` 标签,该标签标记了被请求资源在服务器端的最后一次修改。在请求头中,使用 `If-Modified-Since` 标签,该标签标志一个时间,意为客户端向服务器进行问询:“该时间之后,我要请求的资源是否有被修改过?”通常情况下,请求头中的 `If-Modified-Since` 的值即为上一次获得该资源时,响应体中的 `Last-Modified` 的值。
-如果服务器接收到了请求头,并判断`If-Modified-Since`时间后,资源确实没有修改过,则返回给客户端一个`304 not modified`响应头,表示”缓冲可用,你从浏览器里拿吧!”。
+如果服务器接收到了请求头,并判断 `If-Modified-Since` 时间后,资源确实没有修改过,则返回给客户端一个 `304 Not Modified` 响应头,表示“缓冲可用,你从浏览器里拿吧!”。
-如果服务器判断`If-Modified-Since`时间后,资源被修改过,则返回给客户端一个`200 OK`的响应体,并附带全新的资源内容,表示”你要的我已经改过的,给你一份新的”。
+如果服务器判断 `If-Modified-Since` 时间后,资源被修改过,则返回给客户端一个 `200 OK` 的响应体,并附带全新的资源内容,表示“你要的我已经改过的,给你一份新的”。
-
+
-
+
### HTTP/1.1
-HTTP/1.1 的缓存机制在 HTTP/1.0 的基础上,大大增加了灵活性和扩展性。基本工作原理和 HTTP/1.0 保持不变,而是增加了更多细致的特性。其中,请求头中最常见的特性就是`Cache-Control`,详见 MDN Web 文档 [Cache-Control](https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers/Cache-Control).
+HTTP/1.1 的缓存机制在 HTTP/1.0 的基础上,大大增加了灵活性和扩展性。基本工作原理和 HTTP/1.0 保持不变,而是增加了更多细致的特性。其中,请求头中最常见的特性就是 `Cache-Control`,详见 MDN Web 文档 [Cache-Control](https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers/Cache-Control)。
## 连接方式
-**HTTP/1.0 默认使用短连接** ,也就是说,客户端和服务器每进行一次 HTTP 操作,就建立一次连接,任务结束就中断连接。当客户端浏览器访问的某个 HTML 或其他类型的 Web 页中包含有其他的 Web 资源(如 JavaScript 文件、图像文件、CSS 文件等),每遇到这样一个 Web 资源,浏览器就会重新建立一个 TCP 连接,这样就会导致有大量的“握手报文”和“挥手报文”占用了带宽。
+**HTTP/1.0 默认使用短连接**,也就是说,客户端和服务器每进行一次 HTTP 操作,就建立一次连接,任务结束就中断连接。当客户端浏览器访问的某个 HTML 或其他类型的 Web 页中包含有其他的 Web 资源(如 JavaScript 文件、图像文件、CSS 文件等),每遇到这样一个 Web 资源,浏览器就会重新建立一个 TCP 连接,这样就会导致有大量的“握手报文”和“挥手报文”占用了带宽。
-**为了解决 HTTP/1.0 存在的资源浪费的问题, HTTP/1.1 优化为默认长连接模式 。** 采用长连接模式的请求报文会通知服务端:“我向你请求连接,并且连接成功建立后,请不要关闭”。因此,该 TCP 连接将持续打开,为后续的客户端-服务端的数据交互服务。也就是说在使用长连接的情况下,当一个网页打开完成后,客户端和服务器之间用于传输 HTTP 数据的 TCP 连接不会关闭,客户端再次访问这个服务器时,会继续使用这一条已经建立的连接。
+**为了解决 HTTP/1.0 存在的资源浪费的问题,HTTP/1.1 优化为默认长连接模式。** 采用长连接模式的请求报文会通知服务端:“我向你请求连接,并且连接成功建立后,请不要关闭”。因此,该 TCP 连接将持续打开,为后续的客户端-服务端的数据交互服务。也就是说在使用长连接的情况下,当一个网页打开完成后,客户端和服务器之间用于传输 HTTP 数据的 TCP 连接不会关闭,客户端再次访问这个服务器时,会继续使用这一条已经建立的连接。
-如果 TCP 连接一直保持的话也是对资源的浪费,因此,一些服务器软件(如 Apache)还会支持超时时间的时间。在超时时间之内没有新的请求达到,TCP 连接才会被关闭。
+如果 TCP 连接一直保持的话也是对资源的浪费,因此,一些服务器软件(如 Apache)还会支持超时时间选项。在超时时间之内没有新的请求到达,TCP 连接才会被关闭。
-有必要说明的是,HTTP/1.0 仍提供了长连接选项,即在请求头中加入`Connection: Keep-alive`。同样的,在 HTTP/1.1 中,如果不希望使用长连接选项,也可以在请求头中加入`Connection: close`,这样会通知服务器端:“我不需要长连接,连接成功后即可关闭”。
+有必要说明的是,HTTP/1.0 仍提供了长连接选项,即在请求头中加入 `Connection: Keep-Alive`。同样的,在 HTTP/1.1 中,如果不希望使用长连接选项,也可以在请求头中加入 `Connection: close`,这样会通知服务器端:“我不需要长连接,连接成功后即可关闭”。
**HTTP 协议的长连接和短连接,实质上是 TCP 协议的长连接和短连接。**
@@ -53,9 +65,9 @@ HTTP/1.1 的缓存机制在 HTTP/1.0 的基础上,大大增加了灵活性和
## Host 头处理
-域名系统(DNS)允许多个主机名绑定到同一个 IP 地址上,但是 HTTP/1.0 并没有考虑这个问题,假设我们有一个资源 URL 是 的请求报文中,将会请求的是`GET /home.html HTTP/1.0`.也就是不会加入主机名。这样的报文送到服务器端,服务器是理解不了客户端想请求的真正网址。
+域名系统(DNS)允许多个主机名绑定到同一个 IP 地址上,但是 HTTP/1.0 并没有考虑这个问题。假设我们有一个资源 URL 是 `http://example1.org/home.html`,HTTP/1.0 的请求报文中,将会请求的是 `GET /home.html HTTP/1.0`,也就是不会加入主机名。这样的报文送到服务器端,服务器是理解不了客户端想请求的真正网址。
-因此,HTTP/1.1 在请求头中加入了`Host`字段。加入`Host`字段的报文头部将会是:
+因此,HTTP/1.1 在请求头中加入了 `Host` 字段。加入 `Host` 字段的报文头部将会是:
```plain
GET /home.html HTTP/1.1
@@ -68,13 +80,13 @@ Host: example1.org
### 范围请求
-HTTP/1.1 引入了范围请求(range request)机制,以避免带宽的浪费。当客户端想请求一个文件的一部分,或者需要继续下载一个已经下载了部分但被终止的文件,HTTP/1.1 可以在请求中加入`Range`头部,以请求(并只能请求字节型数据)数据的一部分。服务器端可以忽略`Range`头部,也可以返回若干`Range`响应。
+HTTP/1.1 引入了范围请求(range request)机制,以避免带宽的浪费。当客户端想请求一个文件的一部分,或者需要继续下载一个已经下载了部分但被终止的文件,HTTP/1.1 可以在请求中加入 `Range` 头部,以请求(并只能请求字节型数据)数据的一部分。服务器端可以忽略 `Range` 头部,也可以返回若干 `Range` 响应。
`206 (Partial Content)` 状态码的主要作用是确保客户端和代理服务器能正确识别部分内容响应,避免将其误认为完整资源并错误地缓存。这对于正确处理范围请求和缓存管理非常重要。
一个典型的 HTTP/1.1 范围请求示例:
-```bash
+```http
# 获取一个文件的前 1024 个字节
GET /z4d4kWk.jpg HTTP/1.1
Host: i.imgur.com
@@ -83,8 +95,7 @@ Range: bytes=0-1023
`206 Partial Content` 响应:
-```bash
-
+```http
HTTP/1.1 206 Partial Content
Content-Range: bytes 0-1023/146515
Content-Length: 1024
@@ -101,7 +112,7 @@ Content-Length: 1024
客户端想要获取资源的第 0 到 499 字节以及第 1000 到 1499 字节:
-```bash
+```http
GET /path/to/resource HTTP/1.1
Host: example.com
Range: bytes=0-499,1000-1499
@@ -109,7 +120,7 @@ Range: bytes=0-499,1000-1499
服务器端返回多个字节范围,每个范围的内容以分隔符分开:
-```bash
+```http
HTTP/1.1 206 Partial Content
Content-Type: multipart/byteranges; boundary=3d6b6a416f9b5
Content-Length: 376
@@ -137,13 +148,13 @@ Content-Range: bytes 1000-1099/2000
### 状态码 100
-HTTP/1.1 中新加入了状态码`100`。该状态码的使用场景为,存在某些较大的文件请求,服务器可能不愿意响应这种请求,此时状态码`100`可以作为指示请求是否会被正常响应,过程如下图:
+HTTP/1.1 中新加入了状态码 `100`。该状态码的使用场景为,存在某些较大的文件请求,服务器可能不愿意响应这种请求,此时状态码 `100` 可以作为指示请求是否会被正常响应,过程如下图:
-
+
-
+
-然而在 HTTP/1.0 中,并没有`100 (Continue)`状态码,要想触发这一机制,可以发送一个`Expect`头部,其中包含一个`100-continue`的值。
+然而在 HTTP/1.0 中,并没有 `100 (Continue)` 状态码,要想触发这一机制,可以发送一个 `Expect` 头部,其中包含一个 `100-continue` 的值。
### 压缩
@@ -151,15 +162,15 @@ HTTP/1.1 中新加入了状态码`100`。该状态码的使用场景为,存在
HTTP/1.1 则对内容编码(content-codings)和传输编码(transfer-codings)做了区分。内容编码总是端到端的,传输编码总是逐跳的。
-HTTP/1.0 包含了`Content-Encoding`头部,对消息进行端到端编码。HTTP/1.1 加入了`Transfer-Encoding`头部,可以对消息进行逐跳传输编码。HTTP/1.1 还加入了`Accept-Encoding`头部,是客户端用来指示他能处理什么样的内容编码。
+HTTP/1.0 包含了 `Content-Encoding` 头部,对消息进行端到端编码。HTTP/1.1 加入了 `Transfer-Encoding` 头部,可以对消息进行逐跳传输编码。HTTP/1.1 还加入了 `Accept-Encoding` 头部,是客户端用来指示它能处理什么样的内容编码。
## 总结
-1. **连接方式** : HTTP 1.0 为短连接,HTTP 1.1 支持长连接。
-1. **状态响应码** : HTTP/1.1 中新加入了大量的状态码,光是错误响应状态码就新增了 24 种。比如说,`100 (Continue)`——在请求大资源前的预热请求,`206 (Partial Content)`——范围请求的标识码,`409 (Conflict)`——请求与当前资源的规定冲突,`410 (Gone)`——资源已被永久转移,而且没有任何已知的转发地址。
-1. **缓存处理** : 在 HTTP1.0 中主要使用 header 里的 If-Modified-Since,Expires 来做为缓存判断的标准,HTTP1.1 则引入了更多的缓存控制策略例如 Entity tag,If-Unmodified-Since, If-Match, If-None-Match 等更多可供选择的缓存头来控制缓存策略。
-1. **带宽优化及网络连接的使用** :HTTP1.0 中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP1.1 则在请求头引入了 range 头域,它允许只请求资源的某个部分,即返回码是 206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
-1. **Host 头处理** : HTTP/1.1 在请求头中加入了`Host`字段。
+1. **连接方式**:HTTP/1.0 为短连接,HTTP/1.1 支持长连接。
+2. **状态响应码**:HTTP/1.1 中新加入了大量的状态码,光是错误响应状态码就新增了 24 种。比如说,`100 (Continue)`——在请求大资源前的预热请求,`206 (Partial Content)`——范围请求的标识码,`409 (Conflict)`——请求与当前资源的规定冲突,`410 (Gone)`——资源已被永久转移,而且没有任何已知的转发地址。
+3. **缓存处理**:在 HTTP/1.0 中主要使用 header 里的 `If-Modified-Since`、`Expires` 来作为缓存判断的标准,HTTP/1.1 则引入了更多的缓存控制策略,例如 `Entity Tag`、`If-Unmodified-Since`、`If-Match`、`If-None-Match` 等更多可供选择的缓存头来控制缓存策略。
+4. **带宽优化及网络连接的使用**:HTTP/1.0 中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能。HTTP/1.1 则在请求头引入了 `Range` 头域,它允许只请求资源的某个部分,即返回码是 `206 (Partial Content)`,这样就方便了开发者自由选择以便于充分利用带宽和连接。
+5. **Host 头处理**:HTTP/1.1 在请求头中加入了 `Host` 字段。
## 参考资料
diff --git a/docs/cs-basics/network/https-rsa-vs-ecdhe.md b/docs/cs-basics/network/https-rsa-vs-ecdhe.md
new file mode 100644
index 00000000000..2cda6aa813f
--- /dev/null
+++ b/docs/cs-basics/network/https-rsa-vs-ecdhe.md
@@ -0,0 +1,452 @@
+---
+title: HTTPS 握手里的 RSA 和 ECDHE,到底差在哪?(应用层)
+description: 对比 TLS 握手中 RSA 密钥交换与 ECDHE 密钥交换的核心差异,讲清前向安全、密码套件命名、TLS 1.3 变化及面试要点。
+category: 计算机基础
+tag:
+ - 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: HTTPS,RSA,ECDHE,TLS,握手,前向安全,密钥交换,密码套件,TLS 1.3,PreMasterSecret
+---
+
+很多人第一次学 HTTPS,脑子里会留下一个很粗的印象:
+
+**HTTPS = HTTP + 加密,加密 = RSA。所以,HTTPS = RSA 加密。**
+
+这个理解不是凭空来的。早期很多 HTTPS 部署确实大量使用 RSA 相关的密码套件,很多入门讲解也喜欢拿 RSA 举例。
+
+但严格说,HTTPS 从来不等于 RSA 加密。即使在 TLS 1.0、TLS 1.1 时代,RSA 也只是可选方案之一,协议里还存在 DHE 这类密钥交换方式。到了 TLS 1.3,静态 RSA 密钥交换已经被移除,RSA 更多出现在证书签名、身份认证这类位置。
+
+所以,这篇文章真正要对比的不是“RSA 和 ECDHE 谁更高级”。
+
+**RSA 握手里,会话密钥材料是客户端生成后加密发给服务端;ECDHE 握手里,会话密钥材料不是直接传过去的,而是客户端和服务端各自算出来的。**
+
+这篇文章主要回答几个问题:
+
+1. HTTPS 为什么不等于 RSA 加密?
+2. RSA 握手和 ECDHE 握手的会话密钥材料分别是怎么来的?
+3. ECDHE 为什么能提供前向安全性?
+4. TLS 1.3 为什么移除静态 RSA 密钥交换?
+
+把这些问题讲清楚了,`PreMasterSecret`、`Server Key Exchange`、前向安全、TLS 1.3 为什么移除静态 RSA,后面都能顺着理解。
+
+
+
+## TLS 握手的两个核心问题
+
+HTTPS 仍然基于 HTTP,也仍然依赖 TCP。区别在于,HTTP 报文不会直接裸跑在 TCP 之上,而是先经过 TLS 完成身份认证、密钥协商和加密保护。
+
+握手完成后,真正保护业务数据的通常是 AES-GCM 这类对称加密算法,而不是拿 RSA 去加密完整的请求和响应。
+
+这里有两个问题。
+
+**第一个问题:浏览器和服务器需要协商出一份会话密钥。**
+
+后面传输 HTTP 请求、Cookie、响应体时,就用这份会话密钥做对称加密。对称加密更适合处理大量数据;非对称加密计算成本高,一般不拿来直接加密完整网页内容。
+
+**第二个问题:浏览器需要确认对面真的是目标网站。**
+
+如果只是“服务器发一个公钥给浏览器”,那中间人也可以发自己的公钥。浏览器以为那是目标网站的公钥,后面就把秘密信息加密给了攻击者。证书、CA、数字签名解决的是这件事:证明这个公钥确实和这个域名绑定,而不是路上某个人塞进来的。
+
+RSA 握手和 ECDHE 握手都会面对这两个问题。只是它们解决“会话密钥怎么来”的方式不同。
+
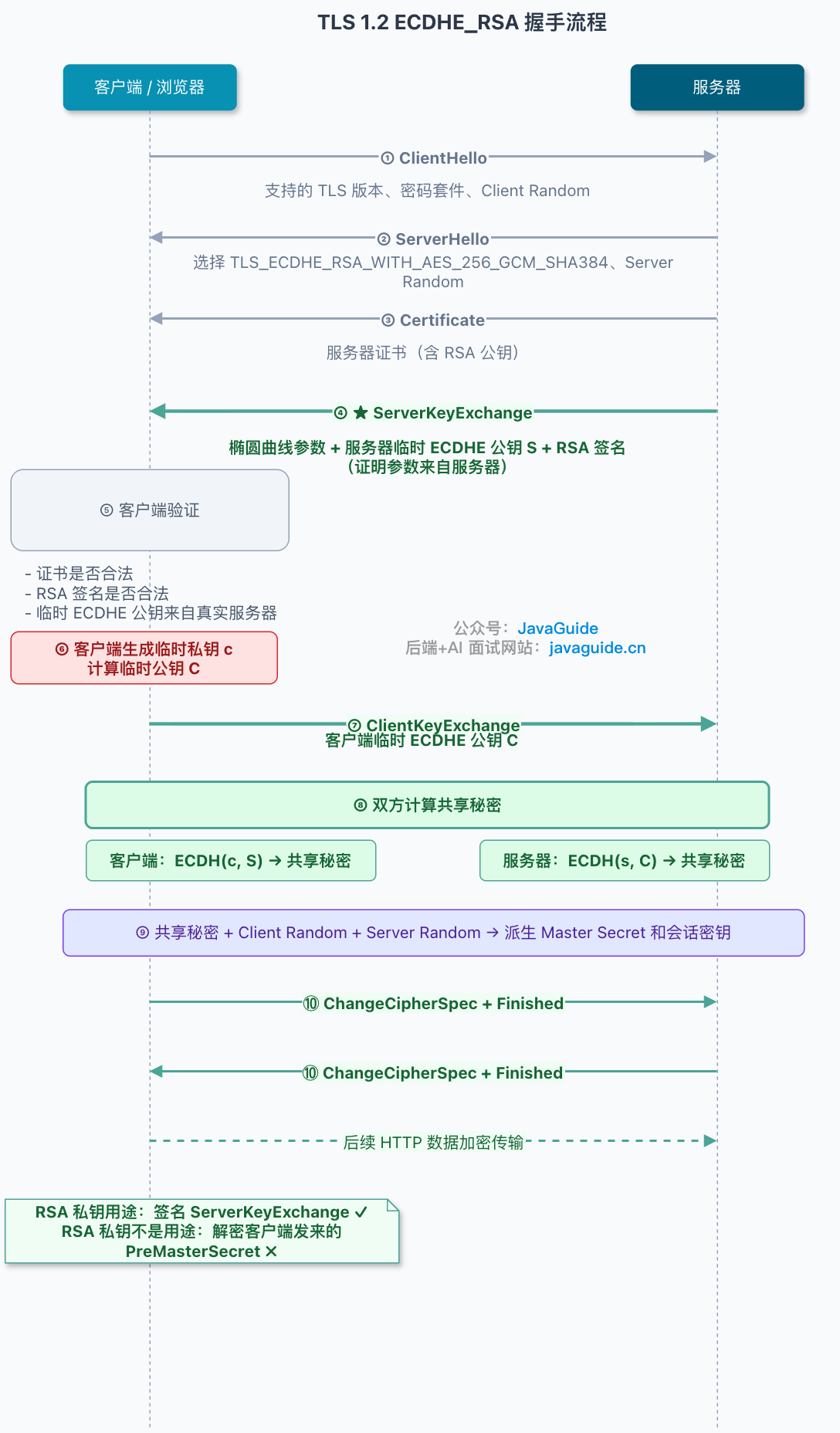
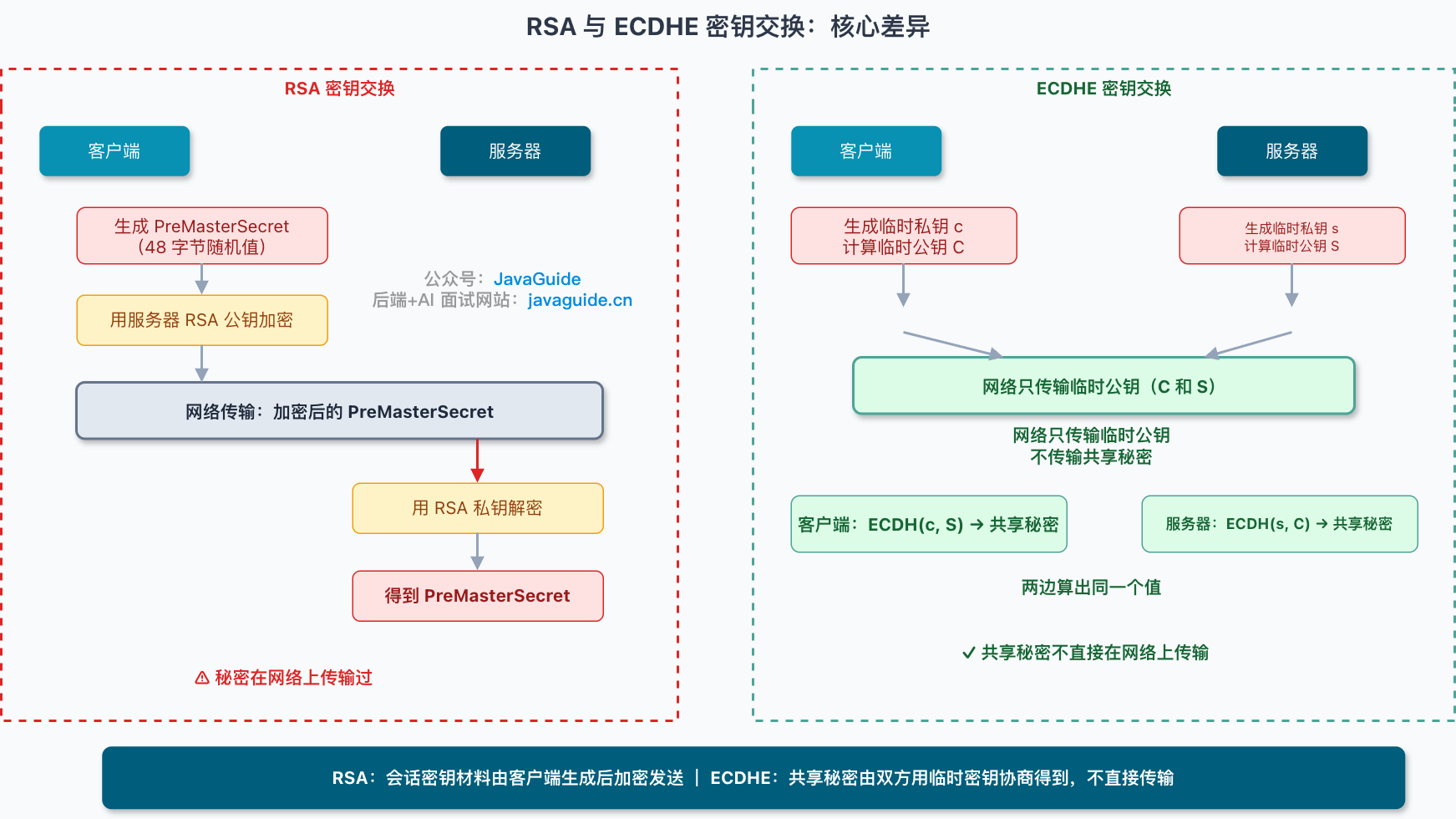
+## RSA 握手:密钥材料加密发送
+
+### 完整握手流程
+
+先看 TLS 1.2 里的 RSA 密钥交换。
+
+浏览器先发 `ClientHello`。这里面会带上客户端支持的 TLS 版本、支持的密码套件、一个随机数 `Client Random`。
+
+服务器收到之后,回 `ServerHello`,选定 TLS 版本和密码套件,也给出一个随机数 `Server Random`,然后把自己的证书发给客户端。
+
+到这里,客户端拿到了服务器证书。它会验证证书链、域名、有效期、签名这些信息。证书验证通过后,客户端就从证书里取出服务器的 RSA 公钥。
+
+接下来是关键步骤:客户端生成一个新的随机值,也就是 `PreMasterSecret`。在 TLS 1.2 的 RSA 密钥交换里,这个值是 **48 字节**。客户端会用服务器证书里的 RSA 公钥加密 `PreMasterSecret`,再把加密结果放进 `Client Key Exchange` 发给服务器。
+
+服务器收到后,用自己的 RSA 私钥解密,拿到同一份 `PreMasterSecret`。
+
+这时,客户端和服务端手里都有三份材料:
+
+```text
+Client Random
+Server Random
+PreMasterSecret
+```
+
+双方再根据这三份材料派生出 `Master Secret`,后续的会话密钥也会从这里继续派生出来。真正传 HTTP 请求和响应时,用的是这些派生出来的对称密钥。
+
+用一句话压缩:
+
+**RSA 握手的会话密钥材料,是客户端生成后“包起来”寄给服务器的。**
+
+这里的“包起来”,靠的就是服务器 RSA 公钥。只有持有对应 RSA 私钥的服务器,才能拆开这个包。
+
+看起来挺合理。客户端生成秘密,服务器私钥解密,双方得到同一份材料,再结合两个随机数派生出后续会话密钥。
+
+但问题也在这里。
+
+### 没有前向安全:长期私钥太值钱
+
+假设攻击者今天抓到了一段 HTTPS 流量,但当时没有服务器私钥,所以看不懂里面的内容。这时他可以先把流量保存下来。
+
+一年后,如果服务器 RSA 私钥泄漏了,会发生什么?
+
+在 RSA 密钥交换里,客户端当年发出的 `PreMasterSecret` 是用服务器 RSA 公钥加密的。如果攻击者完整捕获了握手阶段的明文随机数,也就是 `Client Random`、`Server Random`,同时保存了加密后的 `PreMasterSecret`,再结合后来泄漏的服务器私钥,就可能解开当时的 `PreMasterSecret`,继续派生出那次连接用过的会话密钥。
+
+旧数据就有机会被翻出来。
+
+这里要注意条件:不是“只要私钥泄漏,所有历史流量必然能解”。攻击者至少得拿到足够完整的握手数据和应用数据。如果只有单向片段,或者握手日志不完整,即使有私钥,也未必能把那次会话还原出来。
+
+但从安全设计上看,这个风险已经足够麻烦。长期私钥一旦变成打开历史流量的总钥匙,它的影响就不再只覆盖未来连接,也会波及过去已经发生过的通信。
+
+这里批评的不是 RSA 算法本身“不能用”。RSA 仍然可以用于签名认证,也可以出现在证书体系里。问题出在“用长期不变的服务器私钥去解密历史握手里的密钥材料”。
+
+服务器私钥一旦泄漏,代价太大。
+
+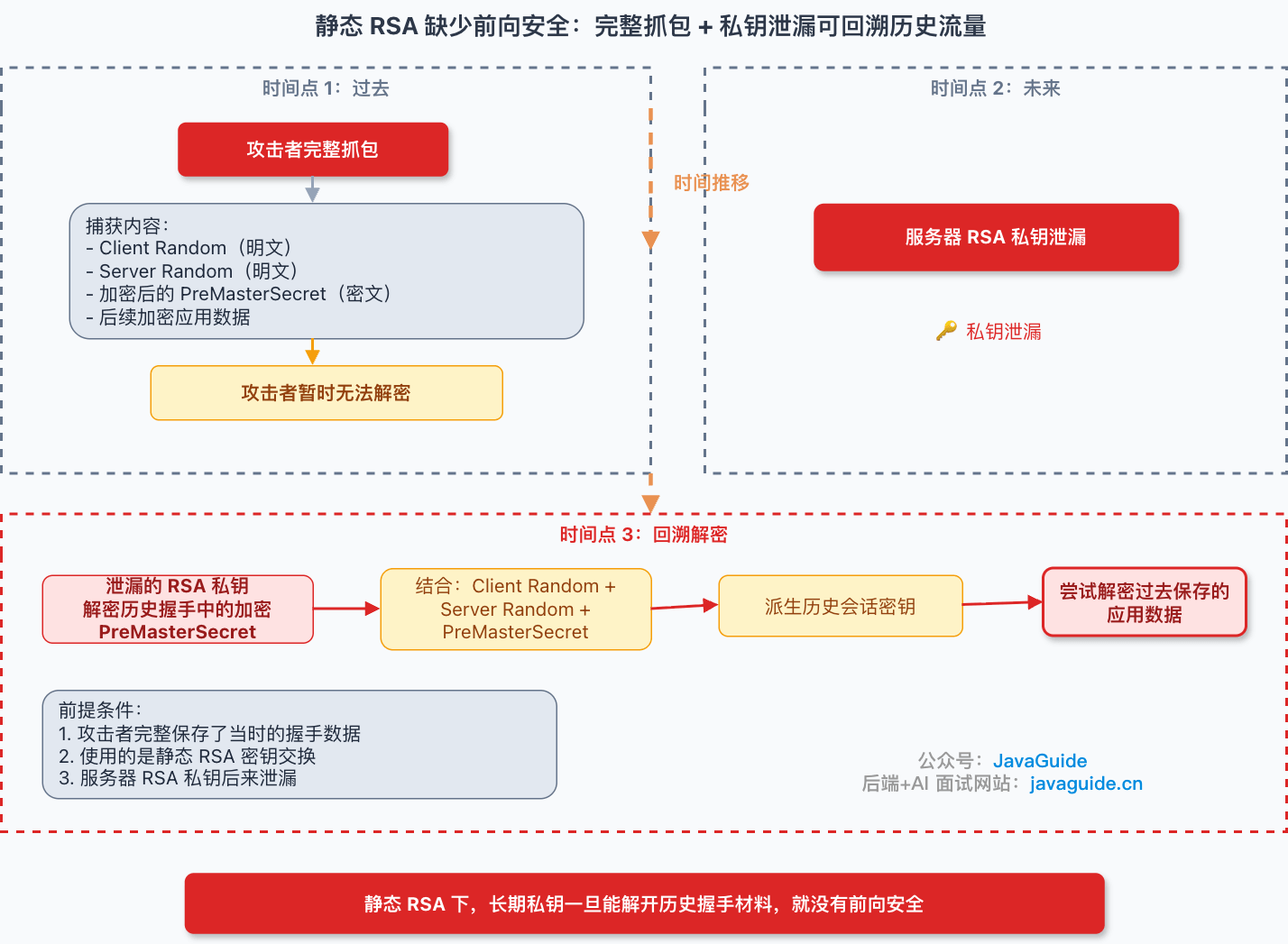
+
+### 另一个历史包袱:填充预言机攻击
+
+RSA 密钥交换还有一个工程层面的麻烦:`PreMasterSecret` 不是直接裸加密,而是按 RSAES-PKCS1-v1_5 这类格式封装后再加密。
+
+这个细节曾经引出过 Bleichenbacher 这类填充预言机攻击。
+
+它的大致思路是:攻击者不一定要马上拿到服务器私钥,而是反复构造不同的密文发给服务器,观察服务器对“填充错误、版本错误、长度错误”的处理差异。如果服务端在错误码、响应时间、日志行为、连接关闭方式上露出差别,攻击者就可能一点点逼近明文。
+
+这类攻击麻烦的地方在于,它不是单纯的数学问题,而是实现问题。
+
+TLS 1.2 对这类情况做过防御要求:服务端即使解密失败,也不要把具体失败原因暴露出去,而是继续用随机值走完整个流程,避免攻击者通过差异行为判断密文是否接近正确格式。
+
+可规范要求不等于实现可靠。2017 年的 ROBOT 攻击再次说明,一些服务端仍然可能因为细小的行为差异暴露出 RSA 解密 oracle。错误码、耗时、日志、分支路径,只要有一处表现不一致,都可能变成侧信道。
+
+所以,静态 RSA 密钥交换被淘汰,不只是因为它没有前向安全,也因为它把太多风险压到了实现细节上。
+
+### 能否被降级回 RSA?
+
+这里还要补一个容易误解的点。
+
+TLS 1.2 里,客户端会在 `ClientHello` 里带上自己支持的密码套件列表,服务端从里面选一个双方都支持的套件。理论上,如果服务端仍然开放 `TLS_RSA_*` 这类静态 RSA 密钥交换套件,老客户端就可能继续用 RSA 握手。
+
+但这不等于“中间人随便把 ClientHello 里的 ECDHE 删掉,就能让连接悄悄降级到 RSA”。握手最后的 `Finished` 会校验握手 transcript,简单篡改 `ClientHello` 通常会导致校验失败,连接建立不起来。
+
+历史上确实发生过降级相关攻击,比如 FREAK 和 Logjam。它们利用的是当时一些客户端、服务端仍然支持出口级弱密码套件,再结合实现和配置问题,把连接压到更弱的 RSA_EXPORT 或 DHE_EXPORT 路径上,而不是“随便删掉 ECDHE 就能静默成功”。TLS 1.3 在 `ServerHello.random` 里加入降级保护值,也是在提醒我们:协议本身一直在补这类历史攻击面。
+
+真正需要关注的是服务端配置本身:如果已经不需要兼容很老的客户端,就应该关闭静态 RSA 密钥交换套件,只保留支持前向安全的套件。否则,环境里仍然可能存在客户端或错误配置走到 RSA 握手。
+
+这也是排查 TLS 配置时要看密码套件实际协商结果的原因。只看“服务器支持 ECDHE”不够,还要看它是否同时保留了 `TLS_RSA_*` 这类旧套件。
+
+## ECDHE 握手:密钥材料双方协商
+
+### DH 的核心思路
+
+ECDHE 里的 `DHE` 来自 Diffie-Hellman Ephemeral,意思是临时 Diffie-Hellman。前面的 `EC` 是 Elliptic Curve,表示基于椭圆曲线。
+
+别被名字吓住。先不看椭圆曲线,先看 DH 想解决什么问题。
+
+DH 的目标很有意思:通信双方不直接传输共享秘密,却能各自算出同一个共享秘密。
+
+可以粗略理解成这样:
+
+客户端生成一个临时私钥,只留在本地,再算出一个临时公钥发给服务器。服务器也生成一个临时私钥,只留在本地,再算出一个临时公钥发给客户端。
+
+双方交换的都是公钥。攻击者在网络里能看到这些公钥,但看不到双方各自的临时私钥。
+
+接着,客户端用“自己的临时私钥 + 服务器临时公钥”算出共享秘密;服务器用“自己的临时私钥 + 客户端临时公钥”也算出同一个共享秘密。
+
+共享秘密没有在网络上传输过。
+
+ECDHE 只是把这个过程放到椭圆曲线体系里做。椭圆曲线的数学理论更抽象,但在同等安全强度下,它通常能用更短的密钥达到相近的安全级别,运算和传输成本也比传统有限域 DHE 更低。对理解 TLS 握手来说,先记住一句话就够了:
+
+**ECDHE 的会话密钥材料不是某一方生成后发给另一方,而是双方通过临时密钥协商出来的。**
+
+### 完整握手流程
+
+再看 TLS 1.2 里常见的 `ECDHE_RSA` 握手。
+
+客户端还是先发 `ClientHello`,里面有 TLS 版本、支持的密码套件、`Client Random`。服务器回 `ServerHello`,选择一个密码套件,比如:
+
+```text
+TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384
+```
+
+这个密码套件名要拆开看,不能看到 RSA 就以为它还在用 RSA 加密会话密钥。
+
+- `ECDHE` 表示密钥交换方式。
+- `RSA` 表示认证签名方式。
+- `AES_256_GCM` 表示后续记录数据使用 AES,密钥长度 256 位,模式是 GCM。
+- `SHA384` 指定 TLS 1.2 PRF 和 `Finished` 消息使用的哈希算法。
+
+GCM 本身已经提供记录层的完整性保护,所以这里的 `SHA384` 不再表示记录层 MAC,而是主要参与握手阶段的密钥派生和验证。
+
+服务端接着发证书。以 `ECDHE_RSA` 为例,证书里的 RSA 公钥主要用于验证服务端签名,而不是让客户端拿它加密 `PreMasterSecret`。
+
+然后,ECDHE 和 RSA 握手开始分叉。
+
+在 ECDHE 握手里,服务端会发送 `Server Key Exchange`。这个消息里会包含服务端选择的椭圆曲线参数,以及服务端临时 ECDHE 公钥。
+
+**问题来了:客户端怎么知道这份临时 ECDHE 公钥没有被中间人换掉?**
+
+**答案是签名。**
+
+服务端会用证书对应的私钥,对握手参数做签名。客户端收到后,用证书里的公钥验证签名。如果签名验证通过,客户端就能确认:这份临时 ECDHE 公钥确实来自持有证书私钥的服务器,不是路上被人替换的。
+
+随后客户端也生成自己的临时 ECDHE 私钥和公钥,把客户端临时公钥通过 `Client Key Exchange` 发给服务器。
+
+到这一步,双方都有了计算共享秘密需要的材料。
+
+客户端手里有:
+
+```text
+客户端临时私钥
+服务端临时公钥
+Client Random
+Server Random
+```
+
+服务端手里有:
+
+```text
+服务端临时私钥
+客户端临时公钥
+Client Random
+Server Random
+```
+
+两边各自计算出同一个共享秘密,再派生出后续使用的会话密钥。
+
+这里再强调一次:
+
+**ECDHE_RSA 里的 RSA,不是用来加密传输会话密钥的。它负责证明“这份 ECDHE 临时参数确实是服务器发的”。**
+
+这也是很多人看到密码套件名字后最容易误会的地方。
+
+
+
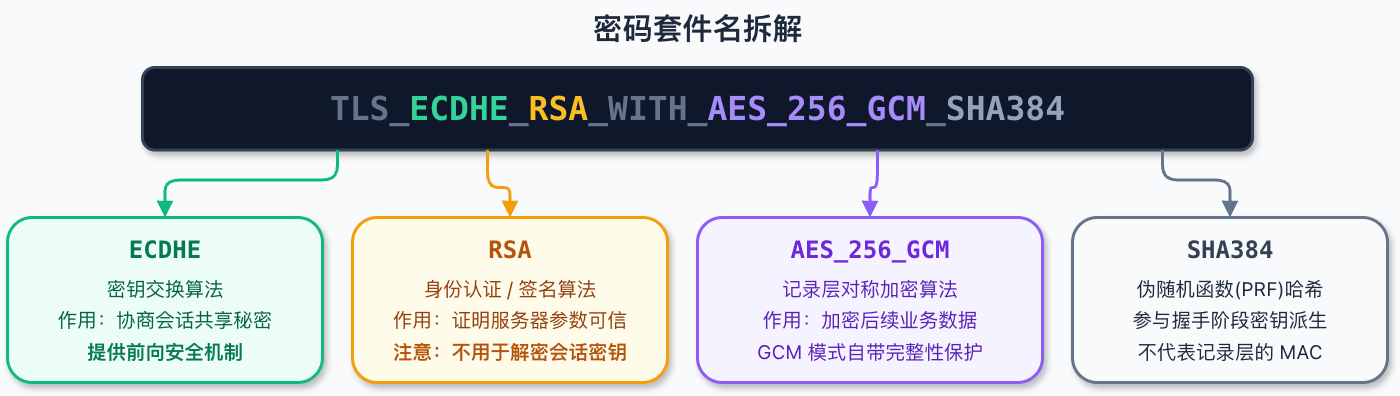
+### 密码套件名怎么读
+
+TLS 1.2 的密码套件名字通常可以按这条线拆:
+
+```text
+TLS_密钥交换算法_认证算法_WITH_对称加密算法_哈希算法
+```
+
+例如:
+
+```text
+TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256
+```
+
+可以拆成:
+
+```text
+ECDHE:密钥交换
+RSA:身份认证,也就是服务端签名
+AES_128_GCM:后续记录层加密算法
+SHA256:TLS 1.2 PRF 和 Finished 消息使用的哈希算法;如果是 GCM 套件,它不再充当记录层 MAC
+```
+
+再看另一个:
+
+```text
+TLS_RSA_WITH_AES_128_GCM_SHA256
+```
+
+这里的 `RSA` 出现在 `WITH` 前面,而且没有 `ECDHE`,表示密钥交换和身份认证都和 RSA 绑定。这类就是典型的静态 RSA 密钥交换套件。
+
+到了 TLS 1.3,密码套件命名变了,比如:
+
+```text
+TLS_AES_128_GCM_SHA256
+```
+
+你会发现,它不再把密钥交换和认证方式写进密码套件名里。TLS 1.3 把这些信息拆到其他扩展和握手消息中,密码套件名主要描述记录层 AEAD 算法和 HKDF 使用的哈希算法。
+
+所以,看到 TLS 1.3 的 `TLS_AES_128_GCM_SHA256`,不要误以为它“没有密钥交换”。密钥交换还在,只是不用 TLS 1.2 那套命名方式写出来了。
+
+
+
+## 前向安全与性能代价
+
+### ECDHE 为什么有前向安全
+
+关键在 `E`,也就是 `Ephemeral`,临时。
+
+ECDHE 握手里的私钥不是服务器证书那把长期私钥,而是握手过程中使用的临时私钥。连接结束后,正常情况下不应该再依赖这份临时材料。
+
+这带来的结果是:攻击者今天抓包,未来某天拿到了服务器证书私钥,也不能仅靠这把长期私钥还原过去每次握手里的临时共享秘密。因为当时真正参与密钥协商的是那次握手里的 ECDHE 临时私钥,而不是证书私钥。
+
+证书私钥在这里更像“签字笔”,不是“保险柜钥匙”。
+
+RSA 密钥交换里,服务器私钥可以直接打开客户端发来的 `PreMasterSecret`;ECDHE 里,服务器私钥只是给临时参数签名,证明身份。它不直接参与每次连接共享秘密的计算。
+
+这个角色变化,决定了两者在历史流量保护上的差异。
+
+
+
+不过,前向安全不是免死金牌。
+
+如果服务端随机数质量很差,临时私钥被日志记录下来,或者实现里出现内存泄漏,ECDHE 也救不了你。工程实现里,为了降低握手成本,部分实现还可能短时间复用临时 DH/ECDH 私密材料:有限域 DH 场景常说“指数复用”,ECDH 场景更常说“临时私钥/标量复用”。如果复用时间过长,前向安全的粒度就会变粗。
+
+还有一类风险来自参数校验。比如服务端没有正确校验客户端发来的椭圆曲线点是否在合法曲线上,就可能给无效曲线攻击留下空间。正常开发者不一定会直接写这层代码,但它提醒我们:密码学协议不只是“选对算法”就结束了,TLS 库实现和配置同样重要。
+
+### 会话恢复的影响
+
+还有一个容易被忽略的点:**会话恢复。**
+
+完整 ECDHE 握手要做临时密钥协商,成本不低。为了减少握手开销,TLS 支持会话恢复。客户端下次访问同一个站点时,可以尝试复用之前协商过的会话状态,避免每次都完整走一遍握手。
+
+问题在于,会话恢复也有自己的安全边界。
+
+以 TLS 1.2 的会话票据为例,服务端会用一把票据加密密钥保护会话状态,客户端后续带着票据回来,服务端解开票据后恢复会话。如果这把票据加密密钥长期不轮换,一旦它泄漏,攻击者就可能解开过去收集到的票据,并进一步还原相关恢复会话的密钥材料。
+
+这时,前向安全的窗口就不再是“一次连接”,而会被拉长到“票据加密密钥的生命周期”。
+
+所以线上配置不能只看“是否启用了 ECDHE”。会话票据密钥怎么生成、怎么轮换、是否在多台机器间共享、泄漏后影响多大,也要算进去。
+
+### 性能不是免费的
+
+ECDHE 带来了前向安全,但它也有成本。
+
+RSA 密钥交换的主路径,是服务端用长期 RSA 私钥解开客户端发来的 `PreMasterSecret`。ECDHE_RSA 则需要完成临时 ECDH 协商,还要对服务端临时参数做签名。
+
+对高并发服务来说,TLS 握手会消耗 CPU,尤其是短连接多、会话恢复命中率低的时候。
+
+这里不能简单写成“ECDHE 一定比 RSA 慢”。实际开销取决于 RSA 密钥长度、椭圆曲线选择、签名算法、TLS 库实现、CPU 指令集、会话恢复命中率等因素。比如 X25519、P-256、RSA 2048、RSA 3072 在不同 CPU 和不同 TLS 库上的表现都不一样。
+
+如果真要判断成本,最靠谱的方法不是引用别人的固定数字,而是在目标机器上压测。至少要区分三件事:
+
+```text
+1. 单次密码学操作耗时
+2. 完整 TLS 握手耗时
+3. 业务请求端到端耗时
+```
+
+第一项可以用 `openssl speed` 粗看数量级,比如测试 RSA、ECDH、X25519 的运算能力;第二项要看 TLS 库和服务端配置;第三项还会受网络、连接复用、应用逻辑影响。
+
+所以线上不会只靠“换成 ECDHE”解决所有问题。更常见的做法是配合 TLS 1.3、会话恢复、合理的证书算法和曲线选择,必要时再用硬件加速。
+
+安全性和性能不是二选一,但也不能假装没有成本。
+
+## TLS 1.3 的变化
+
+如果只看 TLS 1.2,RSA 和 ECDHE 可以作为两种密钥交换方式来对比。
+
+但到了 TLS 1.3,静态 RSA 密钥交换已经被移除,握手结构也改了。
+
+TLS 1.2 完整握手通常需要 2 个 RTT。客户端先发 `ClientHello`,服务端回 `ServerHello`、证书和相关握手消息,客户端再发密钥交换和 `Finished`,服务端最后回 `Finished`。
+
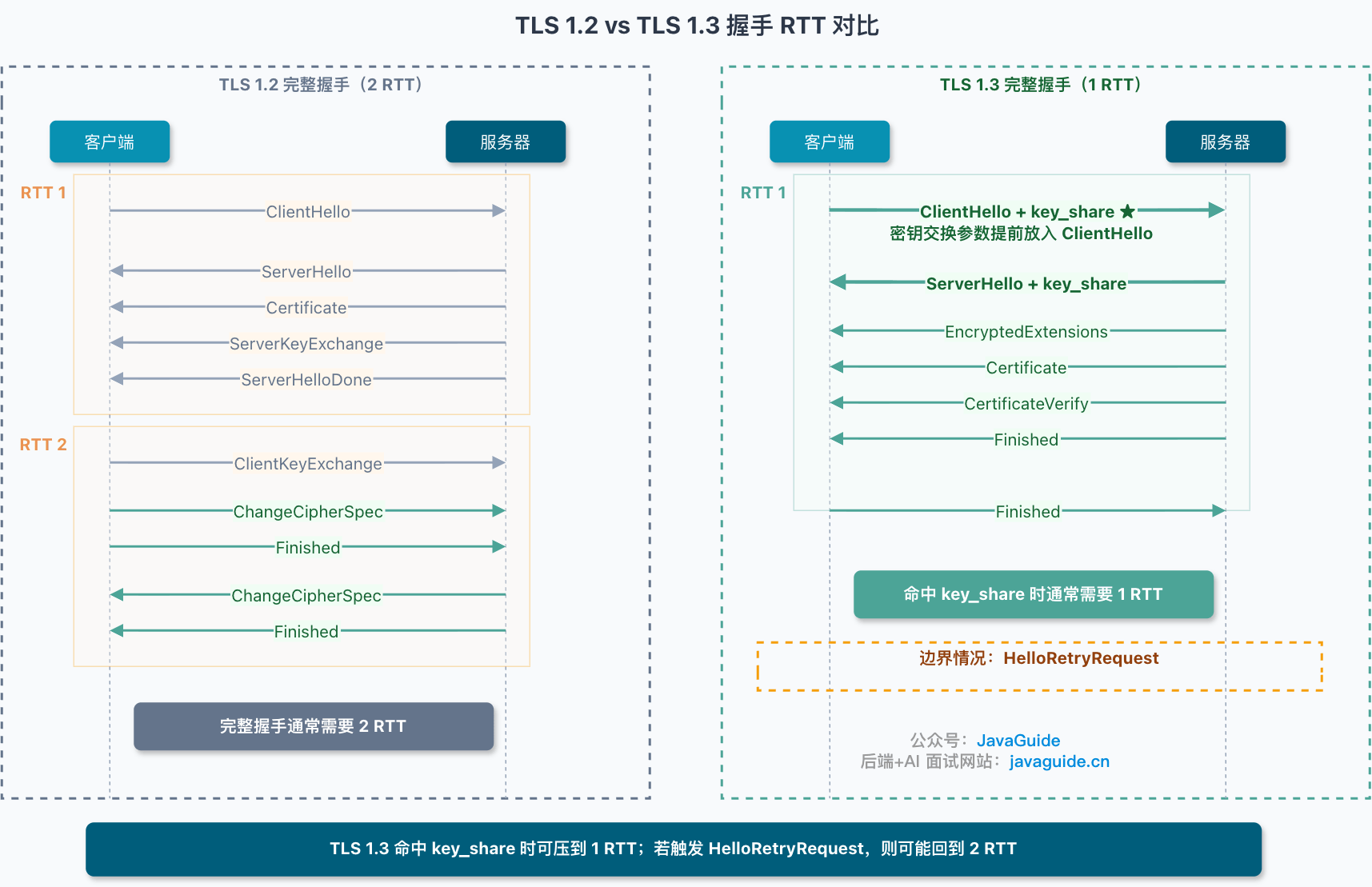
+TLS 1.3 则把密钥交换参数提前放进 `ClientHello` 的 `key_share`。服务端第一轮响应就能返回自己的 `key_share`,完整握手通常压到 1 个 RTT。
+
+2 RTT 变 1 RTT 能省多少毫秒,取决于网络环境。同机房可能只是几毫秒;跨地域、移动网络、高丢包场景下,少一个 RTT 才更容易被感知。
+
+不过,TLS 1.3 也不是任何情况下都稳稳 1 RTT。如果客户端带的 `key_share` 和服务端支持的曲线不匹配,服务端会返回 `HelloRetryRequest`,要求客户端换一组参数再来一次。这时握手可能重新接近 2 RTT。
+
+所以生产环境里,客户端和服务端对常见密钥协商组的支持要尽量对齐,比如 `X25519`、`secp256r1` 这类常见选择。否则 TLS 1.3 的 1 RTT 优势可能打折。
+
+
+
+至于后量子混合密钥交换、0-RTT、PSK-only、mTLS,这些都属于另一条线,本文不展开。
+
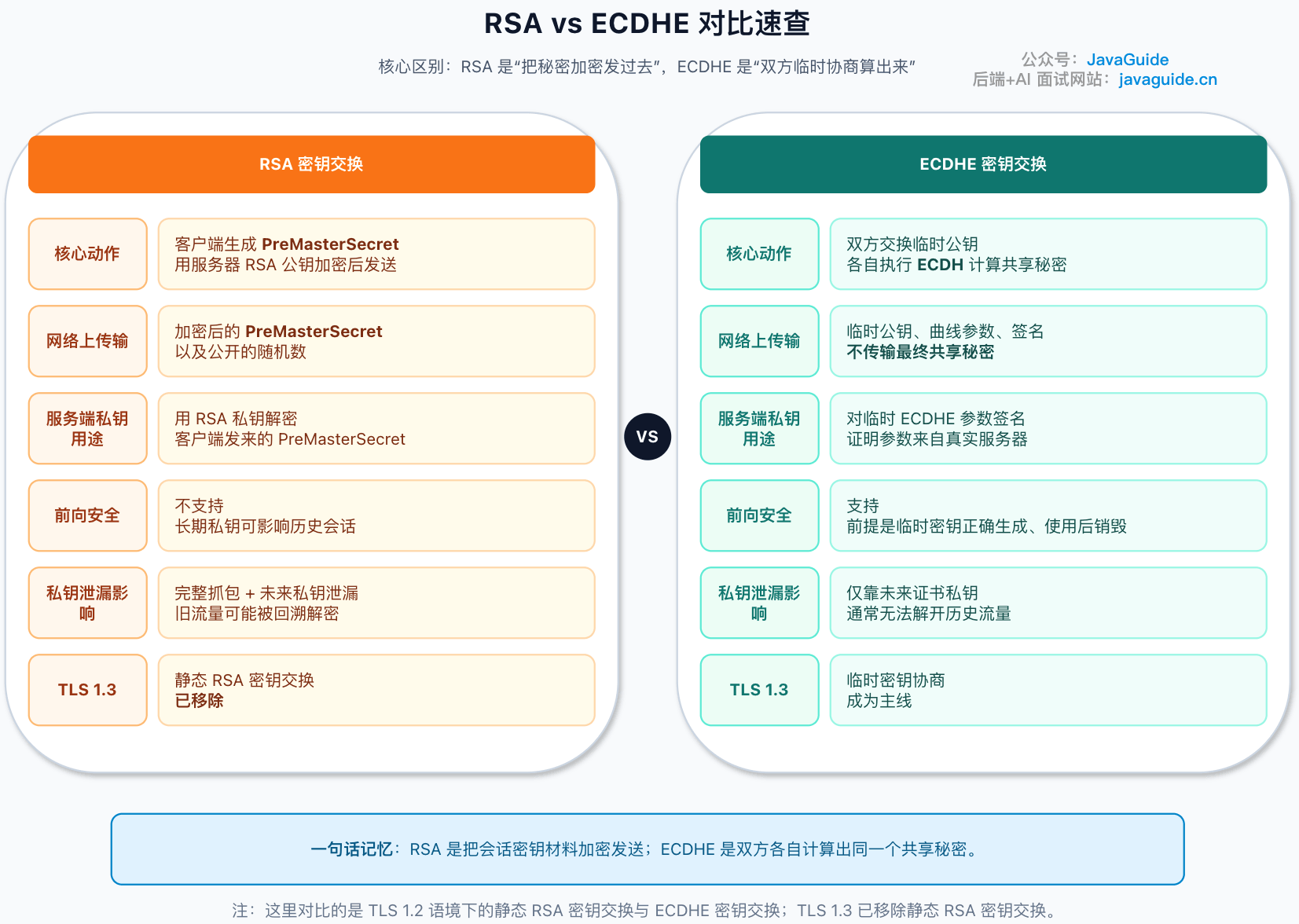
+## RSA vs ECDHE 核心差异速查
+
+放到一起看,差异就很清楚了。
+
+| 对比项 | RSA 密钥交换 | ECDHE 密钥交换 |
+| ------------------ | ------------------------------------------------------- | ------------------------------------------------------ |
+| 常见版本背景 | TLS 1.2 及更早版本可见 | TLS 1.2 常见,TLS 1.3 延续临时密钥协商方向 |
+| 会话密钥材料怎么来 | 客户端生成 `PreMasterSecret`,用服务器 RSA 公钥加密发送 | 双方各自生成临时密钥对,通过 ECDHE 算出共享秘密 |
+| 服务器私钥的作用 | 解密客户端发来的 `PreMasterSecret` | 对临时 ECDHE 参数签名,证明参数来自真实服务端 |
+| 网络上传了什么 | 加密后的 `PreMasterSecret` | 双方临时公钥和签名后的参数 |
+| 是否支持前向安全 | 不支持 | 支持,前提是临时密钥正确生成、使用后不再保留 |
+| 私钥泄漏后的影响 | 在握手数据完整捕获的情况下,历史流量可能被解密 | 仅靠证书私钥,通常无法解开历史流量 |
+| 典型问题 | 长期私钥价值过高,存在 PKCS#1 v1.5 填充预言机历史包袱 | 握手有额外计算成本,参数校验和临时密钥管理依赖实现质量 |
+| TLS 1.3 情况 | 静态 RSA 密钥交换已移除 | 临时密钥协商成为主线 |
+
+
+
+如果你要在面试里快速讲,可以这样说:
+
+**RSA 握手是“客户端生成秘密,用服务器公钥加密发过去”;ECDHE 握手是“双方交换临时公钥,各自算出同一个秘密”。RSA 的服务器私钥能解历史握手材料,所以没有前向安全;ECDHE 的证书私钥只做签名认证,不直接解会话秘密,所以更适合现代 HTTPS。**
+
+这段就够用了。
+
+### 常见误读:ECDHE_RSA 不是两种算法都加密
+
+再单独说一下 `ECDHE_RSA`,因为这个名字太容易让人误读。
+
+很多人看到:
+
+```text
+TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384
+```
+
+第一反应是:是不是先做一轮 ECDHE 运算,再做一轮 RSA 加密?
+
+不是。
+
+在这个密码套件里:
+
+密钥交换用 ECDHE;
+身份认证用 RSA 签名;
+后续数据加密用 AES-256-GCM;
+相关哈希使用 SHA384。
+
+这也解释了为什么“HTTPS 还在用 RSA”这句话要小心说。
+
+用 RSA 做证书签名,和用 RSA 做密钥交换,是两件事。
+
+前者在现代 HTTPS 里仍然常见,后者已经不适合作为现代 TLS 的主线。
+
+### RSA 在现代 HTTPS 里的实际角色
+
+学习 HTTPS 握手时,很多入门资料喜欢用一句话概括:
+
+非对称加密交换对称密钥。
+
+这句话在入门阶段有帮助,但不够准确。它更像是在描述早期 RSA 密钥交换的思路。
+
+到了 ECDHE,密钥不是简单“加密后传输”,而是双方协商出来的。到了 TLS 1.3,密钥交换、身份认证、记录层加密的边界更清楚:临时密钥协商负责生成共享秘密,证书负责身份认证,对称加密负责保护后续应用数据。
+
+更准确的说法应该是:
+
+HTTPS 的业务数据通常用对称密钥加密;TLS 握手负责协商这份密钥并验证身份。RSA 可以参与身份认证,也曾经可以参与密钥交换;ECDHE 负责临时密钥协商,能避免历史会话因为未来证书私钥泄漏而直接暴露。
+
+如果把这几件事混在一起,就很容易得出错误结论:看到 RSA 就以为它在加密会话密钥,看到 ECDHE_RSA 就以为两种算法都在做加密。
+
+事实不是这样。
+
+## 用一次完整请求串起来
+
+浏览器访问一个 HTTPS 网站时,TCP 连接先建立起来。接着 TLS 握手开始。
+
+如果是 TLS 1.2 的 RSA 密钥交换,客户端验证证书后,生成 48 字节的 `PreMasterSecret`,用服务器证书里的 RSA 公钥加密发给服务器。服务器用 RSA 私钥解密,双方再结合两个随机数派生会话密钥。
+
+如果是 TLS 1.2 的 ECDHE_RSA,服务器发证书后,还会发 `Server Key Exchange`,里面带着临时 ECDHE 公钥和签名。客户端验证签名后,也生成自己的临时 ECDHE 公钥发回去。双方不传输最终共享秘密,而是各自算出同一个共享秘密,再派生会话密钥。
+
+这两个流程看起来只差了几个握手消息,安全性质却差很多。
+
+RSA 密钥交换的问题是历史包袱太重:长期私钥一旦泄漏,过去保存下来的流量也可能遭殃;再加上 PKCS#1 v1.5 填充预言机这类实现风险,它已经不适合作为现代 TLS 密钥交换方案。
+
+ECDHE 把每次连接的密钥协商换成临时过程,让服务器长期私钥不再成为打开历史流量的钥匙。它也有计算成本,也依赖正确实现和配置,但方向更符合现代 HTTPS 的安全要求。
+
+这篇文章只聚焦一个问题:**RSA 密钥交换和 ECDHE 密钥交换到底差在哪**。如果继续往下讲,还可以展开 TLS 1.3 的 0-RTT、PSK、会话票据轮换、mTLS、证书透明、后量子迁移,这些都值得单独写。
+
+所以,面试里问“RSA 和 ECDHE 握手有什么区别”,不要只回答“一个不支持前向安全,一个支持前向安全”。
+
+真正要讲的是:
+
+**RSA 是把秘密加密送过去;ECDHE 是双方临时协商出来。**
+
+把这句话讲透,后面的 `PreMasterSecret`、`Server Key Exchange`、前向安全、TLS 1.3 为什么移除静态 RSA,就都能顺着讲下去了。
+
+## 面试怎么回答:HTTPS 握手里的 RSA 和 ECDHE,到底差在哪?
+
+RSA 和 ECDHE 的核心区别在于:**会话密钥材料是“传过去的”,还是“协商出来的”**。
+
+在 TLS 1.2 的静态 RSA 握手里,客户端生成 `PreMasterSecret`,用服务器证书里的 RSA 公钥加密后发给服务端,服务端再用 RSA 私钥解密。问题是,如果攻击者保存了当年的握手流量,后来服务器私钥又泄漏,就可能回头解出历史会话密钥,所以它没有前向安全。
+
+ECDHE 不直接传输共享秘密。客户端和服务端各自生成临时密钥对,交换临时公钥后,双方本地算出同一个共享秘密。服务器证书私钥主要用于签名认证,证明临时参数没被中间人替换,而不是用来解密会话密钥。
+
+所以一句话总结:**RSA 是客户端把秘密加密送过去;ECDHE 是双方用临时密钥协商出秘密。ECDHE 支持前向安全,也因此成为现代 HTTPS 的主流方向。**
diff --git a/docs/cs-basics/network/images/arp/2008410143049281.png b/docs/cs-basics/network/images/arp/2008410143049281.png
deleted file mode 100644
index 759fb441f6c..00000000000
Binary files a/docs/cs-basics/network/images/arp/2008410143049281.png and /dev/null differ
diff --git a/docs/cs-basics/network/maximum-number-of-tcp-connections-per-host.md b/docs/cs-basics/network/maximum-number-of-tcp-connections-per-host.md
new file mode 100644
index 00000000000..183450d9ca4
--- /dev/null
+++ b/docs/cs-basics/network/maximum-number-of-tcp-connections-per-host.md
@@ -0,0 +1,160 @@
+---
+title: 一台主机上只能保持最多 65535 个 TCP 连接吗?
+description: 从 TCP 四元组、临时端口、文件描述符、内存、TIME_WAIT 与 NAT 等角度,解释一台主机能保持多少 TCP 连接。
+category: 计算机基础
+tag:
+ - 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: TCP连接数,65535,TCP四元组,TIME_WAIT,临时端口,文件描述符,NAT
+---
+
+一台主机最多只能保持 65535 个 TCP 连接吗?小 G 先给结论:**不是**。
+
+`65535` 这个数字来自端口号范围。TCP 首部里的源端口和目的端口字段都是 16 位,可以表示 `0~65535`,一共 2^16 = 65536 个取值。**65535 是最大端口号,不是连接数上限。**
+
+但 TCP 连接数和端口号数不是一回事。要搞清楚这个问题,得从 TCP 连接是怎么被标识的开始讲。
+
+## TCP 连接靠四元组来区分
+
+TCP 连接不是靠“本地端口”唯一标识,而是靠四元组标识:
+
+```text
+源 IP、源端口、目的 IP、目的端口
+```
+
+只要四元组不同,内核就可以把它们识别为不同连接。
+
+为了避免混淆,下面统一用**客户端发起连接时的视角**来写四元组:`(客户端 IP, 客户端端口, 服务端 IP, 服务端端口)`。
+
+假设服务器 IP 是 `192.168.1.100`,监听端口 `8080`:
+
+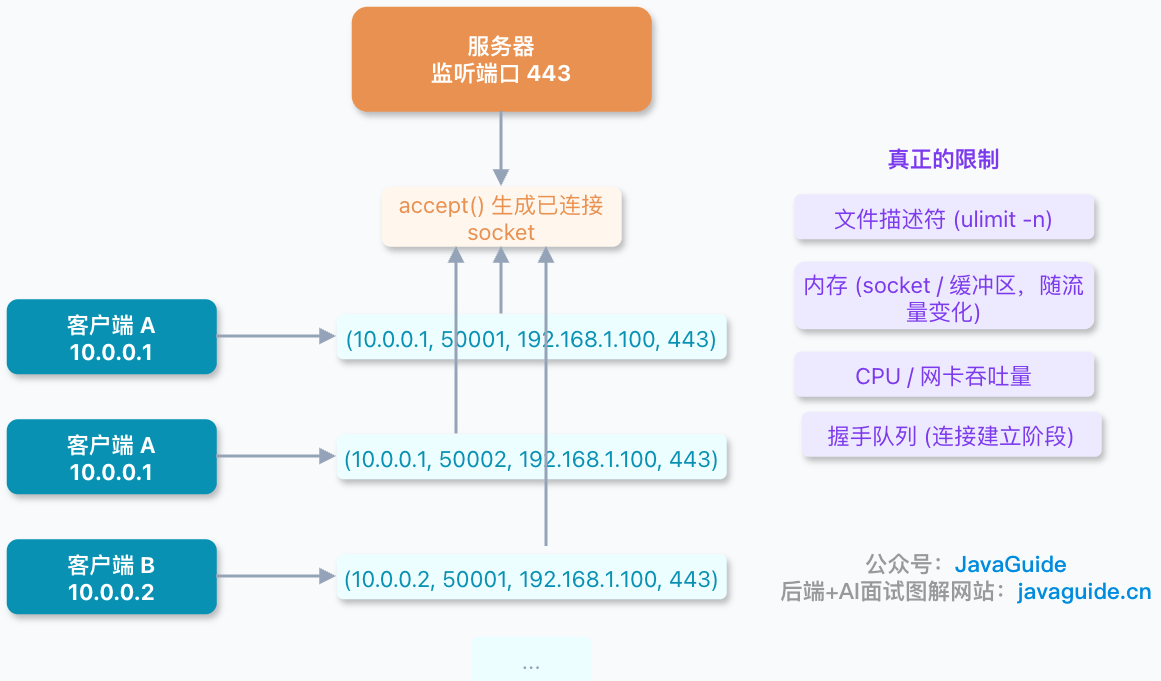
+
+- 客户端 A(`10.0.0.1:50000`)连过来 → 四元组 `(10.0.0.1, 50000, 192.168.1.100, 8080)`
+- 客户端 A(`10.0.0.1:50001`)再连过来 → 四元组 `(10.0.0.1, 50001, 192.168.1.100, 8080)`
+- 客户端 B(`10.0.0.2:50000`)连过来 → 四元组 `(10.0.0.2, 50000, 192.168.1.100, 8080)`
+
+三条连接,服务端的 IP 和端口都没变,但因为客户端 IP 或端口不同,四元组各不相同,所以是三条独立的连接。
+
+这里有个容易混淆的点:服务端 `8080` 端口只有**一个监听 socket**,但每 `accept()` 一次,内核就会生成一个新的**已连接 socket**,用四元组来区分。所以多个连接共享同一个服务端端口,完全不冲突。
+
+## 为什么服务端可以超过 65535?
+
+假设 Web 服务监听 `192.168.1.100:443`,服务端 IP 和端口固定,但客户端 IP 和端口会变化。比如 `(10.0.0.1, 50001, 192.168.1.100, 443)` 和 `(10.0.0.2, 50001, 192.168.1.100, 443)` 的服务端端口都是 443,但四元组不同,所以是两条不同 TCP 连接。
+
+纯从 IPv4 四元组组合看,固定服务端 IP 和端口后,客户端 IP 理论上有 `2^32` 种可能,客户端端口有 `2^16` 种可能,理论组合数非常大。
+
+真实上限来自资源和配置。
+
+## 真正的限制是什么?
+
+**1、文件描述符(File Descriptor,FD)和内存。**
+
+在 Linux 里,socket 也是文件。对应用进程来说,`accept()` 后的每条已建立连接通常对应一个 socket FD;**监听 socket 本身也占一个 FD**。还没被 `accept()` 的连接会先停留在内核队列里,不应简单都算成应用已持有的 FD。
+
+进程可打开文件数不够时,常见报错是 `Too many open files`。
+
+每条 TCP 连接都需要内核维护 socket、TCP 控制块、发送缓冲区、接收缓冲区等数据。连接空闲时开销较小,一旦有数据收发,缓冲区和应用对象也会继续占内存。
+
+不建议死记“一个连接占多少 KB”。这个值会受内核版本、socket 选项、缓冲区大小和业务收发情况影响。
+
+**2、握手队列和 accept 速度。**
+
+Linux 实际上维护两个队列:
+
+- **SYN 队列(半连接队列)**:收到 SYN、发出 SYN-ACK、尚未完成三次握手的连接,受 `tcp_max_syn_backlog` 限制,实际大小还会结合 `somaxconn` 和 `listen()` backlog 计算。
+- **accept 队列(全连接队列)**:已完成握手、等待应用 `accept()` 的连接,上限为 `min(listen(fd, backlog), net.core.somaxconn)`。
+
+它们影响的是**连接建立阶段的排队和丢弃**,不是 ESTABLISHED 连接总数的简单上限。
+
+半连接队列溢出时,Linux 可以启用 SYN Cookie 机制:服务端把必要信息编码进 SYN-ACK 的序列号,不在本地保留完整的半连接状态,收到合法 ACK 后再重建连接信息。SYN Cookie 是防护手段,不是扩容手段。
+
+全连接队列溢出时,行为取决于 `tcp_abort_on_overflow`:默认值 `0` 时,服务端会丢弃客户端发来的 ACK,让客户端重传,服务端有机会重传 SYN-ACK;设为 `1` 时,直接回复 RST,快速失败。生产环境通常保持默认值 `0`,避免误拒正常连接。排查全连接队列溢出可以用 `ss -ltn`:如果 Recv-Q 长时间接近 Send-Q,说明 accept 不够及时,要检查应用线程池是否卡住或 backlog 配置是否过小。
+
+**3、CPU、网卡和业务处理能力。**
+
+空闲长连接主要考验内存、FD 上限、内核连接表和连接保活策略;活跃连接还会带来系统调用、加解密、协议解析、线程调度和网卡中断等压力。
+
+## 客户端为什么更容易撞到端口限制?
+
+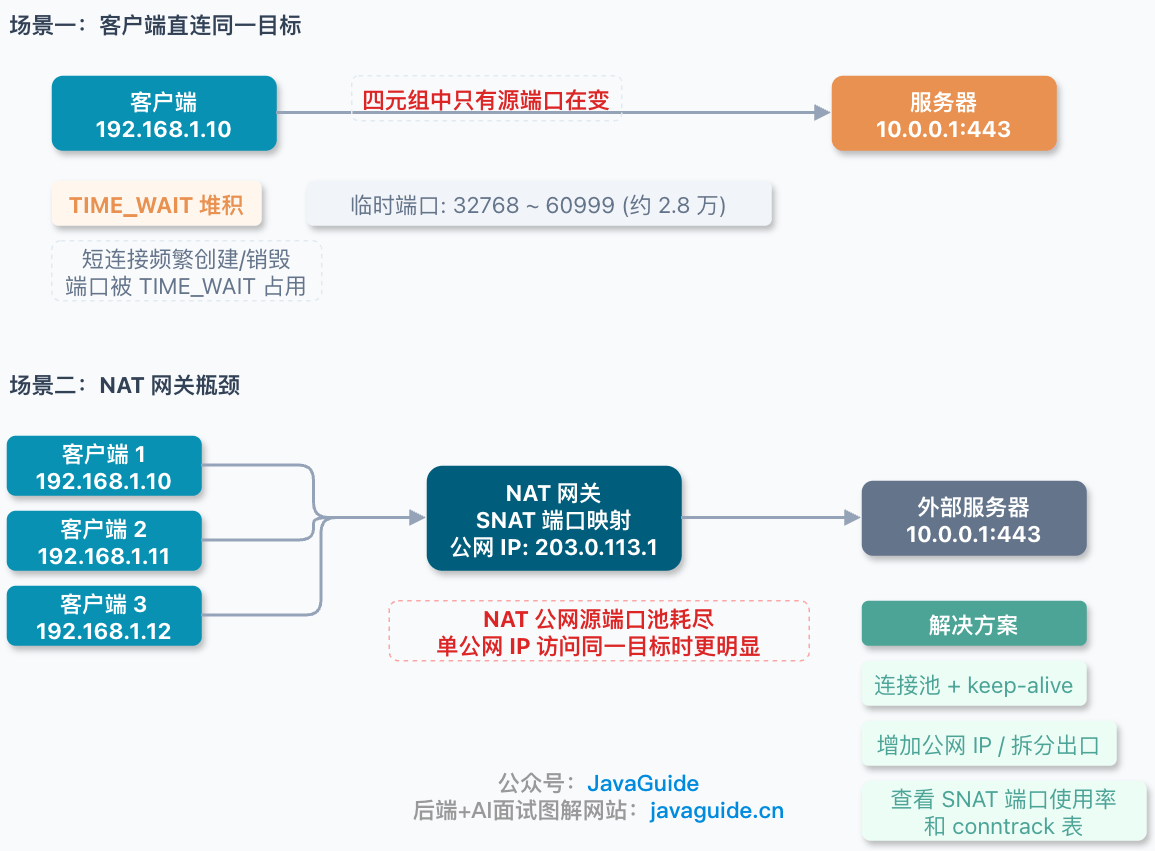
+
+服务端不是 65535 上限,但客户端访问同一个目标时,临时端口可能先耗尽。
+
+例如客户端固定为 `192.168.1.10`,不断连接 `10.0.0.1:443`。这时目的 IP、目的端口、源 IP 都固定,只剩源端口可变。源端口用完后,就无法再创建新四元组。
+
+Linux 自动分配临时端口范围可以这样看:
+
+```bash
+sysctl net.ipv4.ip_local_port_range
+```
+
+Mac 下可以这样查看:
+
+
+
+很多 Linux 环境默认临时端口范围是 `32768 60999`,大约 2.8 万个端口;实际值以 `sysctl net.ipv4.ip_local_port_range` 输出为准,且不是全部 `0~65535` 都会自动拿来做临时端口。
+
+看到 `Cannot assign requested address` / `EADDRNOTAVAIL`、大量 `connect` 失败,且目标 `IP:Port` 很集中时,要怀疑临时端口耗尽或 `TIME_WAIT` 堆积。
+
+## NAT 网关这层也可能先顶不住
+
+还有一种情况容易被忽略:很多内网机器并不是直接访问公网,而是先经过 NAT 网关。
+
+NAT 做的事情是把内网地址转换成公网地址。比如内网机器 `192.168.1.10:50000` 访问外部服务时,NAT 可能会改成 `203.0.113.1:40000`,并在本地记录这条映射。响应包回来后,再根据映射关系转发回原来的内网机器。
+
+如果大量内网机器共享同一个公网 IP,并集中访问**同一个外部 `IP:Port`**,NAT 侧可用的公网源端口数量就会成为限制因素。如果目标分散,端口复用空间会更大。端口不够只是其中一类问题,NAT 设备的连接跟踪表、CPU、内存也可能先到瓶颈。
+
+所以排查连接数问题时,不要只盯着客户端和服务端,链路中间的 NAT 网关也要看。
+
+常见的 NAT 侧排查指标包括:NAT 连接跟踪表使用率、SNAT 端口使用率、单公网 IP 到单目标的连接数,以及 NAT 设备的 CPU、内存、丢包和连接创建速率。如果 NAT 确实成了瓶颈,可以考虑增加公网 IP、拆分出口或做连接复用。
+
+## TIME_WAIT 会怎样影响连接数?
+
+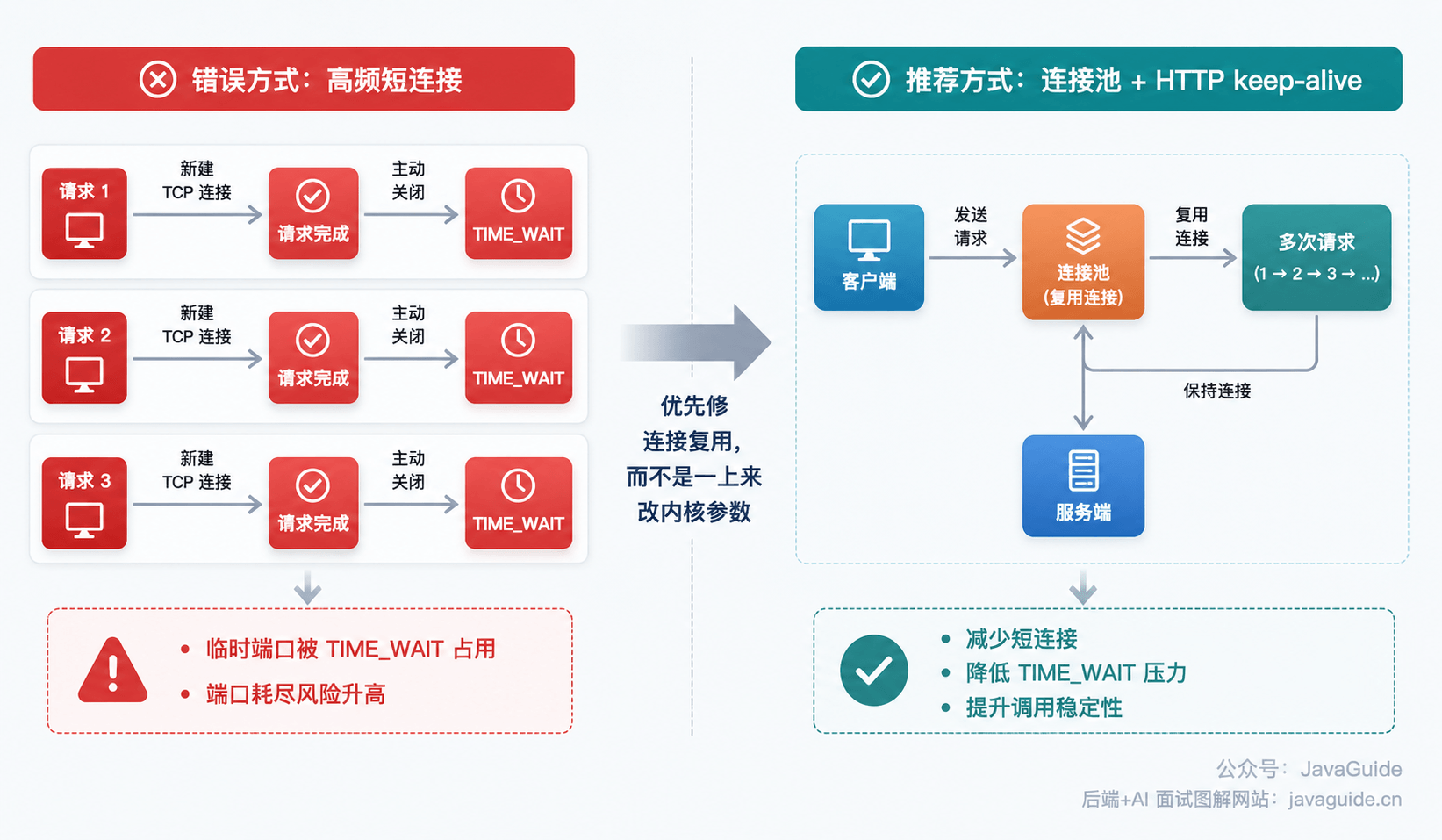
+
+典型情况下,**主动关闭连接的一方会进入 `TIME_WAIT`**——因为它需要在发送最后一个 ACK 后等待一段时间,防止最后 ACK 丢失以及旧报文影响后续连接。(同时关闭场景下,双方都会进入 TIME_WAIT,不过日常碰到的绝大多数是前者。)
+
+问题在于,`TIME_WAIT` 会让对应连接在一段时间内不能被随意复用。对客户端高频短连接同一目标来说,可用临时端口会被大量 `TIME_WAIT` 消耗,从而更容易撞到端口上限。
+
+这也是为什么高并发调用**优先建议使用连接池和 HTTP keep-alive**,从源头减少短连接创建。
+
+说到连接复用,很多人分不清 TCP Keepalive 和 HTTP Keep-Alive,其实它们解决的问题完全不同。
+
+简单说:HTTP Keep-Alive 管的是“一条连接最多用多久、服务多少次请求”,TCP Keepalive 管的是“如果长时间没数据,检查一下对方是不是已经消失了”。两者互不干扰,也不能互相替代。详细介绍可以看这篇文章:[TCP Keepalive 和 HTTP Keep-Alive 有什么区别?](./tcp-keepalive-vs-http-keepalive.md)。
+
+至于内核参数,别一看到 `TIME_WAIT` 多就急着改。
+
+`tcp_tw_reuse` 要结合内核版本、业务场景和真实的端口耗尽证据来看,不适合当成万能优化项。`tcp_tw_recycle` 更不用碰了,Linux 4.12 之后已经被移除。
+
+也别想着清理 TIME_WAIT。它不是脏东西,而是 TCP 协议里的正常机制。
+
+看到 `TIME_WAIT` 数量很多,第一反应应该是回到业务链路看问题:是不是一直在创建短连接?连接池有没有生效?HTTP keep-alive 有没有打开?客户端是不是每次请求完都主动断开?
+
+生产环境里很常见的一个坑,就是**连接池没配好,最后把临时端口耗光了**。
+
+比如:
+
+- HTTP 客户端没开 keep-alive,也没用连接池,每次请求都新建连接,请求完就关,`TIME_WAIT` 很快堆起来。
+- 连接池最大连接数、每个目标地址的连接数配置太小,导致连接一直被创建和销毁。
+- DNS 最后解析到单个 IP,请求目标太集中,四元组里主要只剩源端口在变,更容易把端口打满。
+
+排查这类问题,优先修连接复用。确认连接池、keep-alive、超时和关闭策略都没问题之后,再考虑扩大临时端口范围,或者增加源 IP。不要一上来就改内核参数。
+
+
+
+排查时可以用 `ss -ant` 统计各 TCP 状态数量,`ss -ant state time-wait | awk 'NR>1 {print $5}' | sort | uniq -c | sort -nr | head` 查看 TIME_WAIT 集中在哪些目标,`ss -ltn` 查看监听 socket 的 accept queue 堆积情况。看到 TIME_WAIT 集中在某个远端服务,检查短连接和连接池;看到 CLOSE_WAIT 集中在某个本地进程,优先查应用代码有没有正确关闭连接。
+
+## 回到问题
+
+一台主机最多只能保持 65535 个 TCP 连接吗?
+
+答案是:不能这么理解。
+
+`65535` 对应的是端口号范围,不是 TCP 连接数上限。TCP 连接靠四元组区分:源 IP、源端口、目的 IP、目的端口。服务端监听同一个端口时,只要客户端 IP 或客户端端口不同,连接就可以继续增加。
+
+不过,理论上能区分出来,不代表机器一定扛得住。实际连接数通常会被文件描述符、内存、CPU、网卡、应用处理能力、握手队列等资源限制住。客户端如果频繁短连接访问同一个目标,还会碰到临时端口和 `TIME_WAIT` 的压力;如果中间经过 NAT,还要看 NAT 网关能不能撑住。
+
+小 G 这里再压缩成一句话:**服务端连接数主要看机器资源,客户端连同一个目标主要看临时端口,中间有 NAT 时还要看 NAT 网关。`65535` 只是端口号上限,不是所有 TCP 连接的上限。**
diff --git a/docs/cs-basics/network/nat.md b/docs/cs-basics/network/nat.md
index 4567719b81e..adfabc04345 100644
--- a/docs/cs-basics/network/nat.md
+++ b/docs/cs-basics/network/nat.md
@@ -1,10 +1,26 @@
---
title: NAT 协议详解(网络层)
+description: 解析 NAT 的地址转换与端口映射机制,结合 LAN/WAN 通信与转换表,理解家庭与企业网络的实践细节。
category: 计算机基础
tag:
- 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: NAT,地址转换,端口映射,LAN,WAN,连接跟踪,DHCP
---
+很多设备在家用网络、公司内网里使用的都是私有 IP 地址,比如 `192.168.x.x`、`10.x.x.x`。这些地址不能直接在公网中路由,但内网设备依然可以访问互联网。
+
+这背后通常就有 NAT 在工作。NAT 会在内网地址和公网地址之间做转换,让多个内网设备共享一个或少量公网 IP 对外通信。
+
+这篇文章主要回答几个问题:
+
+1. NAT 主要解决什么问题?
+2. NAT 转换表是如何记录内外网地址和端口映射的?
+3. 内网主机访问公网时,源 IP 和端口会发生什么变化?
+4. NAT 会带来哪些限制,比如外部主动访问内网主机为什么更麻烦?
+
## 应用场景
**NAT 协议(Network Address Translation)** 的应用场景如同它的名称——网络地址转换,应用于内部网到外部网的地址转换过程中。具体地说,在一个小的子网(局域网,Local Area Network,LAN)内,各主机使用的是同一个 LAN 下的 IP 地址,但在该 LAN 以外,在广域网(Wide Area Network,WAN)中,需要一个统一的 IP 地址来标识该 LAN 在整个 Internet 上的位置。
@@ -15,26 +31,26 @@ SOHO 子网的“代理人”,也就是和外界的窗口,通常由路由器
## 细节
-
+
-假设当前场景如上图。中间是一个路由器,它的右侧组织了一个 LAN,网络号为`10.0.0/24`。LAN 侧接口的 IP 地址为`10.0.0.4`,并且该子网内有至少三台主机,分别是`10.0.0.1`,`10.0.0.2`和`10.0.0.3`。路由器的左侧连接的是 WAN,WAN 侧接口的 IP 地址为`138.76.29.7`。
+假设当前场景如上图。中间是一个路由器,它的右侧组织了一个 LAN,网络号为 `10.0.0/24`。LAN 侧接口的 IP 地址为 `10.0.0.4`,并且该子网内有至少三台主机,分别是 `10.0.0.1`、`10.0.0.2` 和 `10.0.0.3`。路由器的左侧连接的是 WAN,WAN 侧接口的 IP 地址为 `138.76.29.7`。
首先,针对以上信息,我们有如下事实需要说明:
-1. 路由器的右侧子网的网络号为`10.0.0/24`,主机号为`10.0.0/8`,三台主机地址,以及路由器的 LAN 侧接口地址,均由 DHCP 协议规定。而且,该 DHCP 运行在路由器内部(路由器自维护一个小 DHCP 服务器),从而为子网内提供 DHCP 服务。
+1. 路由器右侧子网的网络地址为 `10.0.0.0/24`(网络前缀 24 位,主机号占 8 位),三台主机地址以及路由器的 LAN 侧接口地址,均由 DHCP 协议规定。而且,该 DHCP 运行在路由器内部(路由器自维护一个小 DHCP 服务器),从而为子网内提供 DHCP 服务。
2. 路由器的 WAN 侧接口地址同样由 DHCP 协议规定,但该地址是路由器从 ISP(网络服务提供商)处获得,也就是该 DHCP 通常运行在路由器所在区域的 DHCP 服务器上。
现在,路由器内部还运行着 NAT 协议,从而为 LAN-WAN 间通信提供地址转换服务。为此,一个很重要的结构是 **NAT 转换表**。为了说明 NAT 的运行细节,假设有以下请求发生:
-1. 主机`10.0.0.1`向 IP 地址为`128.119.40.186`的 Web 服务器(端口 80)发送了 HTTP 请求(如请求页面)。此时,主机`10.0.0.1`将随机指派一个端口,如`3345`,作为本次请求的源端口号,将该请求发送到路由器中(目的地址将是`128.119.40.186`,但会先到达`10.0.0.4`)。
-2. `10.0.0.4`即路由器的 LAN 接口收到`10.0.0.1`的请求。路由器将为该请求指派一个新的源端口号,如`5001`,并将请求报文发送给 WAN 接口`138.76.29.7`。同时,在 NAT 转换表中记录一条转换记录**138.76.29.7:5001——10.0.0.1:3345**。
-3. 请求报文到达 WAN 接口,继续向目的主机`128.119.40.186`发送。
+1. 主机 `10.0.0.1` 向 IP 地址为 `128.119.40.186` 的 Web 服务器(端口 80)发送了 HTTP 请求(如请求页面)。此时,主机 `10.0.0.1` 将随机指派一个端口,如 `3345`,作为本次请求的源端口号,将该请求发送到路由器中(目的地址将是 `128.119.40.186`,但会先到达 `10.0.0.4`)。
+2. `10.0.0.4` 即路由器的 LAN 接口收到 `10.0.0.1` 的请求。路由器将为该请求指派一个新的源端口号,如 `5001`,并将请求报文发送给 WAN 接口 `138.76.29.7`。同时,在 NAT 转换表中记录一条转换记录 **138.76.29.7:5001——10.0.0.1:3345**。
+3. 请求报文到达 WAN 接口,继续向目的主机 `128.119.40.186` 发送。
之后,将会有如下响应发生:
-1. 主机`128.119.40.186`收到请求,构造响应报文,并将其发送给目的地`138.76.29.7:5001`。
-2. 响应报文到达路由器的 WAN 接口。路由器查询 NAT 转换表,发现`138.76.29.7:5001`在转换表中有记录,从而将其目的地址和目的端口转换成为`10.0.0.1:3345`,再发送到`10.0.0.4`上。
-3. 被转换的响应报文到达路由器的 LAN 接口,继而被转发至目的地`10.0.0.1`。
+1. 主机 `128.119.40.186` 收到请求,构造响应报文,并将其发送给目的地 `138.76.29.7:5001`。
+2. 响应报文到达路由器的 WAN 接口。路由器查询 NAT 转换表,发现 `138.76.29.7:5001` 在转换表中有记录,从而将其目的地址和目的端口转换成为 `10.0.0.1:3345`,再发送到 `10.0.0.4` 上。
+3. 被转换的响应报文到达路由器的 LAN 接口,继而被转发至目的地 `10.0.0.1`。
@@ -45,7 +61,7 @@ SOHO 子网的“代理人”,也就是和外界的窗口,通常由路由器
针对以上过程,有以下几个重点需要强调:
1. 当请求报文到达路由器,并被指定了新端口号时,由于端口号有 16 位,因此,通常来说,一个路由器管理的 LAN 中的最大主机数 $≈65500$($2^{16}$ 的地址空间),但通常 SOHO 子网内不会有如此多的主机数量。
-2. 对于目的服务器来说,从来不知道“到底是哪个主机给我发送的请求”,它只知道是来自`138.76.29.7:5001`的路由器转发的请求。因此,可以说,**路由器在 WAN 和 LAN 之间起到了屏蔽作用**,所有内部主机发送到外部的报文,都具有同一个 IP 地址(不同的端口号),所有外部发送到内部的报文,也都只有一个目的地(不同端口号),是经过了 NAT 转换后,外部报文才得以正确地送达内部主机。
+2. 对于目的服务器来说,从来不知道“到底是哪个主机给我发送的请求”,它只知道是来自 `138.76.29.7:5001` 的路由器转发的请求。因此,可以说,**路由器在 WAN 和 LAN 之间起到了屏蔽作用**,所有内部主机发送到外部的报文,都具有同一个 IP 地址(不同的端口号),所有外部发送到内部的报文,也都只有一个目的地(不同端口号),是经过了 NAT 转换后,外部报文才得以正确地送达内部主机。
3. 在报文穿过路由器,发生 NAT 转换时,如果 LAN 主机 IP 已经在 NAT 转换表中注册过了,则不需要路由器新指派端口,而是直接按照转换记录穿过路由器。同理,外部报文发送至内部时也如此。
总结 NAT 协议的特点,有以下几点:
diff --git a/docs/cs-basics/network/network-attack-means.md b/docs/cs-basics/network/network-attack-means.md
index 748999d6eba..f850e36dbb3 100644
--- a/docs/cs-basics/network/network-attack-means.md
+++ b/docs/cs-basics/network/network-attack-means.md
@@ -1,69 +1,83 @@
---
-title: 网络攻击常见手段总结
+title: 网络攻击常见手段总结(安全)
+description: 总结常见 TCP/IP 攻击与防护思路,覆盖 DDoS、IP/ARP 欺骗、中间人等手段,强调工程防护实践。
category: 计算机基础
tag:
- 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: 网络攻击,DDoS,IP 欺骗,ARP 欺骗,中间人攻击,扫描,防护
---
> 本文整理完善自[TCP/IP 常见攻击手段 - 暖蓝笔记 - 2021](https://mp.weixin.qq.com/s/AZwWrOlLxRSSi-ywBgZ0fA)这篇文章。
-这篇文章的内容主要是介绍 TCP/IP 常见攻击手段,尤其是 DDoS 攻击,也会补充一些其他的常见网络攻击手段。
+TCP/IP 协议栈追求互联互通,但很多机制在设计之初并没有把今天的攻击规模和对抗强度都考虑进去。
+
+IP 欺骗、SYN Flood、DDoS、ARP 欺骗、DNS 劫持这些攻击,表面上各不相同,本质上都在利用网络协议里的信任假设、资源消耗点或解析链路。
+
+这篇文章主要回答几个问题:
+
+1. TCP/IP 常见攻击手段分别利用了什么机制?
+2. IP 欺骗、SYN Flood、DDoS 等攻击大致是怎么发生的?
+3. 常见网络攻击会造成哪些影响?
+4. 面对这些攻击,通常有哪些基础防御思路?
## IP 欺骗
-### IP 是什么?
+### IP 是什么?
在网络中,所有的设备都会分配一个地址。这个地址就仿佛小蓝的家地址「**多少号多少室**」,这个号就是分配给整个子网的,「**室**」对应的号码即分配给子网中计算机的,这就是网络中的地址。「号」对应的号码为网络号,「**室**」对应的号码为主机号,这个地址的整体就是 **IP 地址**。
### 通过 IP 地址我们能知道什么?
-通过 IP 地址,我们就可以知道判断访问对象服务器的位置,从而将消息发送到服务器。一般发送者发出的消息首先经过子网的集线器,转发到最近的路由器,然后根据路由位置访问下一个路由器的位置,直到终点
+通过 IP 地址,我们就可以判断访问对象服务器的位置,从而将消息发送到服务器。一般发送者发出的消息首先经过子网的集线器,转发到最近的路由器,然后根据路由位置访问下一个路由器的位置,直到终点。
-**IP 头部格式** :
+**IP 头部格式**:
-
+
### IP 欺骗技术是什么?
骗呗,拐骗,诱骗!
-IP 欺骗技术就是**伪造**某台主机的 IP 地址的技术。通过 IP 地址的伪装使得某台主机能够**伪装**另外的一台主机,而这台主机往往具有某种特权或者被另外的主机所信任。
+IP 欺骗技术就是伪造某台主机的 IP 地址的技术。通过 IP 地址的伪装使得某台主机能够伪装另外的一台主机,而这台主机往往具有某种特权或者被另外的主机所信任。
假设现在有一个合法用户 **(1.1.1.1)** 已经同服务器建立正常的连接,攻击者构造攻击的 TCP 数据,伪装自己的 IP 为 **1.1.1.1**,并向服务器发送一个带有 RST 位的 TCP 数据段。服务器接收到这样的数据后,认为从 **1.1.1.1** 发送的连接有错误,就会清空缓冲区中建立好的连接。
这时,如果合法用户 **1.1.1.1** 再发送合法数据,服务器就已经没有这样的连接了,该用户就必须从新开始建立连接。攻击时,伪造大量的 IP 地址,向目标发送 RST 数据,使服务器不对合法用户服务。虽然 IP 地址欺骗攻击有着相当难度,但我们应该清醒地意识到,这种攻击非常广泛,入侵往往从这种攻击开始。
-
+
### 如何缓解 IP 欺骗?
虽然无法预防 IP 欺骗,但可以采取措施来阻止伪造数据包渗透网络。**入口过滤** 是防范欺骗的一种极为常见的防御措施,如 BCP38(通用最佳实践文档)所示。入口过滤是一种数据包过滤形式,通常在[网络边缘](https://www.cloudflare.com/learning/serverless/glossary/what-is-edge-computing/)设备上实施,用于检查传入的 IP 数据包并确定其源标头。如果这些数据包的源标头与其来源不匹配或者看上去很可疑,则拒绝这些数据包。一些网络还实施出口过滤,检查退出网络的 IP 数据包,确保这些数据包具有合法源标头,以防止网络内部用户使用 IP 欺骗技术发起出站恶意攻击。
-## SYN Flood(洪水)
+## SYN Flood(洪水)
### SYN Flood 是什么?
-SYN Flood 是互联网上最原始、最经典的 DDoS(Distributed Denial of Service,分布式拒绝服务)攻击之一,旨在耗尽可用服务器资源,致使服务器无法传输合法流量
+SYN Flood 是互联网上最原始、最经典的 DDoS(Distributed Denial of Service,分布式拒绝服务)攻击之一,旨在耗尽可用服务器资源,致使服务器无法传输合法流量。
SYN Flood 利用了 TCP 协议的三次握手机制,攻击者通常利用工具或者控制僵尸主机向服务器发送海量的变源 IP 地址或变源端口的 TCP SYN 报文,服务器响应了这些报文后就会生成大量的半连接,当系统资源被耗尽后,服务器将无法提供正常的服务。
-增加服务器性能,提供更多的连接能力对于 SYN Flood 的海量报文来说杯水车薪,防御 SYN Flood 的关键在于判断哪些连接请求来自于真实源,屏蔽非真实源的请求以保障正常的业务请求能得到服务。
+增加服务器性能、提供更多的连接能力对于 SYN Flood 的海量报文来说杯水车薪。防御 SYN Flood 的关键在于判断哪些连接请求来自于真实源,屏蔽非真实源的请求以保障正常的业务请求能得到服务。
-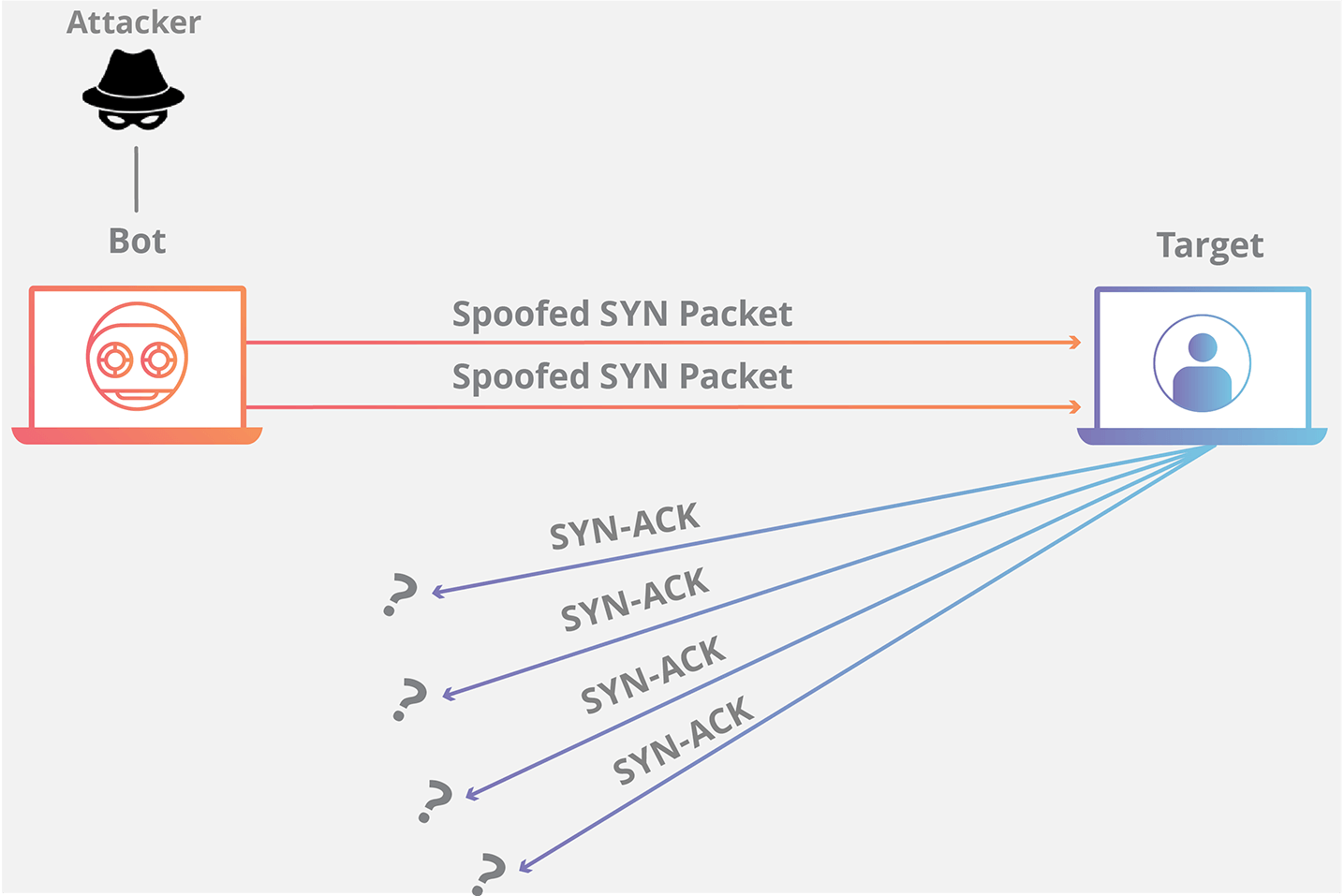
+
### TCP SYN Flood 攻击原理是什么?
**TCP SYN Flood** 攻击利用的是 **TCP** 的三次握手(**SYN -> SYN/ACK -> ACK**),假设连接发起方是 A,连接接受方是 B,即 B 在某个端口(**Port**)上监听 A 发出的连接请求,过程如下图所示,左边是 A,右边是 B。
-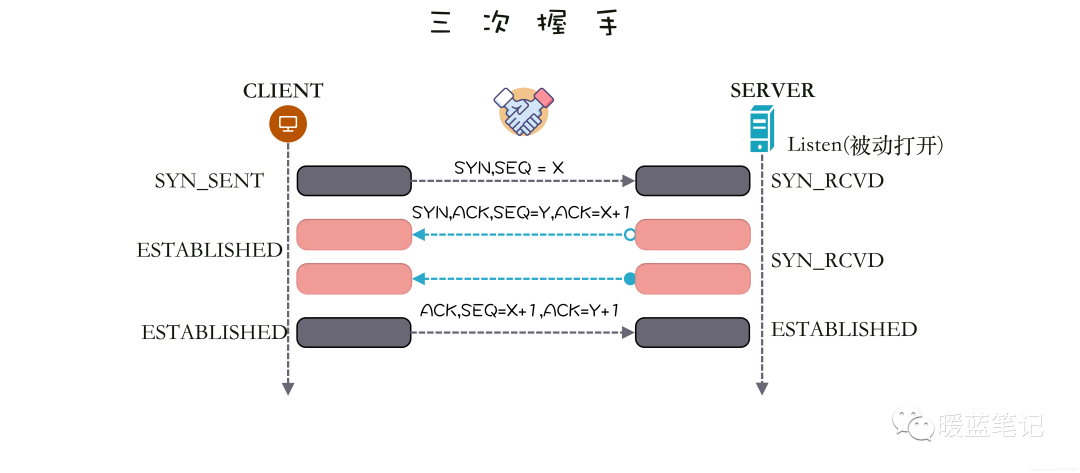
+
-A 首先发送 **SYN**(Synchronization)消息给 B,要求 B 做好接收数据的准备;B 收到后反馈 **SYN-ACK**(Synchronization-Acknowledgement) 消息给 A,这个消息的目的有两个:
+A 首先发送 **SYN**(Synchronization)消息给 B,要求 B 做好接收数据的准备;B 收到后反馈 **SYN-ACK**(Synchronization-Acknowledgement)消息给 A,这个消息的目的有两个:
- 向 A 确认已做好接收数据的准备,
-- 同时要求 A 也做好接收数据的准备,此时 B 已向 A 确认好接收状态,并等待 A 的确认,连接处于**半开状态(Half-Open)**,顾名思义只开了一半;A 收到后再次发送 **ACK** (Acknowledgement) 消息给 B,向 B 确认也做好了接收数据的准备,至此三次握手完成,「**连接**」就建立了,
+- 同时要求 A 也做好接收数据的准备,此时 B 已向 A 确认好接收状态,并等待 A 的确认,连接处于**半开状态(Half-Open)**,顾名思义只开了一半;A 收到后再次发送 **ACK**(Acknowledgement)消息给 B,向 B 确认也做好了接收数据的准备,至此三次握手完成,「**连接**」就建立了,
-大家注意到没有,最关键的一点在于双方是否都按对方的要求进入了**可以接收消息**的状态。而这个状态的确认主要是双方将要使用的**消息序号(**SequenceNum),**TCP** 为保证消息按发送顺序抵达接收方的上层应用,需要用**消息序号**来标记消息的发送先后顺序的。
+大家注意到没有,最关键的一点在于双方是否都按对方的要求进入了**可以接收消息**的状态。而这个状态的确认主要是双方将要使用的**消息序号(**SequenceNum),**TCP** 为保证消息按发送顺序抵达接收方的上层应用,需要用**消息序号**来标记消息的发送先后顺序的。
-**TCP**是「**双工**」(Duplex)连接,同时支持双向通信,也就是双方同时可向对方发送消息,其中 **SYN** 和 **SYN-ACK** 消息开启了 A→B 的单向通信通道(B 获知了 A 的消息序号);**SYN-ACK** 和 **ACK** 消息开启了 B→A 单向通信通道(A 获知了 B 的消息序号)。
+**TCP**是「**双工**」(Duplex)连接,同时支持双向通信,也就是双方同时可向对方发送消息,其中 **SYN** 和 **SYN-ACK** 消息开启了 A→B 的单向通信通道(B 获知了 A 的消息序号);**SYN-ACK** 和 **ACK** 消息开启了 B→A 单向通信通道(A 获知了 B 的消息序号)。
上面讨论的是双方在诚实守信,正常情况下的通信。
@@ -71,16 +85,16 @@ A 首先发送 **SYN**(Synchronization)消息给 B,要求 B 做好接收
假设 B 通过某 **TCP** 端口提供服务,B 在收到 A 的 **SYN** 消息时,积极的反馈了 **SYN-ACK** 消息,使连接进入**半开状态**,因为 B 不确定自己发给 A 的 **SYN-ACK** 消息或 A 反馈的 ACK 消息是否会丢在半路,所以会给每个待完成的半开连接都设一个**Timer**,如果超过时间还没有收到 A 的 **ACK** 消息,则重新发送一次 **SYN-ACK** 消息给 A,直到重试超过一定次数时才会放弃。
-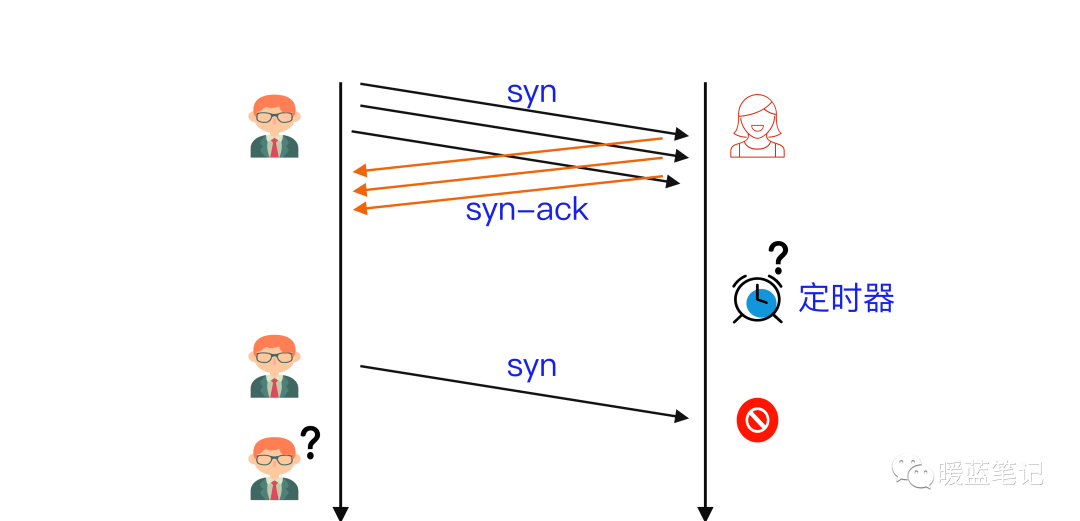
+
B 为帮助 A 能顺利连接,需要**分配内核资源**维护半开连接,那么当 B 面临海量的连接 A 时,如上图所示,**SYN Flood** 攻击就形成了。攻击方 A 可以控制肉鸡向 B 发送大量 SYN 消息但不响应 ACK 消息,或者干脆伪造 SYN 消息中的 **Source IP**,使 B 反馈的 **SYN-ACK** 消息石沉大海,导致 B 被大量注定不能完成的半开连接占据,直到资源耗尽,停止响应正常的连接请求。
### SYN Flood 的常见形式有哪些?
-**恶意用户可通过三种不同方式发起 SYN Flood 攻击**:
+恶意用户可通过三种不同方式发起 SYN Flood 攻击:
1. **直接攻击:** 不伪造 IP 地址的 SYN 洪水攻击称为直接攻击。在此类攻击中,攻击者完全不屏蔽其 IP 地址。由于攻击者使用具有真实 IP 地址的单一源设备发起攻击,因此很容易发现并清理攻击者。为使目标机器呈现半开状态,黑客将阻止个人机器对服务器的 SYN-ACK 数据包做出响应。为此,通常采用以下两种方式实现:部署防火墙规则,阻止除 SYN 数据包以外的各类传出数据包;或者,对传入的所有 SYN-ACK 数据包进行过滤,防止其到达恶意用户机器。实际上,这种方法很少使用(即便使用过也不多见),因为此类攻击相当容易缓解 – 只需阻止每个恶意系统的 IP 地址。哪怕攻击者使用僵尸网络(如 [Mirai 僵尸网络](https://www.cloudflare.com/learning/ddos/glossary/mirai-botnet/)),通常也不会刻意屏蔽受感染设备的 IP。
-2. **欺骗攻击:** 恶意用户还可以伪造其发送的各个 SYN 数据包的 IP 地址,以便阻止缓解措施并加大身份暴露难度。虽然数据包可能经过伪装,但还是可以通过这些数据包追根溯源。此类检测工作很难开展,但并非不可实现;特别是,如果 Internet 服务提供商 (ISP) 愿意提供帮助,则更容易实现。
+2. **欺骗攻击:** 恶意用户还可以伪造其发送的各个 SYN 数据包的 IP 地址,以便阻止缓解措施并加大身份暴露难度。虽然数据包可能经过伪装,但还是可以通过这些数据包追根溯源。此类检测工作很难开展,但并非不可实现;特别是,如果 Internet 服务提供商(ISP)愿意提供帮助,则更容易实现。
3. **分布式攻击(DDoS):** 如果使用僵尸网络发起攻击,则追溯攻击源头的可能性很低。随着混淆级别的攀升,攻击者可能还会命令每台分布式设备伪造其发送数据包的 IP 地址。哪怕攻击者使用僵尸网络(如 Mirai 僵尸网络),通常也不会刻意屏蔽受感染设备的 IP。
### 如何缓解 SYN Flood?
@@ -97,7 +111,7 @@ B 为帮助 A 能顺利连接,需要**分配内核资源**维护半开连接
此策略要求服务器创建 Cookie。为避免在填充积压工作时断开连接,服务器使用 SYN-ACK 数据包响应每一项连接请求,而后从积压工作中删除 SYN 请求,同时从内存中删除请求,保证端口保持打开状态并做好重新建立连接的准备。如果连接是合法请求并且已将最后一个 ACK 数据包从客户端机器发回服务器,服务器将重建(存在一些限制)SYN 积压工作队列条目。虽然这项缓解措施势必会丢失一些 TCP 连接信息,但好过因此导致对合法用户发起拒绝服务攻击。
-## UDP Flood(洪水)
+## UDP Flood(洪水)
### UDP Flood 是什么?
@@ -118,19 +132,19 @@ B 为帮助 A 能顺利连接,需要**分配内核资源**维护半开连接
由于目标服务器利用资源检查并响应每个接收到的 **UDP** 数据包的结果,当接收到大量 **UDP** 数据包时,目标的资源可能会迅速耗尽,导致对正常流量的拒绝服务。
-
+
-### 如何缓解 UDP Flooding?
+### 如何缓解 UDP Flood?
大多数操作系统部分限制了 **ICMP** 报文的响应速率,以中断需要 ICMP 响应的 **DDoS** 攻击。这种缓解的一个缺点是在攻击过程中,合法的数据包也可能被过滤。如果 **UDP Flood** 的容量足够高以使目标服务器的防火墙的状态表饱和,则在服务器级别发生的任何缓解都将不足以应对目标设备上游的瓶颈。
-## HTTP Flood(洪水)
+## HTTP Flood(洪水)
### HTTP Flood 是什么?
HTTP Flood 是一种大规模的 DDoS(Distributed Denial of Service,分布式拒绝服务)攻击,旨在利用 HTTP 请求使目标服务器不堪重负。目标因请求而达到饱和,且无法响应正常流量后,将出现拒绝服务,拒绝来自实际用户的其他请求。
-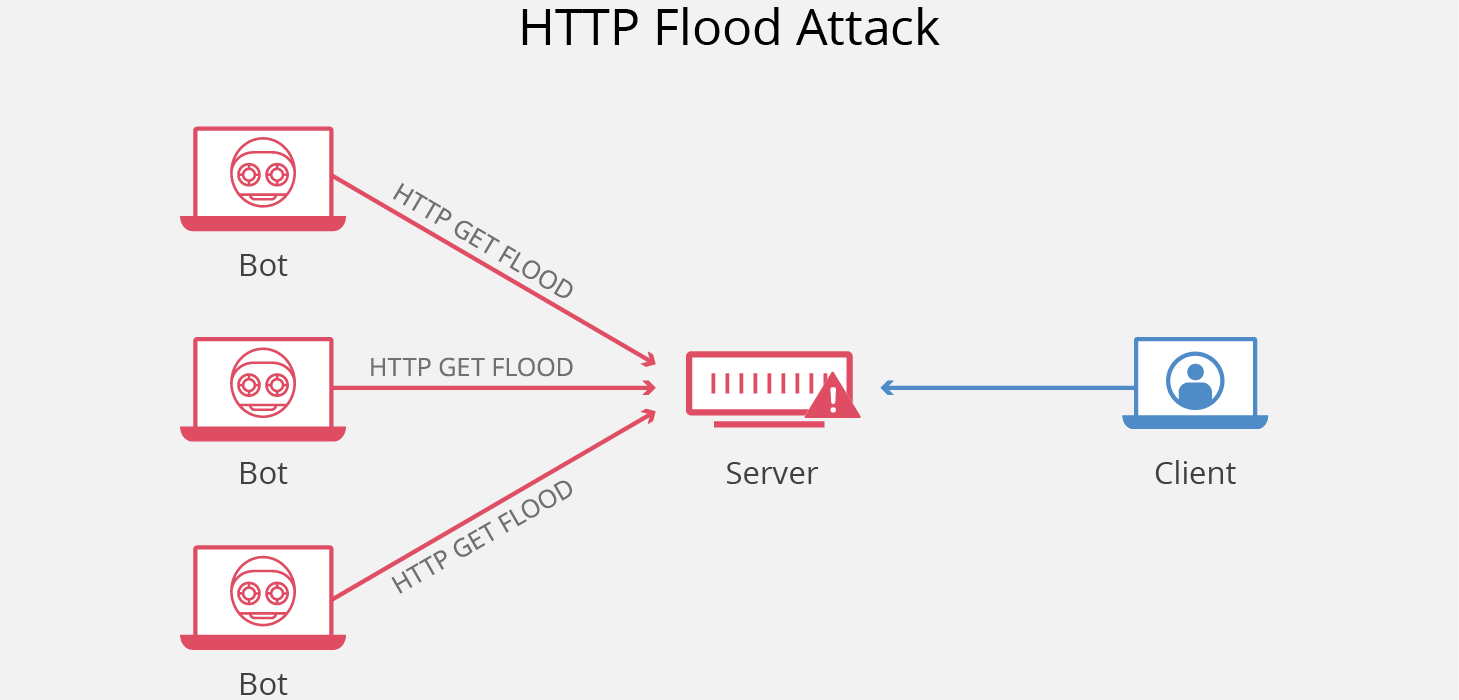
+
### HTTP Flood 的攻击原理是什么?
@@ -147,29 +161,29 @@ HTTP 洪水攻击有两种:
如前所述,缓解第 7 层攻击非常复杂,而且通常要从多方面进行。一种方法是对发出请求的设备实施质询,以测试它是否是机器人,这与在线创建帐户时常用的 CAPTCHA 测试非常相似。通过提出 JavaScript 计算挑战之类的要求,可以缓解许多攻击。
-其他阻止 HTTP 洪水攻击的途径包括使用 Web 应用程序防火墙 (WAF)、管理 IP 信誉数据库以跟踪和有选择地阻止恶意流量,以及由工程师进行动态分析。Cloudflare 具有超过 2000 万个互联网设备的规模优势,能够分析来自各种来源的流量并通过快速更新的 WAF 规则和其他防护策略来缓解潜在的攻击,从而消除应用程序层 DDoS 流量。
+其他阻止 HTTP 洪水攻击的途径包括使用 Web 应用程序防火墙(WAF)、管理 IP 信誉数据库以跟踪和有选择地阻止恶意流量,以及由工程师进行动态分析。Cloudflare 具有超过 2000 万个互联网设备的规模优势,能够分析来自各种来源的流量并通过快速更新的 WAF 规则和其他防护策略来缓解潜在的攻击,从而消除应用程序层 DDoS 流量。
-## DNS Flood(洪水)
+## DNS Flood(洪水)
### DNS Flood 是什么?
-域名系统(DNS)服务器是互联网的“电话簿“;互联网设备通过这些服务器来查找特定 Web 服务器以便访问互联网内容。DNS Flood 攻击是一种分布式拒绝服务(DDoS)攻击,攻击者用大量流量淹没某个域的 DNS 服务器,以尝试中断该域的 DNS 解析。如果用户无法找到电话簿,就无法查找到用于调用特定资源的地址。通过中断 DNS 解析,DNS Flood 攻击将破坏网站、API 或 Web 应用程序响应合法流量的能力。很难将 DNS Flood 攻击与正常的大流量区分开来,因为这些大规模流量往往来自多个唯一地址,查询该域的真实记录,模仿合法流量。
+域名系统(DNS)服务器是互联网的“电话簿”;互联网设备通过这些服务器来查找特定 Web 服务器以便访问互联网内容。DNS Flood 攻击是一种分布式拒绝服务(DDoS)攻击,攻击者用大量流量淹没某个域的 DNS 服务器,以尝试中断该域的 DNS 解析。如果用户无法找到电话簿,就无法查找到用于调用特定资源的地址。通过中断 DNS 解析,DNS Flood 攻击将破坏网站、API 或 Web 应用程序响应合法流量的能力。很难将 DNS Flood 攻击与正常的大流量区分开来,因为这些大规模流量往往来自多个唯一地址,查询该域的真实记录,模仿合法流量。
### DNS Flood 的攻击原理是什么?
-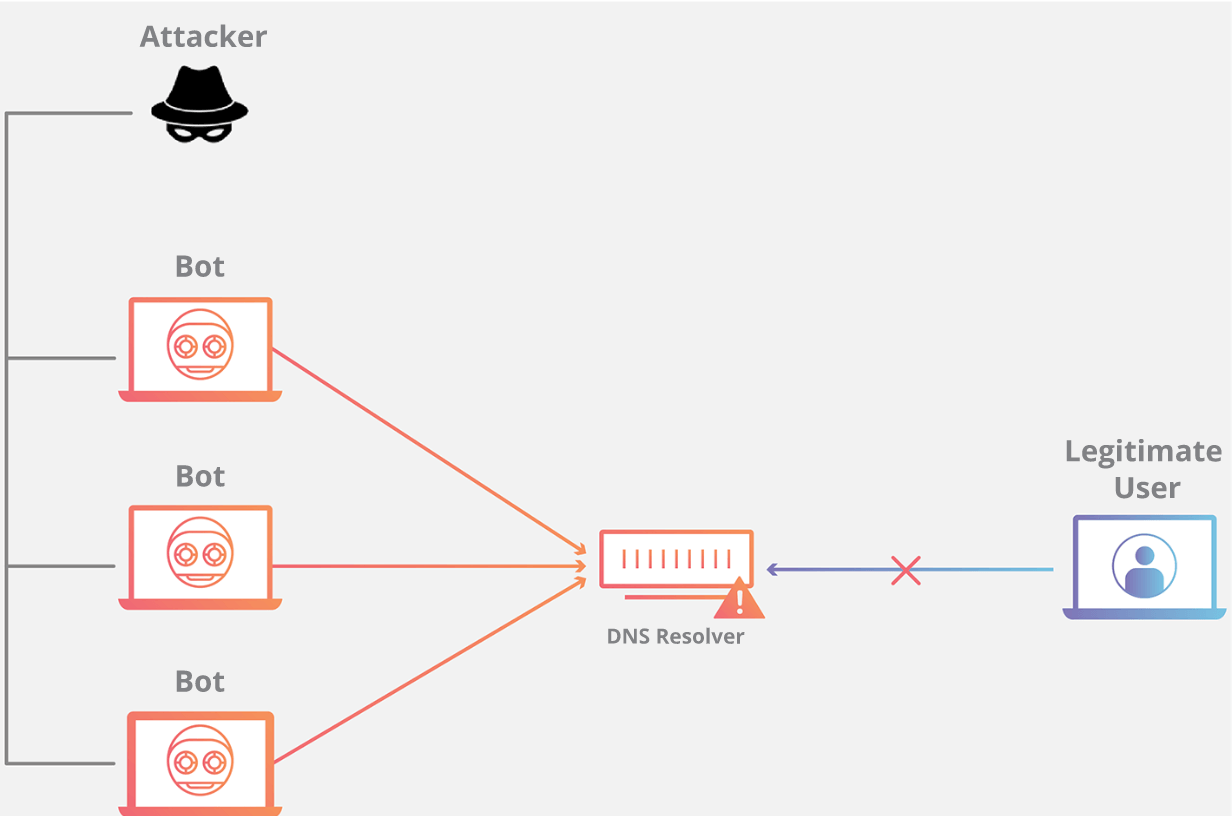
+
域名系统的功能是将易于记忆的名称(例如 example.com)转换成难以记住的网站服务器地址(例如 192.168.0.1),因此成功攻击 DNS 基础设施将导致大多数人无法使用互联网。DNS Flood 攻击是一种相对较新的基于 DNS 的攻击,这种攻击是在高带宽[物联网(IoT)](https://www.cloudflare.com/learning/ddos/glossary/internet-of-things-iot/)[僵尸网络](https://www.cloudflare.com/learning/ddos/what-is-a-ddos-botnet/)(如 [Mirai](https://www.cloudflare.com/learning/ddos/glossary/mirai-botnet/))兴起后激增的。DNS Flood 攻击使用 IP 摄像头、DVR 盒和其他 IoT 设备的高带宽连接直接淹没主要提供商的 DNS 服务器。来自 IoT 设备的大量请求淹没 DNS 提供商的服务,阻止合法用户访问提供商的 DNS 服务器。
DNS Flood 攻击不同于 [DNS 放大攻击](https://www.cloudflare.com/zh-cn/learning/ddos/dns-amplification-ddos-attack/)。与 DNS Flood 攻击不同,DNS 放大攻击反射并放大不安全 DNS 服务器的流量,以便隐藏攻击的源头并提高攻击的有效性。DNS 放大攻击使用连接带宽较小的设备向不安全的 DNS 服务器发送无数请求。这些设备对非常大的 DNS 记录发出小型请求,但在发出请求时,攻击者伪造返回地址为目标受害者。这种放大效果让攻击者能借助有限的攻击资源来破坏较大的目标。
-### 如何防护 DNS Flood?
+### 如何防护 DNS Flood?
DNS Flood 对传统上基于放大的攻击方法做出了改变。借助轻易获得的高带宽僵尸网络,攻击者现能针对大型组织发动攻击。除非被破坏的 IoT 设备得以更新或替换,否则抵御这些攻击的唯一方法是使用一个超大型、高度分布式的 DNS 系统,以便实时监测、吸收和阻止攻击流量。
## TCP 重置攻击
-在 **TCP** 重置攻击中,攻击者通过向通信的一方或双方发送伪造的消息,告诉它们立即断开连接,从而使通信双方连接中断。正常情况下,如果客户端收发现到达的报文段对于相关连接而言是不正确的,**TCP** 就会发送一个重置报文段,从而导致 **TCP** 连接的快速拆卸。
+在 **TCP** 重置攻击中,攻击者通过向通信的一方或双方发送伪造的消息,告诉它们立即断开连接,从而使通信双方连接中断。正常情况下,如果客户端发现到达的报文段对于相关连接而言是不正确的,**TCP** 就会发送一个重置报文段,从而导致 **TCP** 连接的快速拆卸。
**TCP** 重置攻击利用这一机制,通过向通信方发送伪造的重置报文段,欺骗通信双方提前关闭 TCP 连接。如果伪造的重置报文段完全逼真,接收者就会认为它有效,并关闭 **TCP** 连接,防止连接被用来进一步交换信息。服务端可以创建一个新的 **TCP** 连接来恢复通信,但仍然可能会被攻击者重置连接。万幸的是,攻击者需要一定的时间来组装和发送伪造的报文,所以一般情况下这种攻击只对长连接有杀伤力,对于短连接而言,你还没攻击呢,人家已经完成了信息交换。
@@ -184,7 +198,7 @@ DNS Flood 对传统上基于放大的攻击方法做出了改变。借助轻易
- 嗅探通信双方的交换信息。
- 截获一个 `ACK` 标志位置位 1 的报文段,并读取其 `ACK` 号。
- 伪造一个 TCP 重置报文段(`RST` 标志位置为 1),其序列号等于上面截获的报文的 `ACK` 号。这只是理想情况下的方案,假设信息交换的速度不是很快。大多数情况下为了增加成功率,可以连续发送序列号不同的重置报文。
-- 将伪造的重置报文发送给通信的一方或双方,时其中断连接。
+- 将伪造的重置报文发送给通信的一方或双方,使其中断连接。
为了实验简单,我们可以使用本地计算机通过 `localhost` 与自己通信,然后对自己进行 TCP 重置攻击。需要以下几个步骤:
@@ -210,26 +224,26 @@ nc 127.0.0.1 8000
该命令会尝试与上面的服务建立连接,在其中一个窗口输入一些字符,就会通过 TCP 连接发送给另一个窗口并打印出来。
-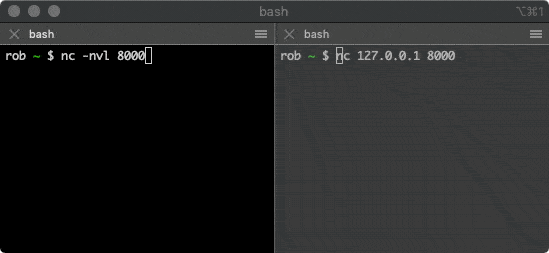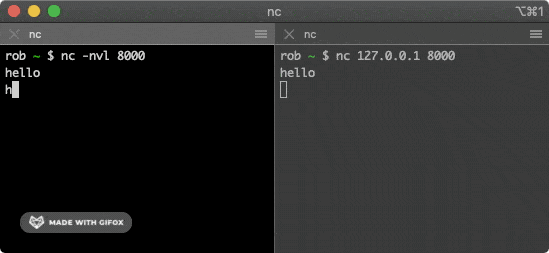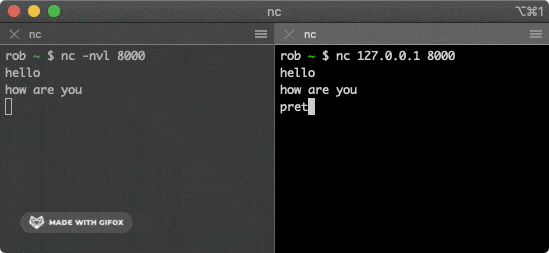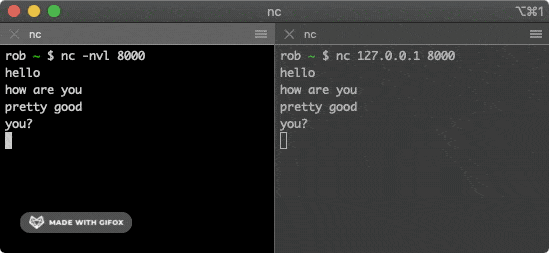
+
> 嗅探流量
编写一个攻击程序,使用 Python 网络库 `scapy` 来读取两个终端窗口之间交换的数据,并将其打印到终端上。代码比较长,下面为一部份,完整代码后台回复 TCP 攻击,代码的核心是调用 `scapy` 的嗅探方法:
-
+
这段代码告诉 `scapy` 在 `lo0` 网络接口上嗅探数据包,并记录所有 TCP 连接的详细信息。
-- **iface** : 告诉 scapy 在 `lo0`(localhost)网络接口上进行监听。
-- **lfilter** : 这是个过滤器,告诉 scapy 忽略所有不属于指定的 TCP 连接(通信双方皆为 `localhost`,且端口号为 `8000`)的数据包。
-- **prn** : scapy 通过这个函数来操作所有符合 `lfilter` 规则的数据包。上面的例子只是将数据包打印到终端,下文将会修改函数来伪造重置报文。
-- **count** : scapy 函数返回之前需要嗅探的数据包数量。
+- **iface**:告诉 scapy 在 `lo0`(localhost)网络接口上进行监听。
+- **lfilter**:这是个过滤器,告诉 scapy 忽略所有不属于指定的 TCP 连接(通信双方皆为 `localhost`,且端口号为 `8000`)的数据包。
+- **prn**:scapy 通过这个函数来操作所有符合 `lfilter` 规则的数据包。上面的例子只是将数据包打印到终端,下文将会修改函数来伪造重置报文。
+- **count**:scapy 函数返回之前需要嗅探的数据包数量。
> 发送伪造的重置报文
下面开始修改程序,发送伪造的 TCP 重置报文来进行 TCP 重置攻击。根据上面的解读,只需要修改 prn 函数就行了,让其检查数据包,提取必要参数,并利用这些参数来伪造 TCP 重置报文并发送。
-例如,假设该程序截获了一个从(`src_ip`, `src_port`)发往 (`dst_ip`, `dst_port`)的报文段,该报文段的 ACK 标志位已置为 1,ACK 号为 `100,000`。攻击程序接下来要做的是:
+例如,假设该程序截获了一个从(`src_ip`, `src_port`)发往(`dst_ip`, `dst_port`)的报文段,该报文段的 ACK 标志位已置为 1,ACK 号为 `100,000`。攻击程序接下来要做的是:
- 由于伪造的数据包是对截获的数据包的响应,所以伪造数据包的源 `IP/Port` 应该是截获数据包的目的 `IP/Port`,反之亦然。
- 将伪造数据包的 `RST` 标志位置为 1,以表示这是一个重置报文。
@@ -248,11 +262,11 @@ nc 127.0.0.1 8000
猪八戒要向小蓝表白,于是写了一封信给小蓝,结果第三者小黑拦截到了这封信,把这封信进行了篡改,于是乎在他们之间进行搞破坏行动。这个马文才就是中间人,实施的就是中间人攻击。好我们继续聊聊什么是中间人攻击。
-### 什么是中间人?
+### 什么是中间人?
-攻击中间人攻击英文名叫 Man-in-the-MiddleAttack,简称「MITM 攻击」。指攻击者与通讯的两端分别创建独立的联系,并交换其所收到的数据,使通讯的两端认为他们正在通过一个私密的连接与对方 直接对话,但事实上整个会话都被攻击者完全控制。我们画一张图:
+中间人攻击英文名叫 Man-in-the-Middle Attack,简称「MITM 攻击」。指攻击者与通讯的两端分别创建独立的联系,并交换其所收到的数据,使通讯的两端认为他们正在通过一个私密的连接与对方直接对话,但事实上整个会话都被攻击者完全控制。我们画一张图:
-
+
从这张图可以看到,中间人其实就是攻击者。通过这种原理,有很多实现的用途,比如说,你在手机上浏览不健康网站的时候,手机就会提示你,此网站可能含有病毒,是否继续访问还是做其他的操作等等。
@@ -262,53 +276,53 @@ nc 127.0.0.1 8000
在安全领域有句话:**我们没有办法杜绝网络犯罪,只好想办法提高网络犯罪的成本**。既然没法杜绝这种情况,那我们就想办法提高作案的成本,今天我们就简单了解下基本的网络安全知识,也是面试中的高频面试题了。
-为了避免双方说活不算数的情况,双方引入第三家机构,将合同原文给可信任的第三方机构,只要这个机构不监守自盗,合同就相对安全。
+为了避免双方说话不算数的情况,双方引入第三家机构,将合同原文给可信任的第三方机构,只要这个机构不监守自盗,合同就相对安全。
**如果第三方机构内部不严格或容易出现纰漏?**
-虽然我们将合同原文给第三方机构了,为了防止内部人员的更改,需要采取什么措施呢
+虽然我们将合同原文给第三方机构了,为了防止内部人员的更改,需要采取什么措施呢?
-一种可行的办法是引入 **摘要算法** 。即合同和摘要一起,为了简单的理解摘要。大家可以想象这个摘要为一个函数,这个函数对原文进行了加密,会产生一个唯一的散列值,一旦原文发生一点点变化,那么这个散列值将会变化。
+一种可行的办法是引入 **摘要算法**。即合同和摘要一起,为了简单的理解摘要。大家可以想象这个摘要为一个函数,这个函数对原文进行了加密,会产生一个唯一的散列值,一旦原文发生一点点变化,那么这个散列值将会变化。
#### 有哪些常用的摘要算法呢?
-目前比较常用的加密算法有消息摘要算法和安全散列算法(**SHA**)。**MD5** 是将任意长度的文章转化为一个 128 位的散列值,可是在 2004 年,**MD5** 被证实了容易发生碰撞,即两篇原文产生相同的摘要。这样的话相当于直接给黑客一个后门,轻松伪造摘要。
+目前比较常用的加密算法有消息摘要算法和安全散列算法(**SHA**)。**MD5** 是将任意长度的文章转化为一个 128 位的散列值,可是在 2004 年,**MD5** 被证实了容易发生碰撞,即两篇原文产生相同的摘要。这样的话相当于直接给黑客一个后门,轻松伪造摘要。
-所以在大部分的情况下都会选择 **SHA 算法** 。
+所以在大部分的情况下都会选择 **SHA 算法**。
**出现内鬼了怎么办?**
-看似很安全的场面了,理论上来说杜绝了篡改合同的做法。主要某个员工同时具有修改合同和摘要的权利,那搞事儿就是时间的问题了,毕竟没哪个系统可以完全的杜绝员工接触敏感信息,除非敏感信息都不存在。所以能不能考虑将合同和摘要分开存储呢
+看似很安全的场面了,理论上来说杜绝了篡改合同的做法。主要某个员工同时具有修改合同和摘要的权利,那搞事儿就是时间的问题了,毕竟没哪个系统可以完全的杜绝员工接触敏感信息,除非敏感信息都不存在。所以能不能考虑将合同和摘要分开存储呢?
**那如何确保员工不会修改合同呢?**
-这确实蛮难的,不过办法总比困难多。我们将合同放在双方手中,摘要放在第三方机构,篡改难度进一步加大
+这确实蛮难的,不过办法总比困难多。我们将合同放在双方手中,摘要放在第三方机构,篡改难度进一步加大。
**那么员工万一和某个用户串通好了呢?**
-看来放在第三方的机构还是不好使,同样存在不小风险。所以还需要寻找新的方案,这就出现了 **数字签名和证书**。
+看来放在第三方的机构还是不好使,同样存在不小风险。所以还需要寻找新的方案,这就出现了**数字签名和证书**。
#### 数字证书和签名有什么用?
同样的,举个例子。Sum 和 Mike 两个人签合同。Sum 首先用 **SHA** 算法计算合同的摘要,然后用自己私钥将摘要加密,得到数字签名。Sum 将合同原文、签名,以及公钥三者都交给 Mike
-
+
如果 Sum 想要证明合同是 Mike 的,那么就要使用 Mike 的公钥,将这个签名解密得到摘要 x,然后 Mike 计算原文的 sha 摘要 Y,随后对比 x 和 y,如果两者相等,就认为数据没有被篡改
在这样的过程中,Mike 是不能更改 Sum 的合同,因为要修改合同不仅仅要修改原文还要修改摘要,修改摘要需要提供 Mike 的私钥,私钥即 Sum 独有的密码,公钥即 Sum 公布给他人使用的密码
-总之,公钥加密的数据只能私钥可以解密。私钥加密的数据只有公钥可以解密,这就是 **非对称加密** 。
+总之,公钥加密的数据只能私钥可以解密。私钥加密的数据只有公钥可以解密,这就是 **非对称加密**。
隐私保护?不是吓唬大家,信息是透明的兄 die,不过尽量去维护个人的隐私吧,今天学习对称加密和非对称加密。
-大家先读读这个字"钥",是读"yao",我以前也是,其实读"yue"
+大家先读读这个字“钥”,是读"yao",我以前也是,其实读"yue"
#### 什么是对称加密?
-对称加密,顾名思义,加密方与解密方使用同一钥匙(秘钥)。具体一些就是,发送方通过使用相应的加密算法和秘钥,对将要发送的信息进行加密;对于接收方而言,使用解密算法和相同的秘钥解锁信息,从而有能力阅读信息。
+对称加密,顾名思义,加密方与解密方使用同一钥匙(秘钥)。具体一些就是,发送方通过使用相应的加密算法和秘钥,对将要发送的信息进行加密;对于接收方而言,使用解密算法和相同的秘钥解锁信息,从而有能力阅读信息。
-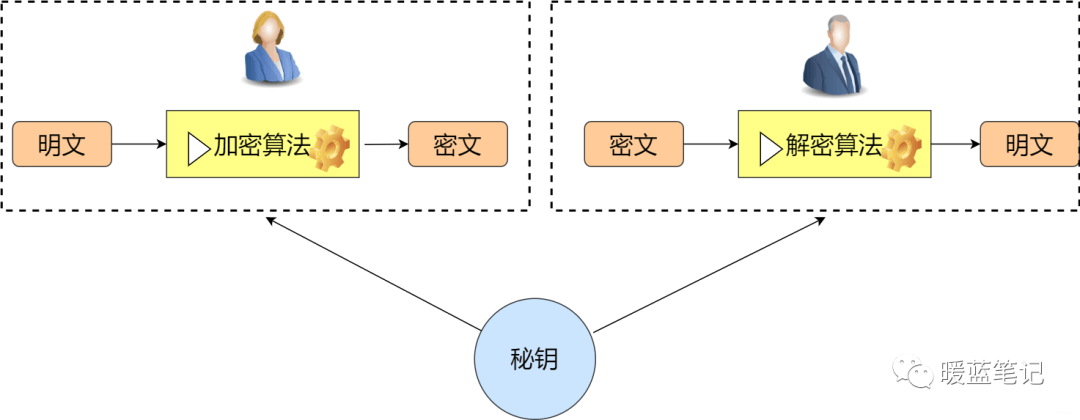
+
#### 常见的对称加密算法有哪些?
@@ -316,42 +330,41 @@ nc 127.0.0.1 8000
DES 使用的密钥表面上是 64 位的,然而只有其中的 56 位被实际用于算法,其余 8 位可以被用于奇偶校验,并在算法中被丢弃。因此,**DES** 的有效密钥长度为 56 位,通常称 **DES** 的密钥长度为 56 位。假设秘钥为 56 位,采用暴力破 Jie 的方式,其秘钥个数为 2 的 56 次方,那么每纳秒执行一次解密所需要的时间差不多 1 年的样子。当然,没人这么干。**DES** 现在已经不是一种安全的加密方法,主要因为它使用的 56 位密钥过短。
-
+
**IDEA**
-国际数据加密算法(International Data Encryption Algorithm)。秘钥长度 128 位,优点没有专利的限制。
+国际数据加密算法(International Data Encryption Algorithm)。秘钥长度 128 位,优点没有专利的限制。
**AES**
-当 DES 被破解以后,没过多久推出了 **AES** 算法,提供了三种长度供选择,128 位、192 位和 256,为了保证性能不受太大的影响,选择 128 即可。
+当 DES 被破解以后,没过多久推出了 **AES** 算法,提供了三种长度供选择,128 位、192 位和 256 位,为了保证性能不受太大的影响,选择 128 即可。
**SM1 和 SM4**
-之前几种都是国外的,我们国内自行研究了国密 **SM1**和 **SM4**。其中 S 都属于国家标准,算法公开。优点就是国家的大力支持和认可
+之前几种都是国外的,我们国内自行研究了国密 **SM1** 和 **SM4**。其中 S 都属于国家标准,算法公开。优点就是国家的大力支持和认可。
**总结**:
-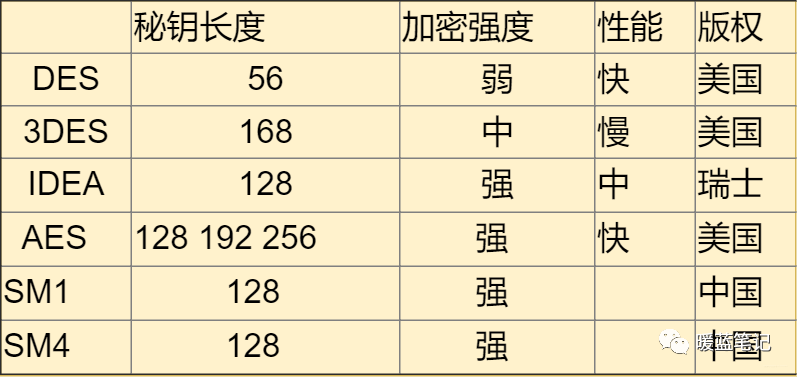
+
#### 常见的非对称加密算法有哪些?
在对称加密中,发送方与接收方使用相同的秘钥。那么在非对称加密中则是发送方与接收方使用的不同的秘钥。其主要解决的问题是防止在秘钥协商的过程中发生泄漏。比如在对称加密中,小蓝将需要发送的消息加密,然后告诉你密码是 123balala,ok,对于其他人而言,很容易就能劫持到密码是 123balala。那么在非对称的情况下,小蓝告诉所有人密码是 123balala,对于中间人而言,拿到也没用,因为没有私钥。所以,非对称密钥其实主要解决了密钥分发的难题。如下图
-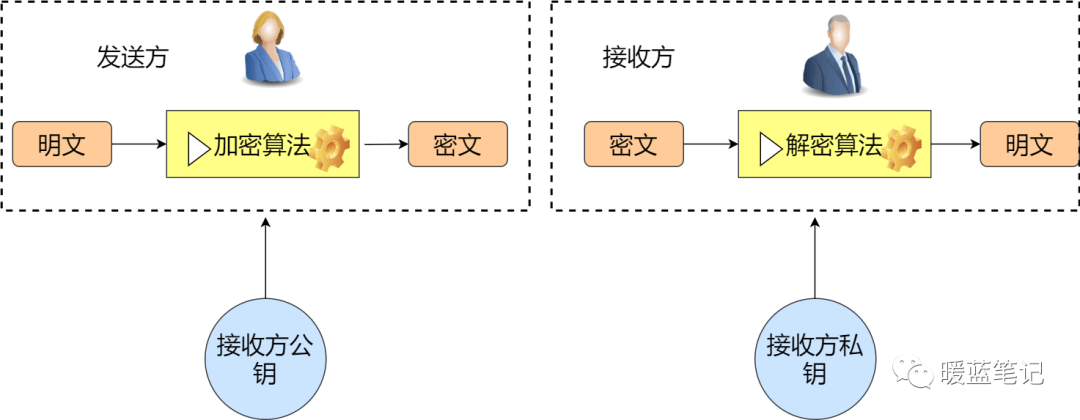
+
-其实我们经常都在使用非对称加密,比如使用多台服务器搭建大数据平台 hadoop,为了方便多台机器设置免密登录,是不是就会涉及到秘钥分发。再比如搭建 docker 集群也会使用相关非对称加密算法。
+其实我们经常都在使用非对称加密,比如使用多台服务器搭建大数据平台 Hadoop,为了方便多台机器设置免密登录,是不是就会涉及到秘钥分发。再比如搭建 Docker 集群也会使用相关非对称加密算法。
常见的非对称加密算法:
-- RSA(RSA 加密算法,RSA Algorithm):优势是性能比较快,如果想要较高的加密难度,需要很长的秘钥。
-
-- ECC:基于椭圆曲线提出。是目前加密强度最高的非对称加密算法
-- SM2:同样基于椭圆曲线问题设计。最大优势就是国家认可和大力支持。
+- RSA(RSA 加密算法,RSA Algorithm):安全性基于大整数分解的计算难度,应用广泛,兼容性好。缺点是性能相对较慢,且密钥越长(如 2048/4096 位)安全性越高,但运算开销也随之增大。
+- ECC:基于椭圆曲线提出,是目前加密强度最高的非对称加密算法。
+- SM2:同样基于椭圆曲线问题设计,最大优势就是国家认可和大力支持。
总结:
-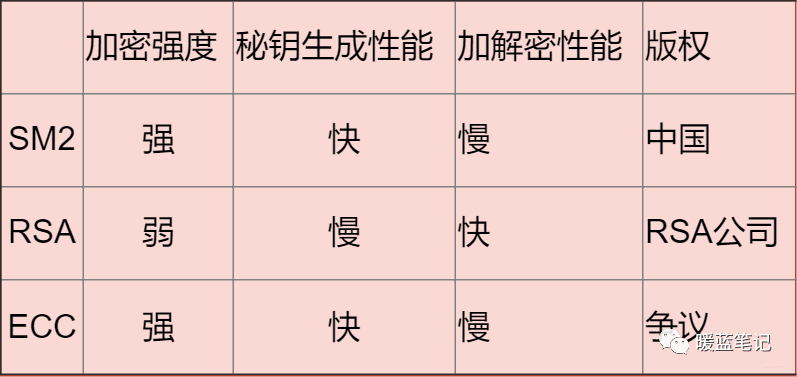
+
#### 常见的散列算法有哪些?
@@ -367,31 +380,31 @@ MD5 可以用来生成一个 128 位的消息摘要,它是目前应用比较
**SM3**
-国密算法**SM3**。加密强度和 SHA-256 算法 相差不多。主要是受到了国家的支持。
+国密算法 **SM3**。加密强度和 SHA-256 算法相差不多。主要是受到了国家的支持。
**总结**:
-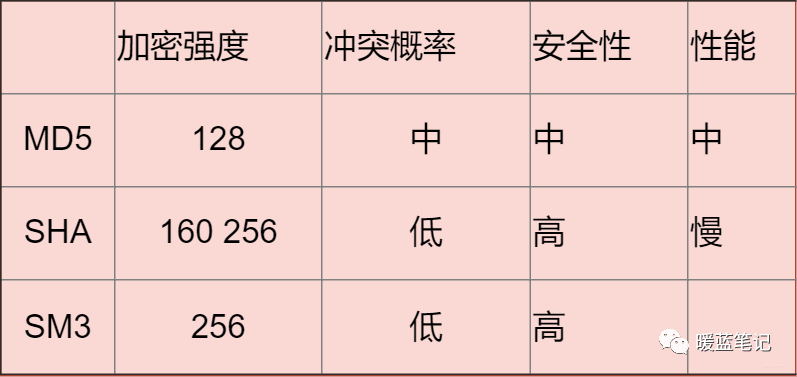
+
-**大部分情况下使用对称加密,具有比较不错的安全性。如果需要分布式进行秘钥分发,考虑非对称。如果不需要可逆计算则散列算法。** 因为这段时间有这方面需求,就看了一些这方面的资料,入坑信息安全,就怕以后洗发水都不用买。谢谢大家查看!
+**大部分情况下使用对称加密,具有比较不错的安全性。如果需要分布式进行秘钥分发,考虑非对称。如果不需要可逆计算则使用散列算法。**
#### 第三方机构和证书机制有什么用?
-问题还有,此时如果 Sum 否认给过 Mike 的公钥和合同,不久 gg 了
+问题还有,此时如果 Sum 否认给过 Mike 的公钥和合同,不久就麻烦了。
-所以需要 Sum 过的话做过的事儿需要足够的信誉,这就引入了 **第三方机构和证书机制** 。
+所以需要 Sum 过的话做过的事儿需要足够的信誉,这就引入了**第三方机构和证书机制**。
-证书之所以会有信用,是因为证书的签发方拥有信用。所以如果 Sum 想让 Mike 承认自己的公钥,Sum 不会直接将公钥给 Mike ,而是提供由第三方机构,含有公钥的证书。如果 Mike 也信任这个机构,法律都认可,那 ik,信任关系成立
+证书之所以会有信用,是因为证书的签发方拥有信用。所以如果 Sum 想让 Mike 承认自己的公钥,Sum 不会直接将公钥给 Mike,而是提供由第三方机构签发的含有公钥的证书。如果 Mike 也信任这个机构,法律都认可,那信任关系成立。
-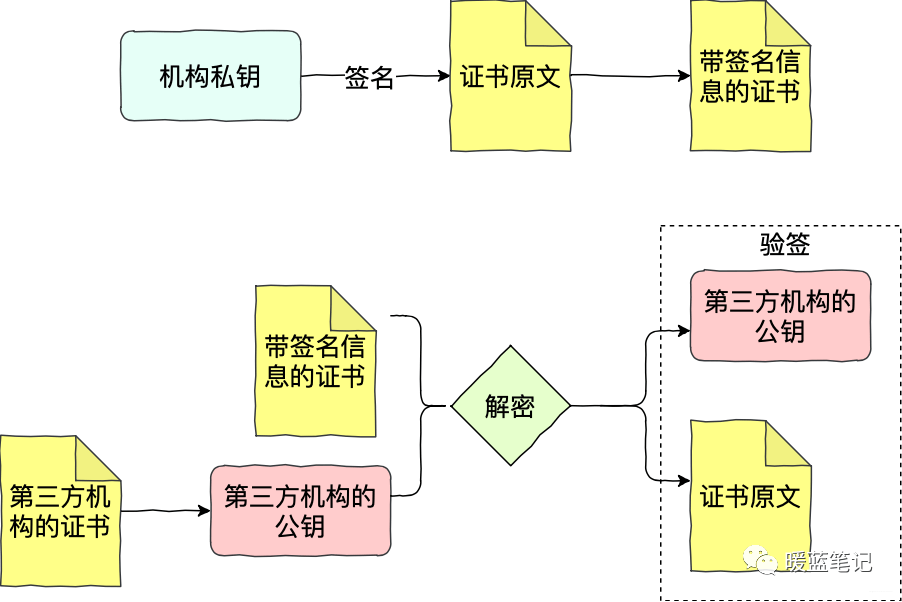
+
如上图所示,Sum 将自己的申请提交给机构,产生证书的原文。机构用自己的私钥签名 Sum 的申请原文(先根据原文内容计算摘要,再用私钥加密),得到带有签名信息的证书。Mike 拿到带签名信息的证书,通过第三方机构的公钥进行解密,获得 Sum 证书的摘要、证书的原文。有了 Sum 证书的摘要和原文,Mike 就可以进行验签。验签通过,Mike 就可以确认 Sum 的证书的确是第三方机构签发的。
-用上面这样一个机制,合同的双方都无法否认合同。这个解决方案的核心在于需要第三方信用服务机构提供信用背书。这里产生了一个最基础的信任链,如果第三方机构的信任崩溃,比如被黑客攻破,那整条信任链条也就断裂了
+用上面这样一个机制,合同的双方都无法否认合同。这个解决方案的核心在于需要第三方信用服务机构提供信用背书。这里产生了一个最基础的信任链,如果第三方机构的信任崩溃,比如被黑客攻破,那整条信任链条也就断裂了。
-为了让这个信任条更加稳固,就需要环环相扣,打造更长的信任链,避免单点信任风险
+为了让这个信任条更加稳固,就需要环环相扣,打造更长的信任链,避免单点信任风险。
-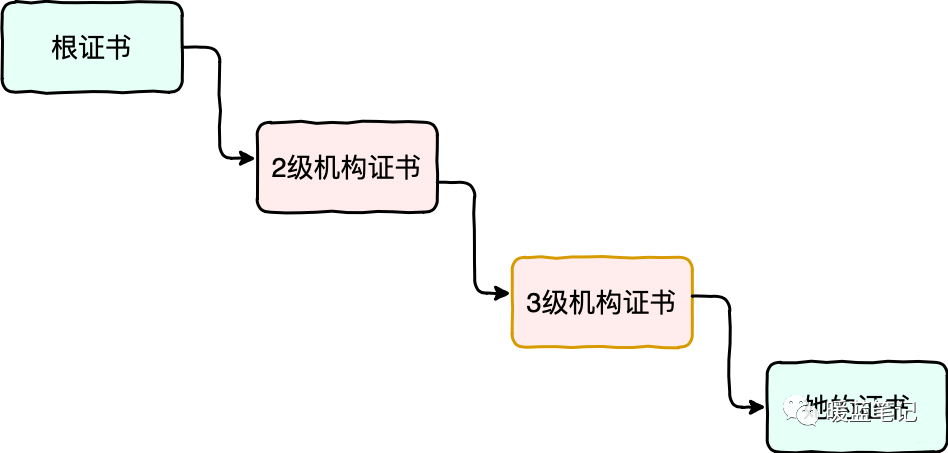
+
上图中,由信誉最好的根证书机构提供根证书,然后根证书机构去签发二级机构的证书;二级机构去签发三级机构的证书;最后有由三级机构去签发 Sum 证书。
@@ -399,15 +412,15 @@ MD5 可以用来生成一个 128 位的消息摘要,它是目前应用比较
如果要验证三级机构证书的合法性,就需要用二级机构的证书去解密三级机构证书的数字签名。
-如果要验证二级结构证书的合法性,就需要用根证书去解密。
+如果要验证二级机构证书的合法性,就需要用根证书去解密。
以上,就构成了一个相对长一些的信任链。如果其中一方想要作弊是非常困难的,除非链条中的所有机构同时联合起来,进行欺诈。
-### 中间人攻击如何避免?
+### 中间人攻击如何避免?
既然知道了中间人攻击的原理也知道了他的危险,现在我们看看如何避免。相信我们都遇到过下面这种状况:
-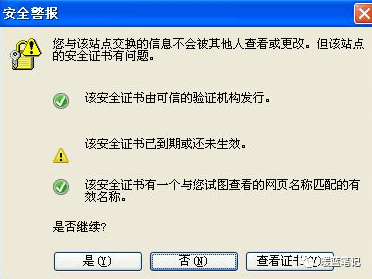
+
出现这个界面的很多情况下,都是遇到了中间人攻击的现象,需要对安全证书进行及时地监测。而且大名鼎鼎的 github 网站,也曾遭遇过中间人攻击:
@@ -416,9 +429,9 @@ MD5 可以用来生成一个 128 位的消息摘要,它是目前应用比较
- 客户端不要轻易相信证书:因为这些证书极有可能是中间人。
- App 可以提前预埋证书在本地:意思是我们本地提前有一些证书,这样其他证书就不能再起作用了。
-## DDOS
+## DDoS
-通过上面的描述,总之即好多种攻击都是 **DDOS** 攻击,所以简单总结下这个攻击相关内容。
+通过上面的描述,前面好多种攻击都属于 DDoS 攻击,所以简单总结一下这个攻击的相关内容。
其实,像全球互联网各大公司,均遭受过大量的 **DDoS**。
@@ -442,7 +455,7 @@ DDos 全名 Distributed Denial of Service,翻译成中文就是**分布式拒
还是拿开的重庆火锅店举例,高防服务器就是我给重庆火锅店增加了两名保安,这两名保安可以让保护店铺不受流氓骚扰,并且还会定期在店铺周围巡逻防止流氓骚扰。
-高防服务器主要是指能独立硬防御 50Gbps 以上的服务器,能够帮助网站拒绝服务攻击,定期扫描网络主节点等,这东西是不错,就是贵~
+高防服务器主要是指能独立硬防御 50Gbps 以上的服务器,能够帮助网站拒绝服务攻击,定期扫描网络主节点等。
#### 黑名单
diff --git a/docs/cs-basics/network/osi-and-tcp-ip-model.md b/docs/cs-basics/network/osi-and-tcp-ip-model.md
index 34092a336b6..76863029821 100644
--- a/docs/cs-basics/network/osi-and-tcp-ip-model.md
+++ b/docs/cs-basics/network/osi-and-tcp-ip-model.md
@@ -1,15 +1,31 @@
---
-title: OSI 和 TCP/IP 网络分层模型详解(基础)
+title: OSI 七层模型与 TCP/IP 四层模型详解
+description: 详解 OSI 与 TCP/IP 的分层模型与职责划分,结合历史与实践对比两者差异与工程取舍。
category: 计算机基础
tag:
- 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: OSI 七层,TCP/IP 四层,分层模型,职责划分,协议栈,对比
---
+网络分层是学习计算机网络的第一张地图。没有这张地图,HTTP、TCP、IP、以太网、DNS 这些概念很容易堆在一起,分不清谁依赖谁、谁负责什么。
+
+常见的两套分层模型是 OSI 七层模型和 TCP/IP 四层模型。前者更适合建立概念框架,后者更贴近互联网实际落地。
+
+这篇文章主要回答几个问题:
+
+1. OSI 七层模型每一层分别做什么?
+2. TCP/IP 四层模型和 OSI 七层模型如何对应?
+3. 为什么 OSI 模型理论完整,但实际没有成为互联网主流实现?
+4. 学习具体网络协议时,为什么要先知道它位于哪一层?
+
## OSI 七层模型
**OSI 七层模型** 是国际标准化组织提出一个网络分层模型,其大体结构以及每一层提供的功能如下图所示:
-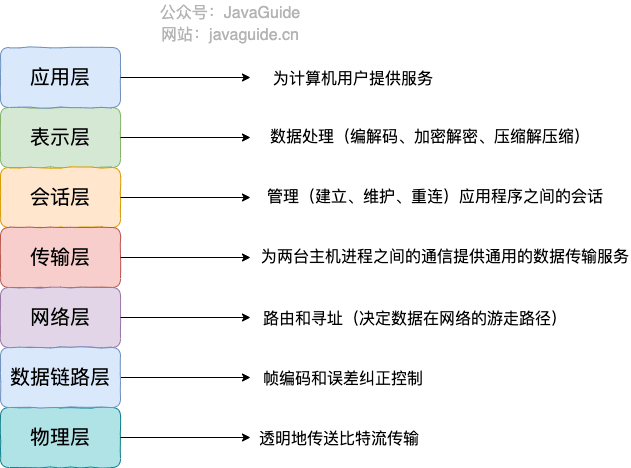
+
每一层都专注做一件事情,并且每一层都需要使用下一层提供的功能比如传输层需要使用网络层提供的路由和寻址功能,这样传输层才知道把数据传输到哪里去。
@@ -19,7 +35,7 @@ tag:
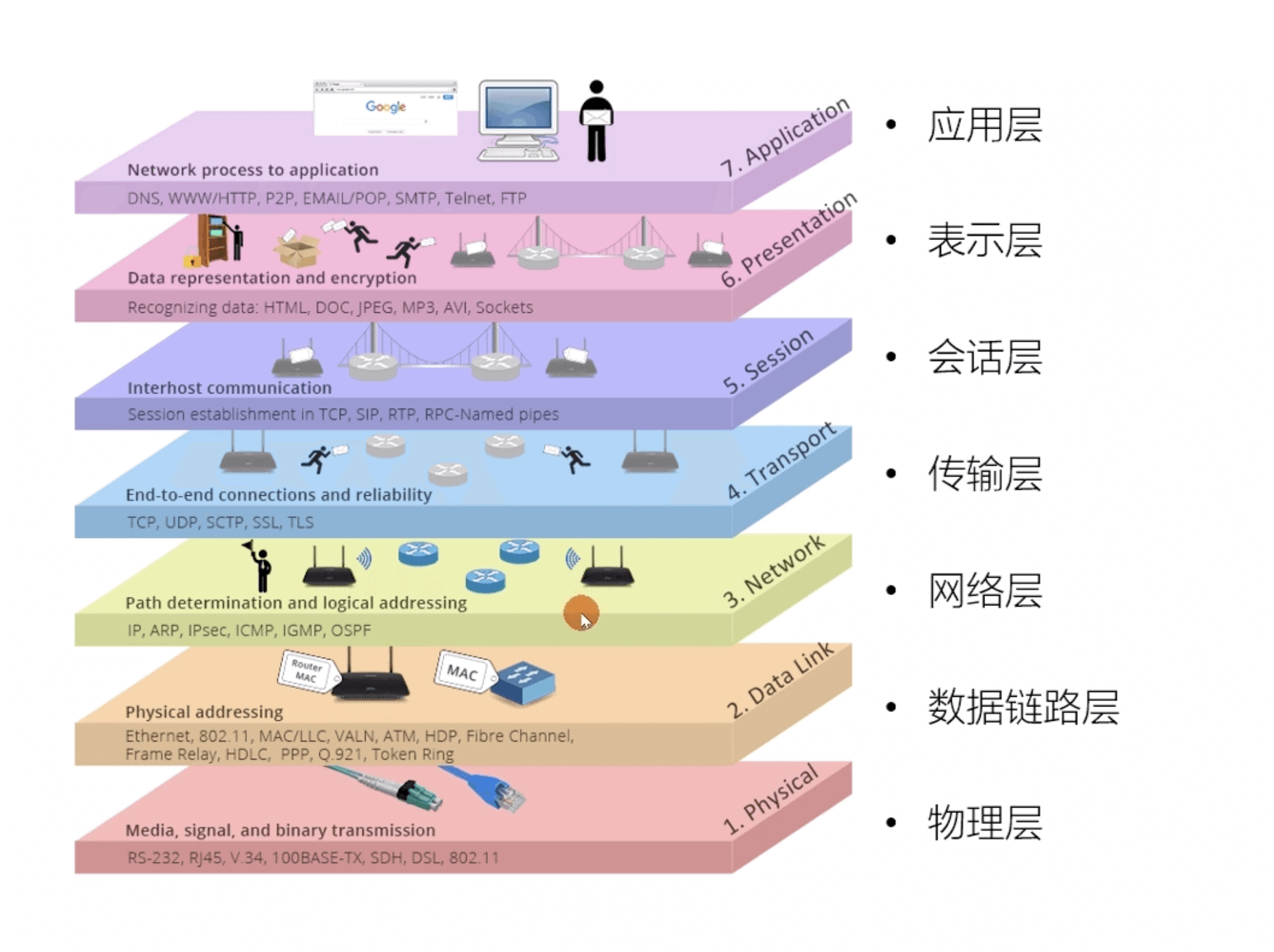
-**既然 OSI 七层模型这么厉害,为什么干不过 TCP/IP 四 层模型呢?**
+**既然 OSI 七层模型这么厉害,为什么干不过 TCP/IP 四层模型呢?**
的确,OSI 七层模型当时一直被一些大公司甚至一些国家政府支持。这样的背景下,为什么会失败呢?我觉得主要有下面几方面原因:
@@ -32,11 +48,11 @@ OSI 七层模型虽然失败了,但是却提供了很多不错的理论基础
最后再分享一个关于 OSI 七层模型非常不错的总结图片!
-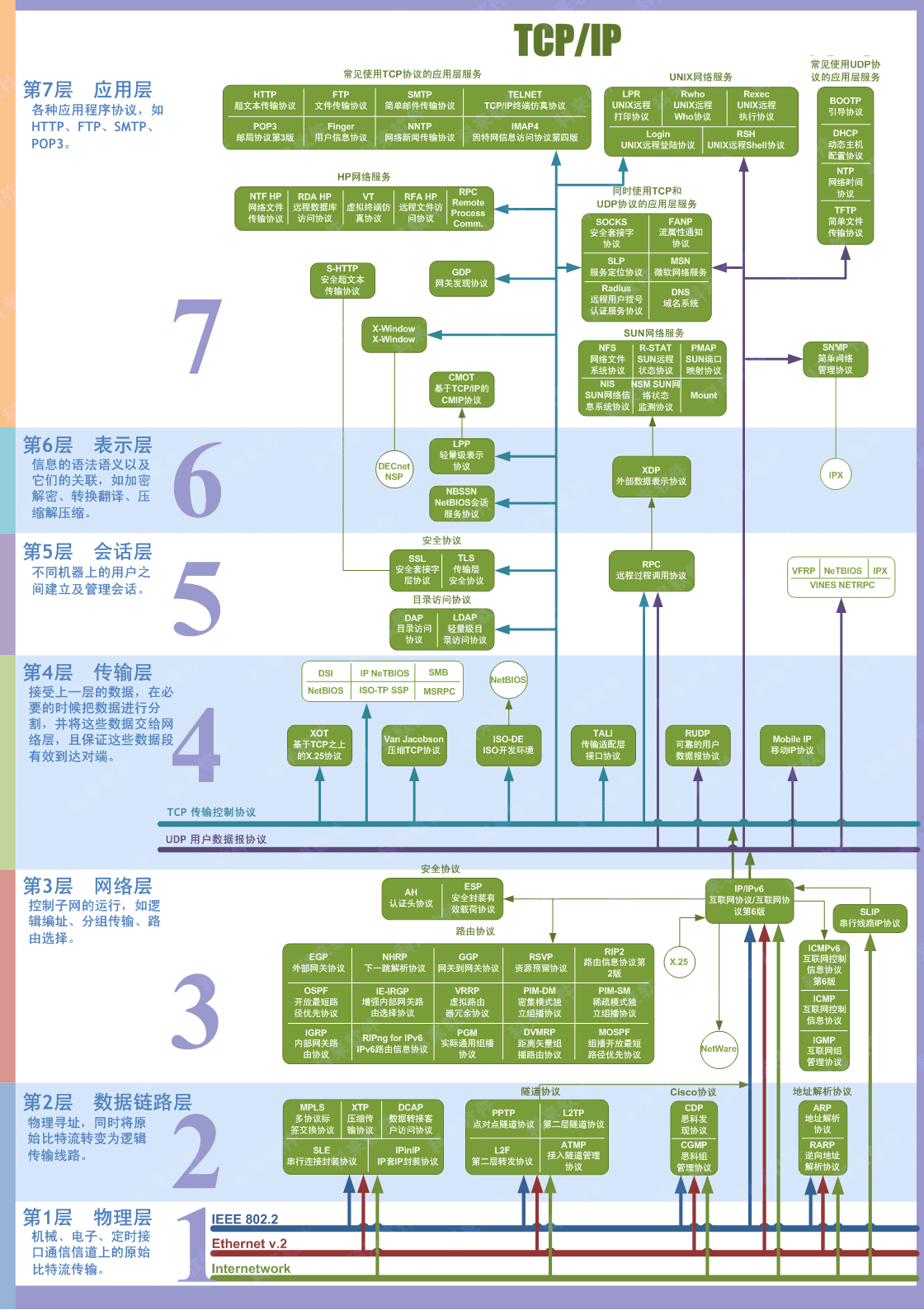
+
## TCP/IP 四层模型
-**TCP/IP 四层模型** 是目前被广泛采用的一种模型,我们可以将 TCP / IP 模型看作是 OSI 七层模型的精简版本,由以下 4 层组成:
+**TCP/IP 四层模型** 是目前被广泛采用的一种模型,我们可以将 TCP/IP 模型看作是 OSI 七层模型的精简版本,由以下 4 层组成:
1. 应用层
2. 传输层
@@ -45,13 +61,13 @@ OSI 七层模型虽然失败了,但是却提供了很多不错的理论基础
需要注意的是,我们并不能将 TCP/IP 四层模型 和 OSI 七层模型完全精确地匹配起来,不过可以简单将两者对应起来,如下图所示:
-
+
### 应用层(Application layer)
**应用层位于传输层之上,主要提供两个终端设备上的应用程序之间信息交换的服务,它定义了信息交换的格式,消息会交给下一层传输层来传输。** 我们把应用层交互的数据单元称为报文。
-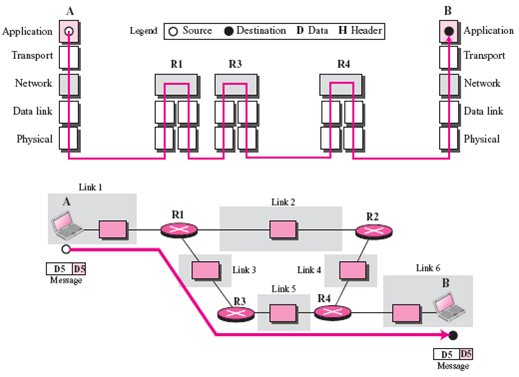
+
应用层协议定义了网络通信规则,对于不同的网络应用需要不同的应用层协议。在互联网中应用层协议很多,如支持 Web 应用的 HTTP 协议,支持电子邮件的 SMTP 协议等等。
@@ -62,11 +78,11 @@ OSI 七层模型虽然失败了,但是却提供了很多不错的理论基础
- **HTTP(Hypertext Transfer Protocol,超文本传输协议)**:基于 TCP 协议,是一种用于传输超文本和多媒体内容的协议,主要是为 Web 浏览器与 Web 服务器之间的通信而设计的。当我们使用浏览器浏览网页的时候,我们网页就是通过 HTTP 请求进行加载的。
- **SMTP(Simple Mail Transfer Protocol,简单邮件发送协议)**:基于 TCP 协议,是一种用于发送电子邮件的协议。注意 ⚠️:SMTP 协议只负责邮件的发送,而不是接收。要从邮件服务器接收邮件,需要使用 POP3 或 IMAP 协议。
- **POP3/IMAP(邮件接收协议)**:基于 TCP 协议,两者都是负责邮件接收的协议。IMAP 协议是比 POP3 更新的协议,它在功能和性能上都更加强大。IMAP 支持邮件搜索、标记、分类、归档等高级功能,而且可以在多个设备之间同步邮件状态。几乎所有现代电子邮件客户端和服务器都支持 IMAP。
-- **FTP(File Transfer Protocol,文件传输协议)** : 基于 TCP 协议,是一种用于在计算机之间传输文件的协议,可以屏蔽操作系统和文件存储方式。注意 ⚠️:FTP 是一种不安全的协议,因为它在传输过程中不会对数据进行加密。建议在传输敏感数据时使用更安全的协议,如 SFTP。
+- **FTP(File Transfer Protocol,文件传输协议)**:基于 TCP 协议,是一种用于在计算机之间传输文件的协议,可以屏蔽操作系统和文件存储方式。注意 ⚠️:FTP 是一种不安全的协议,因为它在传输过程中不会对数据进行加密。建议在传输敏感数据时使用更安全的协议,如 SFTP。
- **Telnet(远程登陆协议)**:基于 TCP 协议,用于通过一个终端登陆到其他服务器。Telnet 协议的最大缺点之一是所有数据(包括用户名和密码)均以明文形式发送,这有潜在的安全风险。这就是为什么如今很少使用 Telnet,而是使用一种称为 SSH 的非常安全的网络传输协议的主要原因。
- **SSH(Secure Shell Protocol,安全的网络传输协议)**:基于 TCP 协议,通过加密和认证机制实现安全的访问和文件传输等业务
- **RTP(Real-time Transport Protocol,实时传输协议)**:通常基于 UDP 协议,但也支持 TCP 协议。它提供了端到端的实时传输数据的功能,但不包含资源预留存、不保证实时传输质量,这些功能由 WebRTC 实现。
-- **DNS(Domain Name System,域名管理系统)**: 基于 UDP 协议,用于解决域名和 IP 地址的映射问题。
+- **DNS(Domain Name System,域名管理系统)**:通常基于 UDP 协议(端口 53),用于解决域名和 IP 地址的映射问题。当响应数据过大或进行区域传送时会改用 TCP。
关于这些协议的详细介绍请看 [应用层常见协议总结(应用层)](./application-layer-protocol.md) 这篇文章。
@@ -78,7 +94,7 @@ OSI 七层模型虽然失败了,但是却提供了很多不错的理论基础

-- **TCP(Transmission Control Protocol,传输控制协议 )**:提供 **面向连接** 的,**可靠** 的数据传输服务。
+- **TCP(Transmission Control Protocol,传输控制协议)**:提供 **面向连接** 的,**可靠** 的数据传输服务。
- **UDP(User Datagram Protocol,用户数据协议)**:提供 **无连接** 的,**尽最大努力** 的数据传输服务(不保证数据传输的可靠性),简单高效。
### 网络层(Network layer)
@@ -95,21 +111,21 @@ OSI 七层模型虽然失败了,但是却提供了很多不错的理论基础
**网络层常见协议**:
-
+
- **IP(Internet Protocol,网际协议)**:TCP/IP 协议中最重要的协议之一,主要作用是定义数据包的格式、对数据包进行路由和寻址,以便它们可以跨网络传播并到达正确的目的地。目前 IP 协议主要分为两种,一种是过去的 IPv4,另一种是较新的 IPv6,目前这两种协议都在使用,但后者已经被提议来取代前者。
- **ARP(Address Resolution Protocol,地址解析协议)**:ARP 协议解决的是网络层地址和链路层地址之间的转换问题。因为一个 IP 数据报在物理上传输的过程中,总是需要知道下一跳(物理上的下一个目的地)该去往何处,但 IP 地址属于逻辑地址,而 MAC 地址才是物理地址,ARP 协议解决了 IP 地址转 MAC 地址的一些问题。
- **ICMP(Internet Control Message Protocol,互联网控制报文协议)**:一种用于传输网络状态和错误消息的协议,常用于网络诊断和故障排除。例如,Ping 工具就使用了 ICMP 协议来测试网络连通性。
- **NAT(Network Address Translation,网络地址转换协议)**:NAT 协议的应用场景如同它的名称——网络地址转换,应用于内部网到外部网的地址转换过程中。具体地说,在一个小的子网(局域网,LAN)内,各主机使用的是同一个 LAN 下的 IP 地址,但在该 LAN 以外,在广域网(WAN)中,需要一个统一的 IP 地址来标识该 LAN 在整个 Internet 上的位置。
-- **OSPF(Open Shortest Path First,开放式最短路径优先)** ):一种内部网关协议(Interior Gateway Protocol,IGP),也是广泛使用的一种动态路由协议,基于链路状态算法,考虑了链路的带宽、延迟等因素来选择最佳路径。
-- **RIP(Routing Information Protocol,路由信息协议)**:一种内部网关协议(Interior Gateway Protocol,IGP),也是一种动态路由协议,基于距离向量算法,使用固定的跳数作为度量标准,选择跳数最少的路径作为最佳路径。
+- **OSPF(Open Shortest Path First,开放式最短路径优先)**:一种内部网关协议(Interior Gateway Protocol,IGP),也是广泛使用的一种动态路由协议,基于链路状态算法,考虑了链路的带宽、延迟等因素来选择最佳路径。
+- **RIP(Routing Information Protocol,路由信息协议)**:一种内部网关协议(Interior Gateway Protocol,IGP),也是一种动态路由协议,基于距离向量算法,使用固定的跳数作为度量标准,选择跳数最少的路径作为最佳路径。
- **BGP(Border Gateway Protocol,边界网关协议)**:一种用来在路由选择域之间交换网络层可达性信息(Network Layer Reachability Information,NLRI)的路由选择协议,具有高度的灵活性和可扩展性。
### 网络接口层(Network interface layer)
我们可以把网络接口层看作是数据链路层和物理层的合体。
-1. 数据链路层(data link layer)通常简称为链路层( 两台主机之间的数据传输,总是在一段一段的链路上传送的)。**数据链路层的作用是将网络层交下来的 IP 数据报组装成帧,在两个相邻节点间的链路上传送帧。每一帧包括数据和必要的控制信息(如同步信息,地址信息,差错控制等)。**
+1. 数据链路层(data link layer)通常简称为链路层(两台主机之间的数据传输,总是在一段一段的链路上传送的)。**数据链路层的作用是将网络层交下来的 IP 数据报组装成帧,在两个相邻节点间的链路上传送帧。每一帧包括数据和必要的控制信息(如同步信息,地址信息,差错控制等)。**
2. **物理层的作用是实现相邻计算机节点之间比特流的透明传送,尽可能屏蔽掉具体传输介质和物理设备的差异**
网络接口层重要功能和协议如下图所示:
@@ -122,7 +138,7 @@ OSI 七层模型虽然失败了,但是却提供了很多不错的理论基础

-**应用层协议** :
+**应用层协议**:
- HTTP(Hypertext Transfer Protocol,超文本传输协议)
- SMTP(Simple Mail Transfer Protocol,简单邮件发送协议)
@@ -134,7 +150,7 @@ OSI 七层模型虽然失败了,但是却提供了很多不错的理论基础
- DNS(Domain Name System,域名管理系统)
- ……
-**传输层协议** :
+**传输层协议**:
- TCP 协议
- 报文段结构
@@ -145,18 +161,18 @@ OSI 七层模型虽然失败了,但是却提供了很多不错的理论基础
- 报文段结构
- RDT(可靠数据传输协议)
-**网络层协议** :
+**网络层协议**:
- IP(Internet Protocol,网际协议)
- ARP(Address Resolution Protocol,地址解析协议)
- ICMP 协议(控制报文协议,用于发送控制消息)
- NAT(Network Address Translation,网络地址转换协议)
- OSPF(Open Shortest Path First,开放式最短路径优先)
-- RIP(Routing Information Protocol,路由信息协议)
+- RIP(Routing Information Protocol,路由信息协议)
- BGP(Border Gateway Protocol,边界网关协议)
- ……
-**网络接口层** :
+**网络接口层**:
- 差错检测技术
- 多路访问协议(信道复用技术)
diff --git a/docs/cs-basics/network/other-network-questions.md b/docs/cs-basics/network/other-network-questions.md
index 2f4da42d1a0..b83e95eb9eb 100644
--- a/docs/cs-basics/network/other-network-questions.md
+++ b/docs/cs-basics/network/other-network-questions.md
@@ -1,13 +1,20 @@
---
-title: 计算机网络常见面试题总结(上)
+title: 计算机网络常见面试题总结(上)
+description: 最新计算机网络高频面试题总结(上):TCP/IP四层模型、HTTP全版本对比、TCP三次握手、DNS解析、WebSocket/SSE实时推送等,附图解+⭐️重点标注,一文搞定应用层&传输层&网络层核心考点,快速备战后端面试!
category: 计算机基础
tag:
- 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: 计算机网络面试题,TCP/IP四层模型,HTTP面试,HTTPS vs HTTP,HTTP/1.1 vs HTTP/2,HTTP/3 QUIC,TCP三次握手,UDP区别,DNS解析,WebSocket vs SSE,GET vs POST,应用层协议,网络分层,队头阻塞,PING命令,ARP协议
---
-
+
-上篇主要是计算机网络基础和应用层相关的内容。
+计算机网络是后端面试和校招面试中绕不开的高频考点,尤其是 **TCP/IP 网络分层、HTTP、HTTPS、DNS、WebSocket、TCP 三次握手** 这些问题,几乎贯穿了“从输入 URL 到页面展示”“接口为什么变慢”“连接为什么失败”等真实开发场景。
+
+这篇《计算机网络常见面试题总结(上)》会先从网络分层模型讲起,再梳理应用层和 HTTP 相关的核心知识点,适合用来系统复习计算机网络基础,也适合作为 Java 后端、后端开发、计算机基础面试前的速查清单。
## 计算机网络基础
@@ -17,7 +24,7 @@ tag:
**OSI 七层模型** 是国际标准化组织提出的一个网络分层模型,其大体结构以及每一层提供的功能如下图所示:
-
+
每一层都专注做一件事情,并且每一层都需要使用下一层提供的功能比如传输层需要使用网络层提供的路由和寻址功能,这样传输层才知道把数据传输到哪里去。
@@ -27,9 +34,9 @@ tag:

-#### TCP/IP 四层模型是什么?每一层的作用是什么?
+#### ⭐️ TCP/IP 四层模型是什么?每一层的作用是什么?
-**TCP/IP 四层模型** 是目前被广泛采用的一种模型,我们可以将 TCP / IP 模型看作是 OSI 七层模型的精简版本,由以下 4 层组成:
+**TCP/IP 四层模型** 是目前被广泛采用的一种模型,我们可以将 TCP/IP 模型看作是 OSI 七层模型的精简版本,由以下 4 层组成:
1. 应用层
2. 传输层
@@ -38,9 +45,9 @@ tag:
需要注意的是,我们并不能将 TCP/IP 四层模型 和 OSI 七层模型完全精确地匹配起来,不过可以简单将两者对应起来,如下图所示:
-
+
-关于每一层作用的详细介绍,请看 [OSI 和 TCP/IP 网络分层模型详解(基础)](./osi-and-tcp-ip-model.md) 这篇文章。
+关于每一层作用的详细介绍,请看 [OSI 和 TCP/IP 网络分层模型详解(基础)](https://javaguide.cn/cs-basics/network/osi-and-tcp-ip-model.html) 这篇文章。
#### 为什么网络要分层?
@@ -64,18 +71,18 @@ tag:
### 常见网络协议
-#### 应用层有哪些常见的协议?
+#### ⭐️ 应用层有哪些常见的协议?
- **HTTP(Hypertext Transfer Protocol,超文本传输协议)**:基于 TCP 协议,是一种用于传输超文本和多媒体内容的协议,主要是为 Web 浏览器与 Web 服务器之间的通信而设计的。当我们使用浏览器浏览网页的时候,我们网页就是通过 HTTP 请求进行加载的。
- **SMTP(Simple Mail Transfer Protocol,简单邮件发送协议)**:基于 TCP 协议,是一种用于发送电子邮件的协议。注意 ⚠️:SMTP 协议只负责邮件的发送,而不是接收。要从邮件服务器接收邮件,需要使用 POP3 或 IMAP 协议。
- **POP3/IMAP(邮件接收协议)**:基于 TCP 协议,两者都是负责邮件接收的协议。IMAP 协议是比 POP3 更新的协议,它在功能和性能上都更加强大。IMAP 支持邮件搜索、标记、分类、归档等高级功能,而且可以在多个设备之间同步邮件状态。几乎所有现代电子邮件客户端和服务器都支持 IMAP。
-- **FTP(File Transfer Protocol,文件传输协议)** : 基于 TCP 协议,是一种用于在计算机之间传输文件的协议,可以屏蔽操作系统和文件存储方式。注意 ⚠️:FTP 是一种不安全的协议,因为它在传输过程中不会对数据进行加密。建议在传输敏感数据时使用更安全的协议,如 SFTP。
+- **FTP(File Transfer Protocol,文件传输协议)**:基于 TCP 协议,是一种用于在计算机之间传输文件的协议,可以屏蔽操作系统和文件存储方式。注意 ⚠️:FTP 是一种不安全的协议,因为它在传输过程中不会对数据进行加密。建议在传输敏感数据时使用更安全的协议,如 SFTP。
- **Telnet(远程登陆协议)**:基于 TCP 协议,用于通过一个终端登陆到其他服务器。Telnet 协议的最大缺点之一是所有数据(包括用户名和密码)均以明文形式发送,这有潜在的安全风险。这就是为什么如今很少使用 Telnet,而是使用一种称为 SSH 的非常安全的网络传输协议的主要原因。
- **SSH(Secure Shell Protocol,安全的网络传输协议)**:基于 TCP 协议,通过加密和认证机制实现安全的访问和文件传输等业务
- **RTP(Real-time Transport Protocol,实时传输协议)**:通常基于 UDP 协议,但也支持 TCP 协议。它提供了端到端的实时传输数据的功能,但不包含资源预留存、不保证实时传输质量,这些功能由 WebRTC 实现。
-- **DNS(Domain Name System,域名管理系统)**: 基于 UDP 协议,用于解决域名和 IP 地址的映射问题。
+- **DNS(Domain Name System,域名管理系统)**:通常基于 UDP 协议(端口 53),用于解决域名和 IP 地址的映射问题。当响应数据过大或进行区域传送时会改用 TCP。
关于这些协议的详细介绍请看 [应用层常见协议总结(应用层)](./application-layer-protocol.md) 这篇文章。
@@ -83,32 +90,32 @@ tag:

-- **TCP(Transmission Control Protocol,传输控制协议 )**:提供 **面向连接** 的,**可靠** 的数据传输服务。
+- **TCP(Transmission Control Protocol,传输控制协议)**:提供 **面向连接** 的,**可靠** 的数据传输服务。
- **UDP(User Datagram Protocol,用户数据协议)**:提供 **无连接** 的,**尽最大努力** 的数据传输服务(不保证数据传输的可靠性),简单高效。
#### 网络层有哪些常见的协议?
-
+
- **IP(Internet Protocol,网际协议)**:TCP/IP 协议中最重要的协议之一,属于网络层的协议,主要作用是定义数据包的格式、对数据包进行路由和寻址,以便它们可以跨网络传播并到达正确的目的地。目前 IP 协议主要分为两种,一种是过去的 IPv4,另一种是较新的 IPv6,目前这两种协议都在使用,但后者已经被提议来取代前者。
- **ARP(Address Resolution Protocol,地址解析协议)**:ARP 协议解决的是网络层地址和链路层地址之间的转换问题。因为一个 IP 数据报在物理上传输的过程中,总是需要知道下一跳(物理上的下一个目的地)该去往何处,但 IP 地址属于逻辑地址,而 MAC 地址才是物理地址,ARP 协议解决了 IP 地址转 MAC 地址的一些问题。
- **ICMP(Internet Control Message Protocol,互联网控制报文协议)**:一种用于传输网络状态和错误消息的协议,常用于网络诊断和故障排除。例如,Ping 工具就使用了 ICMP 协议来测试网络连通性。
- **NAT(Network Address Translation,网络地址转换协议)**:NAT 协议的应用场景如同它的名称——网络地址转换,应用于内部网到外部网的地址转换过程中。具体地说,在一个小的子网(局域网,LAN)内,各主机使用的是同一个 LAN 下的 IP 地址,但在该 LAN 以外,在广域网(WAN)中,需要一个统一的 IP 地址来标识该 LAN 在整个 Internet 上的位置。
- **OSPF(Open Shortest Path First,开放式最短路径优先)**:一种内部网关协议(Interior Gateway Protocol,IGP),也是广泛使用的一种动态路由协议,基于链路状态算法,考虑了链路的带宽、延迟等因素来选择最佳路径。
-- **RIP(Routing Information Protocol,路由信息协议)**:一种内部网关协议(Interior Gateway Protocol,IGP),也是一种动态路由协议,基于距离向量算法,使用固定的跳数作为度量标准,选择跳数最少的路径作为最佳路径。
+- **RIP(Routing Information Protocol,路由信息协议)**:一种内部网关协议(Interior Gateway Protocol,IGP),也是一种动态路由协议,基于距离向量算法,使用固定的跳数作为度量标准,选择跳数最少的路径作为最佳路径。
- **BGP(Border Gateway Protocol,边界网关协议)**:一种用来在路由选择域之间交换网络层可达性信息(Network Layer Reachability Information,NLRI)的路由选择协议,具有高度的灵活性和可扩展性。
## HTTP
-### 从输入 URL 到页面展示到底发生了什么?(非常重要)
+### ⭐️ 从输入 URL 到页面展示到底发生了什么?(非常重要)
> 类似的问题:打开一个网页,整个过程会使用哪些协议?
先来看一张图(来源于《图解 HTTP》):
-。服务器端会解析 URL 中的 `sessionid` 参数来获取 `SessionID`,进而找到对应的 Session 数据。
@@ -294,20 +334,20 @@ Session 数据本身存储在服务器端。常见的存储方式有:
- URL 会变长且不美观;
- `SessionID` 暴露在 URL 中,安全性较低(容易被复制、分享或记录在日志中);
-- 对搜索引擎优化 (SEO) 可能不友好。
+- 对搜索引擎优化(SEO)可能不友好。
-**方案三:Token-based 认证 (如 JWT - JSON Web Tokens)**
+**方案三:Token-based 认证(如 JWT - JSON Web Tokens)**
这是一种越来越流行的无状态认证方式,尤其适用于前后端分离的架构和微服务。
-
+
-以 JWT 为例(普通 Token 方案也可以),简化后的步骤如下
+以 JWT 为例(普通 Token 方案也可以),简化后的步骤如下:
-1. 用户向服务器发送用户名、密码以及验证码用于登陆系统;
-2. 如果用户用户名、密码以及验证码校验正确的话,服务端会返回已经签名的 Token,也就是 JWT;
-3. 客户端收到 Token 后自己保存起来(比如浏览器的 `localStorage` );
-4. 用户以后每次向后端发请求都在 Header 中带上这个 JWT ;
+1. 用户向服务器发送用户名、密码以及验证码用于登陆系统。
+2. 如果用户名、密码以及验证码校验正确的话,服务端会返回已经签名的 Token,也就是 JWT。
+3. 客户端收到 Token 后自己保存起来(比如浏览器的 `localStorage`)。
+4. 用户以后每次向后端发请求都在 Header 中带上这个 JWT。
5. 服务端检查 JWT 并从中获取用户相关信息。
JWT 详细介绍可以查看这两篇文章:
@@ -317,22 +357,20 @@ JWT 详细介绍可以查看这两篇文章:
总结来说,虽然 HTTP 本身是无状态的,但通过 Cookie + Session、URL 重写或 Token 等机制,我们能够有效地在 Web 应用中跟踪和管理用户状态。其中,**Cookie + Session 是最传统也最广泛使用的方式,而 Token-based 认证则在现代 Web 应用中越来越受欢迎。**
-### URI 和 URL 的区别是什么?
+### URI 和 URL 的区别是什么?
-- URI(Uniform Resource Identifier) 是统一资源标志符,可以唯一标识一个资源。
-- URL(Uniform Resource Locator) 是统一资源定位符,可以提供该资源的路径。它是一种具体的 URI,即 URL 可以用来标识一个资源,而且还指明了如何 locate 这个资源。
+- URI(Uniform Resource Identifier)是统一资源标志符,可以唯一标识一个资源。
+- URL(Uniform Resource Locator)是统一资源定位符,可以提供该资源的路径。它是一种具体的 URI,即 URL 可以用来标识一个资源,而且还指明了如何 locate 这个资源。
URI 的作用像身份证号一样,URL 的作用更像家庭住址一样。URL 是一种具体的 URI,它不仅唯一标识资源,而且还提供了定位该资源的信息。
### Cookie 和 Session 有什么区别?
-准确点来说,这个问题属于认证授权的范畴,你可以在 [认证授权基础概念详解](../../system-design/security/basis-of-authority-certification.md) 这篇文章中找到详细的答案。
-
-### GET 和 POST 的区别
+准确点来说,这个问题属于认证授权的范畴,你可以在 [认证授权基础概念详解](https://javaguide.cn/system-design/security/basis-of-authority-certification.html) 这篇文章中找到详细的答案。
-这个问题在知乎上被讨论的挺火热的,地址: 。
+### ⭐️ GET 和 POST 的区别
-
+这个问题在知乎上被讨论的挺火热的,地址:。
GET 和 POST 是 HTTP 协议中两种常用的请求方法,它们在不同的场景和目的下有不同的特点和用法。一般来说,可以从以下几个方面来区分二者(重点搞清两者在语义上的区别即可):
@@ -354,7 +392,7 @@ WebSocket 协议在 2008 年诞生,2011 年成为国际标准,几乎所有
WebSocket 协议本质上是应用层的协议,用于弥补 HTTP 协议在持久通信能力上的不足。客户端和服务器仅需一次握手,两者之间就直接可以创建持久性的连接,并进行双向数据传输。
-
+
下面是 WebSocket 的常见应用场景:
@@ -365,14 +403,14 @@ WebSocket 协议本质上是应用层的协议,用于弥补 HTTP 协议在持
- 社交聊天
- ……
-### WebSocket 和 HTTP 有什么区别?
+### ⭐️ WebSocket 和 HTTP 有什么区别?
WebSocket 和 HTTP 两者都是基于 TCP 的应用层协议,都可以在网络中传输数据。
下面是二者的主要区别:
- WebSocket 是一种双向实时通信协议,而 HTTP 是一种单向通信协议。并且,HTTP 协议下的通信只能由客户端发起,服务器无法主动通知客户端。
-- WebSocket 使用 ws:// 或 wss://(使用 SSL/TLS 加密后的协议,类似于 HTTP 和 HTTPS 的关系) 作为协议前缀,HTTP 使用 http:// 或 https:// 作为协议前缀。
+- WebSocket 使用 ws:// 或 wss://(使用 SSL/TLS 加密后的协议,类似于 HTTP 和 HTTPS 的关系)作为协议前缀,HTTP 使用 http:// 或 https:// 作为协议前缀。
- WebSocket 可以支持扩展,用户可以扩展协议,实现部分自定义的子协议,如支持压缩、加密等。
- WebSocket 通信数据格式比较轻量,用于协议控制的数据包头部相对较小,网络开销小,而 HTTP 通信每次都要携带完整的头部,网络开销较大(HTTP/2.0 使用二进制帧进行数据传输,还支持头部压缩,减少了网络开销)。
@@ -381,13 +419,13 @@ WebSocket 和 HTTP 两者都是基于 TCP 的应用层协议,都可以在网
WebSocket 的工作过程可以分为以下几个步骤:
1. 客户端向服务器发送一个 HTTP 请求,请求头中包含 `Upgrade: websocket` 和 `Sec-WebSocket-Key` 等字段,表示要求升级协议为 WebSocket;
-2. 服务器收到这个请求后,会进行升级协议的操作,如果支持 WebSocket,它将回复一个 HTTP 101 状态码,响应头中包含 ,`Connection: Upgrade`和 `Sec-WebSocket-Accept: xxx` 等字段、表示成功升级到 WebSocket 协议。
+2. 服务器收到这个请求后,会进行升级协议的操作,如果支持 WebSocket,它将回复一个 HTTP 101 状态码,响应头中包含 `Connection: Upgrade` 和 `Sec-WebSocket-Accept: xxx` 等字段,表示成功升级到 WebSocket 协议。
3. 客户端和服务器之间建立了一个 WebSocket 连接,可以进行双向的数据传输。数据以帧(frames)的形式进行传送,WebSocket 的每条消息可能会被切分成多个数据帧(最小单位)。发送端会将消息切割成多个帧发送给接收端,接收端接收消息帧,并将关联的帧重新组装成完整的消息。
4. 客户端或服务器可以主动发送一个关闭帧,表示要断开连接。另一方收到后,也会回复一个关闭帧,然后双方关闭 TCP 连接。
另外,建立 WebSocket 连接之后,通过心跳机制来保持 WebSocket 连接的稳定性和活跃性。
-### WebSocket 与短轮询、长轮询的区别
+### ⭐️ WebSocket 与短轮询、长轮询的区别
这三种方式,都是为了解决“**客户端如何及时获取服务器最新数据,实现实时更新**”的问题。它们的实现方式和效率、实时性差异较大。
@@ -420,15 +458,15 @@ WebSocket 的工作过程可以分为以下几个步骤:
- **使用限制**:需要服务器和客户端都支持 WebSocket 协议。对连接管理有一定要求(如心跳保活、断线重连等)。
- **实现麻烦**:实现起来比短轮询和长轮询要更麻烦一些。
-
+
-### SSE 与 WebSocket 有什么区别?
+### ⭐️ SSE 与 WebSocket 有什么区别?
-SSE (Server-Sent Events) 和 WebSocket 都是用来实现服务器向浏览器实时推送消息的技术,让网页内容能自动更新,而不需要用户手动刷新。虽然目标相似,但它们在工作方式和适用场景上有几个关键区别:
+SSE(Server-Sent Events)和 WebSocket 都是用来实现服务器向浏览器实时推送消息的技术,让网页内容能自动更新,而不需要用户手动刷新。虽然目标相似,但它们在工作方式和适用场景上有几个关键区别:
1. **通信方式:**
- **SSE:** **单向通信**。只有服务器能向客户端(浏览器)发送数据。客户端不能通过同一个连接向服务器发送数据(需要发起新的 HTTP 请求)。
- - **WebSocket:** **双向通信 (全双工)**。客户端和服务器可以随时互相发送消息,实现真正的实时交互。
+ - **WebSocket:** **双向通信(全双工)**。客户端和服务器可以随时互相发送消息,实现真正的实时交互。
2. **底层协议:**
- **SSE:** 基于**标准的 HTTP/HTTPS 协议**。它本质上是一个“长连接”的 HTTP 请求,服务器保持连接打开并持续发送事件流。不需要特殊的服务器或协议支持,现有的 HTTP 基础设施就能用。
- **WebSocket:** 使用**独立的 ws:// 或 wss:// 协议**。它需要通过一个特定的 HTTP "Upgrade" 请求来建立连接,并且服务器需要明确支持 WebSocket 协议来处理连接和消息帧。
@@ -439,18 +477,18 @@ SSE (Server-Sent Events) 和 WebSocket 都是用来实现服务器向浏览器
- **SSE:** **浏览器原生支持**。EventSource API 提供了自动断线重连的机制。
- **WebSocket:** **需要手动实现**。开发者需要自己编写逻辑来检测断线并进行重连尝试。
5. **数据类型:**
- - **SSE:** **主要设计用来传输文本** (UTF-8 编码)。如果需要传输二进制数据,需要先进行 Base64 等编码转换成文本。
+ - **SSE:** **主要设计用来传输文本**(UTF-8 编码)。如果需要传输二进制数据,需要先进行 Base64 等编码转换成文本。
- **WebSocket:** **原生支持传输文本和二进制数据**,无需额外编码。
-为了提供更好的用户体验和利用其简单、高效、基于标准 HTTP 的特性,**Server-Sent Events (SSE) 是目前大型语言模型 API(如 OpenAI、DeepSeek 等)实现流式响应的常用甚至可以说是标准的技木选择**。
+为了提供更好的用户体验和利用其简单、高效、基于标准 HTTP 的特性,**Server-Sent Events(SSE)是目前大型语言模型 API(如 OpenAI、DeepSeek 等)实现流式响应的常用甚至可以说是标准的技术选择**。
这里以 DeepSeek 为例,我们发送一个请求并打开浏览器控制台验证一下:
-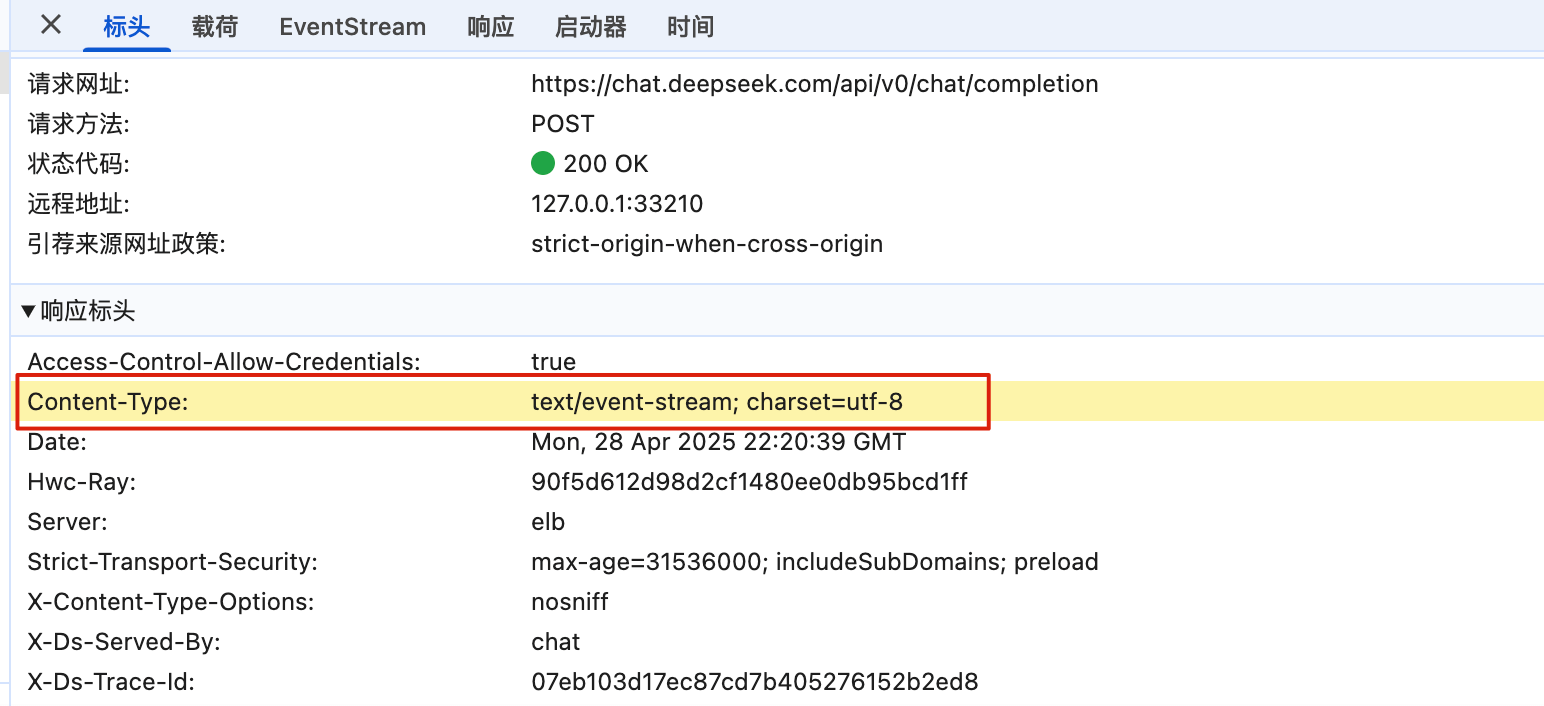
+
-
+
-可以看到,响应头应里包含了 `text/event-stream`,说明使用的确实是SSE。并且,响应数据也确实是持续分块传输。
+可以看到,响应头里包含了 `text/event-stream`,说明使用的确实是 SSE。并且,响应数据也确实是持续分块传输。
## PING
@@ -493,37 +531,60 @@ ICMP 报文中包含了类型字段,用于标识 ICMP 报文类型。ICMP 报
- **查询报文类型**:向目标主机发送请求并期望得到响应。
- **差错报文类型**:向源主机发送错误信息,用于报告网络中的错误情况。
-PING 用到的 ICMP Echo Request(类型为 8 ) 和 ICMP Echo Reply(类型为 0) 属于查询报文类型 。
+PING 用到的 ICMP Echo Request(类型为 8)和 ICMP Echo Reply(类型为 0)属于查询报文类型。
- PING 命令会向目标主机发送 ICMP Echo Request。
- 如果两个主机的连通性正常,目标主机会返回一个对应的 ICMP Echo Reply。
+### ⭐️ 能 Ping 通,TCP 就一定能连通吗?
+
+先说结论:**不是**。
+
+Ping 使用 ICMP(网络层),TCP 连接使用 TCP(传输层),两者可能经过同一条网络路径,但中间设备会按协议类型、端口、连接状态和安全策略分别处理。你能 Ping 通,只能说明 ICMP Echo 这条路径能往返,不等于目标 TCP 端口一定可达。
+
+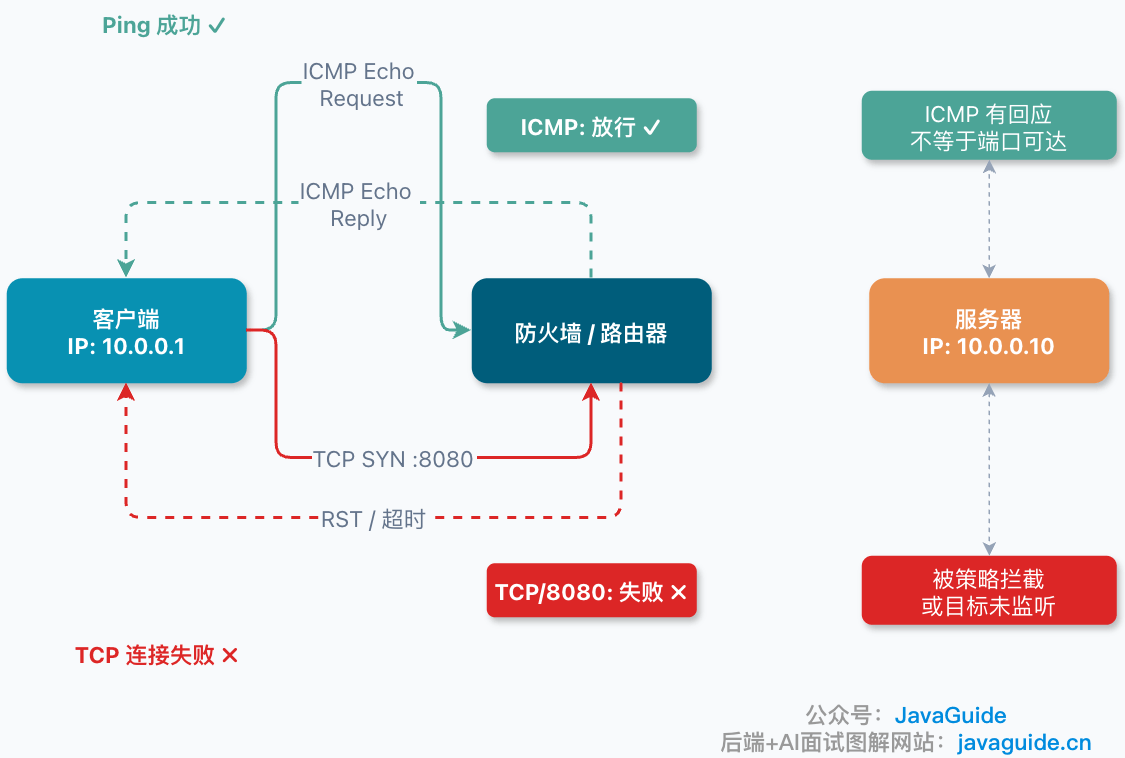
+
+常见原因有这几种:
+
+- **防火墙策略不同**:很多网络设备允许 ICMP(方便运维探测),但 TCP 端口规则收得更紧,可能只开放了 `22`、`80`、`443`,其他端口一律不放。
+- **服务没启动或端口没监听**:主机能回 ICMP,但 Nginx 没启动、MySQL 没监听,Ping 通但 TCP 连不上。
+- **中间有 NAT / 负载均衡 / 安全设备**:公网 IP 后面可能不是一台真实服务器,ICMP 响应可能来自中间设备,不能直接等同于后端服务可用。
+- **HTTPS 还可能卡在 TLS 握手的 SNI**:TCP 三次握手可能成功了,但 `ClientHello` 里的 SNI 被中间设备识别并拦截,导致连接重置或卡住。
+
+反过来也成立:**Ping 不通,不代表 TCP 一定不通**。有些服务器或云安全组直接禁 ICMP,但业务端口正常工作。
+
+排查建议:先看 DNS(域名场景),再用 `ping` 看 ICMP,然后用 `nc` 测端口,最后用 `curl` 或 `openssl s_client` 看 HTTPS / TLS。别用一个命令过早下结论。
+
+
+
+详细介绍:[能 Ping 通,TCP 就一定能连通吗?](./can-ping-but-tcp-may-not-connect.md)
+
## DNS
### DNS 的作用是什么?
DNS(Domain Name System)域名管理系统,是当用户使用浏览器访问网址之后,使用的第一个重要协议。DNS 要解决的是**域名和 IP 地址的映射问题**。
-
+
在一台电脑上,可能存在浏览器 DNS 缓存,操作系统 DNS 缓存,路由器 DNS 缓存。如果以上缓存都查询不到,那么 DNS 就闪亮登场了。
-目前 DNS 的设计采用的是分布式、层次数据库结构,**DNS 是应用层协议,它可以在 UDP 或 TCP 协议之上运行,端口为 53** 。
+目前 DNS 的设计采用的是分布式、层次数据库结构,**DNS 是应用层协议,它可以在 UDP 或 TCP 协议之上运行,端口为 53**。
### DNS 服务器有哪些?根服务器有多少个?
-DNS 服务器自底向上可以依次分为以下几个层级(所有 DNS 服务器都属于以下四个类别之一):
+DNS 服务器自底向上可以依次分为以下几个层级(所有 DNS 服务器都属于以下四个类别之一):
- 根 DNS 服务器。根 DNS 服务器提供 TLD 服务器的 IP 地址。目前世界上只有 13 组根服务器,我国境内目前仍没有根服务器。
-- 顶级域 DNS 服务器(TLD 服务器)。顶级域是指域名的后缀,如`com`、`org`、`net`和`edu`等。国家也有自己的顶级域,如`uk`、`fr`和`ca`。TLD 服务器提供了权威 DNS 服务器的 IP 地址。
+- 顶级域 DNS 服务器(TLD 服务器)。顶级域是指域名的后缀,如 `com`、`org`、`net` 和 `edu` 等。国家也有自己的顶级域,如 `uk`、`fr` 和 `ca`。TLD 服务器提供了权威 DNS 服务器的 IP 地址。
- 权威 DNS 服务器。在因特网上具有公共可访问主机的每个组织机构必须提供公共可访问的 DNS 记录,这些记录将这些主机的名字映射为 IP 地址。
- 本地 DNS 服务器。每个 ISP(互联网服务提供商)都有一个自己的本地 DNS 服务器。当主机发出 DNS 请求时,该请求被发往本地 DNS 服务器,它起着代理的作用,并将该请求转发到 DNS 层次结构中。严格说来,不属于 DNS 层级结构
世界上并不是只有 13 台根服务器,这是很多人普遍的误解,网上很多文章也是这么写的。实际上,现在根服务器数量远远超过这个数量。最初确实是为 DNS 根服务器分配了 13 个 IP 地址,每个 IP 地址对应一个不同的根 DNS 服务器。然而,由于互联网的快速发展和增长,这个原始的架构变得不太适应当前的需求。为了提高 DNS 的可靠性、安全性和性能,目前这 13 个 IP 地址中的每一个都有多个服务器,截止到 2023 年底,所有根服务器之和达到了 1700 多台,未来还会继续增加。
-### DNS 解析的过程是什么样的?
+### ⭐️ DNS 解析的过程是什么样的?
-整个过程的步骤比较多,我单独写了一篇文章详细介绍:[DNS 域名系统详解(应用层)](./dns.md) 。
+整个过程的步骤比较多,我单独写了一篇文章详细介绍:[DNS 域名系统详解(应用层)](https://javaguide.cn/cs-basics/network/dns.html)。
### DNS 劫持了解吗?如何应对?
@@ -536,6 +597,6 @@ DNS 劫持是一种网络攻击,它通过修改 DNS 服务器的解析结果
- 详解 HTTP/2.0 及 HTTPS 协议:
- HTTP 请求头字段大全| HTTP Request Headers:
-- 如何看待 HTTP/3 ? - 车小胖的回答 - 知乎:
+- 如何看待 HTTP/3? - 车小胖的回答 - 知乎:
diff --git a/docs/cs-basics/network/other-network-questions2.md b/docs/cs-basics/network/other-network-questions2.md
index 67c731f44c0..5408f860509 100644
--- a/docs/cs-basics/network/other-network-questions2.md
+++ b/docs/cs-basics/network/other-network-questions2.md
@@ -1,22 +1,29 @@
---
-title: 计算机网络常见面试题总结(下)
+title: 计算机网络常见面试题总结(下)
+description: 最新计算机网络高频面试题总结(下):TCP/UDP深度对比、三次握手四次挥手、HTTP/3 QUIC优化、IPv6优势、NAT/ARP详解,附表格+⭐️重点标注,一文掌握传输层&网络层核心考点,快速通关后端技术面试!
category: 计算机基础
tag:
- 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: 计算机网络面试题,TCP vs UDP,TCP三次握手,HTTP/3 QUIC,IPv4 vs IPv6,TCP可靠性,IP地址,NAT协议,ARP协议,传输层面试,网络层高频题,基于TCP协议,基于UDP协议,队头阻塞,四次挥手
---
-下篇主要是传输层和网络层相关的内容。
+计算机网络面试题里,真正容易被追问到细节的部分,往往集中在 **TCP、UDP、IP、ARP、NAT、IPv4/IPv6** 这些传输层和网络层知识点上。比如:为什么 TCP 可靠?为什么要三次握手和四次挥手?HTTP/3 为什么改用基于 UDP 的 QUIC?这些问题不仅考概念,也考你对网络通信过程的理解。
+
+这篇《计算机网络常见面试题总结(下)》会重点梳理 TCP 与 UDP、TCP 连接管理、可靠传输、IP 地址、ARP、NAT 等后端面试高频内容,帮助你把传输层和网络层的核心考点串起来。
## TCP 与 UDP
-### TCP 与 UDP 的区别(重要)
+### ⭐️ TCP 与 UDP 的区别(重要)
1. **是否面向连接**:
- TCP 是面向连接的。在传输数据之前,必须先通过“三次握手”建立连接;数据传输完成后,还需要通过“四次挥手”来释放连接。这保证了双方都准备好通信。
- UDP 是无连接的。发送数据前不需要建立任何连接,直接把数据包(数据报)扔出去。
2. **是否是可靠传输**:
- - TCP 提供可靠的数据传输服务。它通过序列号、确认应答 (ACK)、超时重传、流量控制、拥塞控制等一系列机制,来确保数据能够无差错、不丢失、不重复且按顺序地到达目的地。
- - UDP 提供不可靠的传输。它尽最大努力交付 (best-effort delivery),但不保证数据一定能到达,也不保证到达的顺序,更不会自动重传。收到报文后,接收方也不会主动发确认。
+ - TCP 提供可靠的数据传输服务。它通过序列号、确认应答(ACK)、超时重传、流量控制、拥塞控制等一系列机制,来确保数据能够无差错、不丢失、不重复且按顺序地到达目的地。
+ - UDP 提供不可靠的传输。它尽最大努力交付(best-effort delivery),但不保证数据一定能到达,也不保证到达的顺序,更不会自动重传。收到报文后,接收方也不会主动发确认。
3. **是否有状态**:
- TCP 是有状态的。因为要保证可靠性,TCP 需要在连接的两端维护连接状态信息,比如序列号、窗口大小、哪些数据发出去了、哪些收到了确认等。
- UDP 是无状态的。它不维护连接状态,发送方发出数据后就不再关心它是否到达以及如何到达,因此开销更小(**这很“渣男”!**)。
@@ -24,14 +31,14 @@ tag:
- TCP 因为需要建立连接、发送确认、处理重传等,其开销较大,传输效率相对较低。
- UDP 结构简单,没有复杂的控制机制,开销小,传输效率更高,速度更快。
5. **传输形式**:
- - TCP 是面向字节流 (Byte Stream) 的。它将应用程序交付的数据视为一连串无结构的字节流,可能会对数据进行拆分或合并。
- - UDP 是面向报文 (Message Oriented) 的。应用程序交给 UDP 多大的数据块,UDP 就照样发送,既不拆分也不合并,保留了应用程序消息的边界。
+ - TCP 是面向字节流(Byte Stream)的。它将应用程序交付的数据视为一连串无结构的字节流,可能会对数据进行拆分或合并。
+ - UDP 是面向报文(Message Oriented)的。应用程序交给 UDP 多大的数据块,UDP 就照样发送,既不拆分也不合并,保留了应用程序消息的边界。
6. **首部开销**:
- TCP 的头部至少需要 20 字节,如果包含选项字段,最多可达 60 字节。
- UDP 的头部非常简单,固定只有 8 字节。
7. **是否提供广播或多播服务**:
- - TCP 只支持点对点 (Point-to-Point) 的单播通信。
- - UDP 支持一对一 (单播)、一对多 (多播/Multicast) 和一对所有 (广播/Broadcast) 的通信方式。
+ - TCP 只支持点对点(Point-to-Point)的单播通信。
+ - UDP 支持一对一(单播)、一对多(多播/Multicast)和一对所有(广播/Broadcast)的通信方式。
8. ……
为了更直观地对比,可以看下面这个表格:
@@ -39,33 +46,33 @@ tag:
| 特性 | TCP | UDP |
| ------------ | -------------------------- | ----------------------------------- |
| **连接性** | 面向连接 | 无连接 |
-| **可靠性** | 可靠 | 不可靠 (尽力而为) |
+| **可靠性** | 可靠 | 不可靠(尽力而为) |
| **状态维护** | 有状态 | 无状态 |
| **传输效率** | 较低 | 较高 |
-| **传输形式** | 面向字节流 | 面向数据报 (报文) |
+| **传输形式** | 面向字节流 | 面向数据报(报文) |
| **头部开销** | 20 - 60 字节 | 8 字节 |
-| **通信模式** | 点对点 (单播) | 单播、多播、广播 |
+| **通信模式** | 点对点(单播) | 单播、多播、广播 |
| **常见应用** | HTTP/HTTPS, FTP, SMTP, SSH | DNS, DHCP, SNMP, TFTP, VoIP, 视频流 |
-### 什么时候选择 TCP,什么时候选 UDP?
+### ⭐️ 什么时候选择 TCP,什么时候选 UDP?
选择 TCP 还是 UDP,主要取决于你的应用**对数据传输的可靠性要求有多高,以及对实时性和效率的要求有多高**。
当**数据准确性和完整性至关重要,一点都不能出错**时,通常选择 TCP。因为 TCP 提供了一整套机制(三次握手、确认应答、重传、流量控制等)来保证数据能够可靠、有序地送达。典型应用场景如下:
-- **Web 浏览 (HTTP/HTTPS):** 网页内容、图片、脚本必须完整加载才能正确显示。
-- **文件传输 (FTP, SCP):** 文件内容不允许有任何字节丢失或错序。
-- **邮件收发 (SMTP, POP3, IMAP):** 邮件内容需要完整无误地送达。
-- **远程登录 (SSH, Telnet):** 命令和响应需要准确传输。
-- ......
+- **Web 浏览(HTTP/HTTPS):** 网页内容、图片、脚本必须完整加载才能正确显示。
+- **文件传输(FTP, SCP):** 文件内容不允许有任何字节丢失或错序。
+- **邮件收发(SMTP, POP3, IMAP):** 邮件内容需要完整无误地送达。
+- **远程登录(SSH, Telnet):** 命令和响应需要准确传输。
+- ……
当**实时性、速度和效率优先,并且应用能容忍少量数据丢失或乱序**时,通常选择 UDP。UDP 开销小、传输快,没有建立连接和保证可靠性的复杂过程。典型应用场景如下:
-- **实时音视频通信 (VoIP, 视频会议, 直播):** 偶尔丢失一两个数据包(可能导致画面或声音短暂卡顿)通常比因为等待重传(TCP 机制)导致长时间延迟更可接受。应用层可能会有自己的补偿机制。
+- **实时音视频通信(VoIP, 视频会议,直播):** 偶尔丢失一两个数据包(可能导致画面或声音短暂卡顿)通常比因为等待重传(TCP 机制)导致长时间延迟更可接受。应用层可能会有自己的补偿机制。
- **在线游戏:** 需要快速传输玩家位置、状态等信息,对实时性要求极高,旧的数据很快就没用了,丢失少量数据影响通常不大。
-- **DHCP (动态主机配置协议):** 客户端在请求 IP 时自身没有 IP 地址,无法满足 TCP 建立连接的前提条件,并且 DHCP 有广播需求、交互模式简单以及自带可靠性机制。
-- **物联网 (IoT) 数据上报:** 某些场景下,传感器定期上报数据,丢失个别数据点可能不影响整体趋势分析。
-- ......
+- **DHCP(动态主机配置协议):** 客户端在请求 IP 时自身没有 IP 地址,无法满足 TCP 建立连接的前提条件,并且 DHCP 有广播需求、交互模式简单以及自带可靠性机制。
+- **物联网(IoT)数据上报:** 某些场景下,传感器定期上报数据,丢失个别数据点可能不影响整体趋势分析。
+- ……
### HTTP 基于 TCP 还是 UDP?
@@ -73,21 +80,21 @@ tag:
🐛 修正(参见 [issue#1915](https://github.com/Snailclimb/JavaGuide/issues/1915)):
-HTTP/3.0 之前是基于 TCP 协议的,而 HTTP/3.0 将弃用 TCP,改用 **基于 UDP 的 QUIC 协议** :
+HTTP/3.0 之前是基于 TCP 协议的,而 HTTP/3.0 将弃用 TCP,改用 **基于 UDP 的 QUIC 协议**:
- **HTTP/1.x 和 HTTP/2.0**:这两个版本的 HTTP 协议都明确建立在 TCP 之上。TCP 提供了可靠的、面向连接的传输,确保数据按序、无差错地到达,这对于网页内容的正确展示非常重要。发送 HTTP 请求前,需要先通过 TCP 的三次握手建立连接。
- **HTTP/3.0**:这是一个重大的改变。HTTP/3 弃用了 TCP,转而使用 QUIC 协议,而 QUIC 是构建在 UDP 之上的。
-
+
**为什么 HTTP/3 要做这个改变呢?主要有两大原因:**
-1. 解决队头阻塞 (Head-of-Line Blocking,简写:HOL blocking) 问题。
+1. 解决队头阻塞(Head-of-Line Blocking,简写:HOL blocking)问题。
2. 减少连接建立的延迟。
下面我们来详细介绍这两大优化。
-在 HTTP/2 中,虽然可以在一个 TCP 连接上并发传输多个请求/响应流(多路复用),但 TCP 本身的特性(保证有序、可靠)意味着如果其中一个流的某个 TCP 报文丢失或延迟,整个 TCP 连接都会被阻塞,等待该报文重传。这会导致所有在这个 TCP 连接上的 HTTP/2 流都受到影响,即使其他流的数据包已经到达。**QUIC (运行在 UDP 上) 解决了这个问题**。QUIC 内部实现了自己的多路复用和流控制机制。不同的 HTTP 请求/响应流在 QUIC 层面是真正独立的。如果一个流的数据包丢失,它只会阻塞该流,而不会影响同一 QUIC 连接上的其他流(本质上是多路复用+轮询),大大提高了并发传输的效率。
+在 HTTP/2 中,虽然可以在一个 TCP 连接上并发传输多个请求/响应流(多路复用),但 TCP 本身的特性(保证有序、可靠)意味着如果其中一个流的某个 TCP 报文丢失或延迟,整个 TCP 连接都会被阻塞,等待该报文重传。这会导致所有在这个 TCP 连接上的 HTTP/2 流都受到影响,即使其他流的数据包已经到达。**QUIC(运行在 UDP 上)解决了这个问题**。QUIC 内部实现了自己的多路复用和流控制机制。不同的 HTTP 请求/响应流在 QUIC 层面是真正独立的。如果一个流的数据包丢失,它只会阻塞该流,而不会影响同一 QUIC 连接上的其他流(本质上是多路复用+轮询),大大提高了并发传输的效率。
除了解决队头阻塞问题,HTTP/3.0 还可以减少握手过程的延迟。在 HTTP/2.0 中,如果要建立一个安全的 HTTPS 连接,需要经过 TCP 三次握手和 TLS 握手:
@@ -101,57 +108,150 @@ HTTP/3.0 之前是基于 TCP 协议的,而 HTTP/3.0 将弃用 TCP,改用 **
-
-
-
- 从一次线上问题说起,详解 TCP 半连接队列、全连接队列:
+- RFC 9293: Transmission Control Protocol(TCP):
+- RFC 1122: Requirements for Internet Hosts - Communication Layers:
+- RFC 1337: TIME-WAIT Assassination Hazards in TCP:
+- tcp(7) - Linux manual page:
+- Linux 内核 ip-sysctl 文档:
+- Linux 内核 `include/net/tcp.h`:
+- SoByte - 为什么 TCP 需要 TIME_WAIT 状态:
-7. TCP 之滑动窗口原理 :
-
-
+3. TCP and UDP Tutorial:
+4. Computer Network:
+5. TCP Flow Control:
+7. TCP 之滑动窗口原理:
+8. RFC 9293 - Transmission Control Protocol:
+9. RFC 6928 - Increasing TCP's Initial Window:
+10. RFC 5681 - TCP Congestion Control:
+11. RFC 2018 - TCP Selective Acknowledgment Options:
+12. RFC 2883 - An Extension to the Selective Acknowledgement(SACK) Option for TCP:
+13. RFC 9438 - CUBIC for Fast and Long-Distance Networks:
+14. RFC 8257 - Data Center TCP(DCTCP):
+15. BBR: Congestion-Based Congestion Control, ACM Queue, 2016:
+16. RFC 1122 - Requirements for Internet Hosts - Communication Layers:
+17. RFC 6298 - Computing TCP's Retransmission Timer:
+18. RFC 7323 - TCP Extensions for High Performance:
+- RFC 1337: TIME-WAIT Assassination Hazards in TCP:
+- Linux 内核 ip-sysctl 文档:
+- SoByte - 为什么 TCP 需要 TIME_WAIT 状态:  -
- diff --git a/README_EN.md b/README_EN.md
new file mode 100644
index 00000000000..9d2228cf75c
--- /dev/null
+++ b/README_EN.md
@@ -0,0 +1,449 @@
+# JavaGuide
+
+**English** | **[日本語](./README_JA.md)** | **[简体中文](./README.md)**
+
+Recommended to read online for a better experience and faster speed: [javaguide.cn](https://javaguide.cn/)
+
+## AI Application Development Interview Guide
+
+An open-source guide for backend developers on AI application development, AI programming practices, and interviews, covering core technologies and engineering practices such as LLM, Agent, RAG, MCP, Claude Code, Codex, and more. Benchmarking JavaGuide! If it helps, welcome to Star!
+
+- **Project URL**: [https://github.com/Snailclimb/AIGuide](https://github.com/Snailclimb/AIGuide)
+- **Online Reading**: [https://javaguide.cn/ai/](https://javaguide.cn/ai/)
+
+## Backend Interview Preparation
+
+- [⭐Java Backend Interview Preparation Plan (Covering General Backend System)](./docs/interview-preparation/backend-interview-plan.md) (Must-read :+1:)
+- [How to Efficiently Prepare for Java Interviews?](./docs/interview-preparation/teach-you-how-to-prepare-for-the-interview-hand-in-hand.md)
+- [Key Summary of Java Backend Interviews](./docs/interview-preparation/key-points-of-interview.md)
+- [Java Learning Roadmap (Latest, 4w+ Words)](./docs/interview-preparation/java-roadmap.md)
+- [Programmer Resume Writing Guide](./docs/interview-preparation/resume-guide.md)
+- [Project Experience Guide](./docs/interview-preparation/project-experience-guide.md)
+- [How to Deal with Interview Nervousness?](./docs/interview-preparation/how-to-handle-interview-nerves.md)
+- [What to Do Without Internship Experience in Campus Recruitment? How to Write About Internship Experience?](./docs/interview-preparation/internship-experience.md)
+
+## Java
+
+### Java Basics
+
+**Knowledge Points/Interview Questions Summary** (Must-read :+1:):
+
+- [Summary of Common Java Basics Knowledge Points & Interview Questions (Part 1)](./docs/java/basis/java-basic-questions-01.md)
+- [Summary of Common Java Basics Knowledge Points & Interview Questions (Part 2)](./docs/java/basis/java-basic-questions-02.md)
+- [Summary of Common Java Basics Knowledge Points & Interview Questions (Part 3)](./docs/java/basis/java-basic-questions-03.md)
+
+**Important Knowledge Points Explanation**:
+
+- [Why is There Only Pass-by-Value in Java?](./docs/java/basis/why-there-only-value-passing-in-java.md)
+- [Serialization in Java Explained](./docs/java/basis/serialization.md)
+- [Generics & Wildcards Explained](./docs/java/basis/generics-and-wildcards.md)
+- [Java Reflection Mechanism Explained](./docs/java/basis/reflection.md)
+- [Java Proxy Pattern Explained](./docs/java/basis/proxy.md)
+- [BigDecimal Explained](./docs/java/basis/bigdecimal.md)
+- [Java Magic Class Unsafe Explained](./docs/java/basis/unsafe.md)
+- [Java SPI Mechanism Explained](./docs/java/basis/spi.md)
+- [Java Syntactic Sugar Explained](./docs/java/basis/syntactic-sugar.md)
+
+### Collections
+
+**Knowledge Points/Interview Questions Summary**:
+
+- [Summary of Common Java Collection Knowledge Points & Interview Questions (Part 1)](./docs/java/collection/java-collection-questions-01.md) (Must-read :+1:)
+- [Summary of Common Java Collection Knowledge Points & Interview Questions (Part 2)](./docs/java/collection/java-collection-questions-02.md) (Must-read :+1:)
+- [Summary of Java Container Usage Precautions](./docs/java/collection/java-collection-precautions-for-use.md)
+
+**Source Code Analysis**:
+
+- [ArrayList Core Source Code + Expansion Mechanism Analysis](./docs/java/collection/arraylist-source-code.md)
+- [LinkedList Core Source Code Analysis](./docs/java/collection/linkedlist-source-code.md)
+- [HashMap Core Source Code + Underlying Data Structure Analysis](./docs/java/collection/hashmap-source-code.md)
+- [ConcurrentHashMap Core Source Code + Underlying Data Structure Analysis](./docs/java/collection/concurrent-hash-map-source-code.md)
+- [LinkedHashMap Core Source Code Analysis](./docs/java/collection/linkedhashmap-source-code.md)
+- [CopyOnWriteArrayList Core Source Code Analysis](./docs/java/collection/copyonwritearraylist-source-code.md)
+- [ArrayBlockingQueue Core Source Code Analysis](./docs/java/collection/arrayblockingqueue-source-code.md)
+- [PriorityQueue Core Source Code Analysis](./docs/java/collection/priorityqueue-source-code.md)
+- [DelayQueue Core Source Code Analysis](./docs/java/collection/delayqueue-source-code.md)
+
+### IO
+
+- [IO Basic Knowledge Summary](./docs/java/io/io-basis.md)
+- [IO Design Patterns Summary](./docs/java/io/io-design-patterns.md)
+- [IO Model Explanation](./docs/java/io/io-model.md)
+- [NIO Core Knowledge Summary](./docs/java/io/nio-basis.md)
+
+### Concurrency
+
+**Knowledge Points/Interview Questions Summary** (Must-read :+1:)
+
+- [Common Java Concurrency Knowledge Points & Interview Questions Summary (Part 1)](./docs/java/concurrent/java-concurrent-questions-01.md)
+- [Common Java Concurrency Knowledge Points & Interview Questions Summary (Part 2)](./docs/java/concurrent/java-concurrent-questions-02.md)
+- [Common Java Concurrency Knowledge Points & Interview Questions Summary (Part 3)](./docs/java/concurrent/java-concurrent-questions-03.md)
+
+**Important Knowledge Points Explanation**:
+
+- [Optimistic Lock and Pessimistic Lock Explanation](./docs/java/concurrent/optimistic-lock-and-pessimistic-lock.md)
+- [CAS Explanation](./docs/java/concurrent/cas.md)
+- [JMM (Java Memory Model) Explanation](./docs/java/concurrent/jmm.md)
+- **Thread Pool**: [Java Thread Pool Explanation](./docs/java/concurrent/java-thread-pool-summary.md), [Java Thread Pool Best Practices](./docs/java/concurrent/java-thread-pool-best-practices.md)
+- [ThreadLocal Explanation](./docs/java/concurrent/threadlocal.md)
+- [Java Concurrent Collections Summary](./docs/java/concurrent/java-concurrent-collections.md)
+- [Atomic Classes Summary](./docs/java/concurrent/atomic-classes.md)
+- [AQS Explanation](./docs/java/concurrent/aqs.md)
+- [CompletableFuture Explanation](./docs/java/concurrent/completablefuture-intro.md)
+
+### JVM (Must-read :+1:)
+
+The JVM part mainly refers to the [JVM Specification - Java 8](https://docs.oracle.com/javase/specs/jvms/se8/html/index.html) and Zhou Zhiming's book [《Deep Understanding of Java Virtual Machine (3rd Edition)》](https://book.douban.com/subject/34907497/) (strongly recommend to read it several times!).
+
+- **[Java Memory Area](./docs/java/jvm/memory-area.md)**
+- **[JVM Garbage Collection](./docs/java/jvm/jvm-garbage-collection.md)**
+- [Class File Structure](./docs/java/jvm/class-file-structure.md)
+- **[Class Loading Process](./docs/java/jvm/class-loading-process.md)**
+- [Class Loader](./docs/java/jvm/classloader.md)
+- [【To Be Completed】Most Important JVM Parameters Summary (Half Translated)](./docs/java/jvm/jvm-parameters-intro.md)
+- [【Bonus】Understand JVM in Plain Language](./docs/java/jvm/jvm-intro.md)
+- [JDK Monitoring and Troubleshooting Tools](./docs/java/jvm/jdk-monitoring-and-troubleshooting-tools.md)
+
+### New Features
+
+- **Java 8**: [Java 8 New Features Summary (Translated)](./docs/java/new-features/java8-tutorial-translate.md), [Common Java 8 New Features Summary](./docs/java/new-features/java8-common-new-features.md)
+- [Java 9 New Features Overview](./docs/java/new-features/java9.md)
+- [Java 10 New Features Overview](./docs/java/new-features/java10.md)
+- [Java 11 New Features Overview](./docs/java/new-features/java11.md)
+- [Java 12 & 13 New Features Overview](./docs/java/new-features/java12-13.md)
+- [Java 14 & 15 New Features Overview](./docs/java/new-features/java14-15.md)
+- [Java 16 New Features Overview](./docs/java/new-features/java16.md)
+- [Java 17 New Features Overview](./docs/java/new-features/java17.md)
+- [Java 18 New Features Overview](./docs/java/new-features/java18.md)
+- [Java 19 New Features Overview](./docs/java/new-features/java19.md)
+- [Java 20 New Features Overview](./docs/java/new-features/java20.md)
+- [Java 21 New Features Overview](./docs/java/new-features/java21.md)
+- [Java 22 & 23 New Features Overview](./docs/java/new-features/java22-23.md)
+- [Java 24 New Features Overview](./docs/java/new-features/java24.md)
+- [Java 25 New Features Overview](./docs/java/new-features/java25.md)
+
+## Computer Fundamentals
+
+### Operating Systems
+
+- [Summary of Common Operating System Knowledge Points & Interview Questions (Part 1)](./docs/cs-basics/operating-system/operating-system-basic-questions-01.md)
+- [Summary of Common Operating System Knowledge Points & Interview Questions (Part 2)](./docs/cs-basics/operating-system/operating-system-basic-questions-02.md)
+- **Linux**:
+ - [Summary of Essential Linux Basics for Backend Developers](./docs/cs-basics/operating-system/linux-intro.md)
+ - [Summary of Shell Scripting Basics](./docs/cs-basics/operating-system/shell-intro.md)
+
+### Networking
+
+**Knowledge Points/Interview Questions Summary**:
+
+- [Summary of Common Computer Network Knowledge Points & Interview Questions (Part 1)](./docs/cs-basics/network/other-network-questions.md)
+- [Summary of Common Computer Network Knowledge Points & Interview Questions (Part 2)](./docs/cs-basics/network/other-network-questions2.md)
+- [Summary of Professor Xie Xiren's "Computer Network" Content (Supplementary)](./docs/cs-basics/network/computer-network-xiexiren-summary.md)
+
+**Important Knowledge Points Explanation**:
+
+- [Detailed Explanation of the OSI and TCP/IP Network Layer Models (Basics)](./docs/cs-basics/network/osi-and-tcp-ip-model.md)
+- [Summary of Common Application Layer Protocols (Application Layer)](./docs/cs-basics/network/application-layer-protocol.md)
+- [HTTP vs HTTPS (Application Layer)](./docs/cs-basics/network/http-vs-https.md)
+- [HTTP 1.0 vs HTTP 1.1 (Application Layer)](./docs/cs-basics/network/http1.0-vs-http1.1.md)
+- [Common HTTP Status Codes (Application Layer)](./docs/cs-basics/network/http-status-codes.md)
+- [Detailed Explanation of the DNS Domain Name System (Application Layer)](./docs/cs-basics/network/dns.md)
+- [TCP Three-Way Handshake and Four-Way Termination (Transport Layer)](./docs/cs-basics/network/tcp-connection-and-disconnection.md)
+- [What's the Difference Between TCP Keepalive and HTTP Keep-Alive? (Transport Layer)](./docs/cs-basics/network/tcp-keepalive-vs-http-keepalive.md)
+- [TCP Transmission Reliability Guarantee (Transport Layer)](./docs/cs-basics/network/tcp-reliability-guarantee.md)
+- [If You Can Ping Through, Does TCP Definitely Connect? (Transport Layer)](./docs/cs-basics/network/can-ping-but-tcp-may-not-connect.md)
+- [Can TCP and UDP Use the Same Port? (Transport Layer)](./docs/cs-basics/network/can-tcp-and-udp-use-the-same-port.md)
+- [What's the Maximum Number of TCP Connections a Host Can Maintain? (Transport Layer)](./docs/cs-basics/network/maximum-number-of-tcp-connections-per-host.md)
+- [Detailed Explanation of the ARP Protocol (Network Layer)](./docs/cs-basics/network/arp.md)
+- [Detailed Explanation of the NAT Protocol (Network Layer)](./docs/cs-basics/network/nat.md)
+- [Summary of Common Network Attack Means (Security)](./docs/cs-basics/network/network-attack-means.md)
+
+### Data Structures
+
+**Illustrated Data Structures:**
+
+- [Linear Data Structures: Arrays, Linked Lists, Stacks, Queues](./docs/cs-basics/data-structure/linear-data-structure.md)
+- [Graphs](./docs/cs-basics/data-structure/graph.md)
+- [Heaps](./docs/cs-basics/data-structure/heap.md)
+- [Trees](./docs/cs-basics/data-structure/tree.md): Focus on [Red-Black Trees](./docs/cs-basics/data-structure/red-black-tree.md), B-, B+, B\* Trees, and LSM Trees
+
+Other Commonly Used Data Structures:
+
+- [Bloom Filters](./docs/cs-basics/data-structure/bloom-filter.md)
+
+### Algorithms
+
+The algorithm part is very important. If you don't know how to learn algorithms, you can refer to:
+
+- [Recommended Algorithm Learning Books and Resources](https://www.zhihu.com/question/323359308/answer/1545320858).
+- [How to Solve LeetCode Problems?](https://www.zhihu.com/question/31092580/answer/1534887374)
+
+**Summary of Common Algorithm Problems**:
+
+- [Summary of Several Common String Algorithm Problems](./docs/cs-basics/algorithms/string-algorithm-problems.md)
+- [Summary of Several Common Linked List Algorithm Problems](./docs/cs-basics/algorithms/linkedlist-algorithm-problems.md)
+- [Part of the Coding Questions from the "Sword Refers to Offer"](./docs/cs-basics/algorithms/the-sword-refers-to-offer.md)
+- [Ten Classic Sorting Algorithms](./docs/cs-basics/algorithms/10-classical-sorting-algorithms.md)
+
+Additionally, [GeeksforGeeks](https://www.geeksforgeeks.org/fundamentals-of-algorithms/) has a comprehensive summary of common algorithms.
+
+## Database
+
+### Database Basics
+
+- [Summary of Database Basics](./docs/database/basis.md)
+- [Summary of NoSQL Basics](./docs/database/nosql.md)
+- [Explanation of Character Sets](./docs/database/character-set.md)
+- SQL:
+ - [Summary of SQL Syntax Basics](./docs/database/sql/sql-syntax-summary.md)
+ - [Summary of Common SQL Interview Questions](./docs/database/sql/sql-questions-01.md)
+
+### MySQL
+
+**Knowledge Points/Interview Questions Summary:**
+
+- **[MySQL Common Knowledge Points & Interview Questions Summary](./docs/database/mysql/mysql-questions-01.md)** (Must-read :+1:)
+- [MySQL High-Performance Optimization Specification Recommendations](./docs/database/mysql/mysql-high-performance-optimization-specification-recommendations.md)
+
+**Important Knowledge Points:**
+
+- [MySQL Index Details](./docs/database/mysql/mysql-index.md)
+- [Summary of MySQL Index Invalidation Scenarios](./docs/database/mysql/mysql-index-invalidation.md)
+- [Detailed Explanation of MySQL Transaction Isolation Levels (with Pictures)](./docs/database/mysql/transaction-isolation-level.md)
+- [Detailed Explanation of MySQL's Three Logs (binlog, redo log, and undo log)](./docs/database/mysql/mysql-logs.md)
+- [InnoDB Storage Engine's Implementation of MVCC](./docs/database/mysql/innodb-implementation-of-mvcc.md)
+- [How SQL Statements are Executed in MySQL](./docs/database/mysql/how-sql-executed-in-mysql.md)
+- [Detailed Explanation of MySQL Query Cache](./docs/database/mysql/mysql-query-cache.md)
+- [MySQL Query Execution Plan Analysis](./docs/database/mysql/mysql-query-execution-plan.md)
+- [Are MySQL Auto-Increment Primary Keys Always Continuous?](./docs/database/mysql/mysql-auto-increment-primary-key-continuous.md)
+- [Suggestions on Storing Time-Related Data in MySQL](./docs/database/mysql/some-thoughts-on-database-storage-time.md)
+- [Index Invalidation Caused by Implicit Conversion in MySQL](./docs/database/mysql/index-invalidation-caused-by-implicit-conversion.md)
+
+### Redis
+
+**Knowledge Points/Interview Questions Summary** (Must-read :+1:):
+
+- [Redis Common Knowledge Points & Interview Questions Summary (Part 1)](./docs/database/redis/redis-questions-01.md)
+- [Redis Common Knowledge Points & Interview Questions Summary (Part 2)](./docs/database/redis/redis-questions-02.md)
+
+**Important Knowledge Points:**
+
+- [Detailed Explanation of 3 Common Cache Read and Write Strategies](./docs/database/redis/3-commonly-used-cache-read-and-write-strategies.md)
+- [Can Redis Be Used as a Message Queue? How to Implement It?](./docs/database/redis/redis-stream-mq.md)
+- [Detailed Explanation of Redis' 5 Basic Data Structures](./docs/database/redis/redis-data-structures-01.md)
+- [Detailed Explanation of Redis' 3 Special Data Structures](./docs/database/redis/redis-data-structures-02.md)
+- [Detailed Explanation of Redis Persistence Mechanism](./docs/database/redis/redis-persistence.md)
+- [Detailed Explanation of Redis Memory Fragmentation](./docs/database/redis/redis-memory-fragmentation.md)
+- [Summary of Common Causes of Redis Blocking](./docs/database/redis/redis-common-blocking-problems-summary.md)
+- [Detailed Explanation of Redis Cluster](./docs/database/redis/redis-cluster.md)
+
+### MongoDB
+
+- [MongoDB Common Knowledge Points & Interview Questions Summary (Part 1)](./docs/database/mongodb/mongodb-questions-01.md)
+- [MongoDB Common Knowledge Points & Interview Questions Summary (Part 2)](./docs/database/mongodb/mongodb-questions-02.md)
+
+## Search Engines
+
+[Elasticsearch Common Interview Questions Summary (Paid)](./docs/database/elasticsearch/elasticsearch-questions-01.md)
+
+
+
+## Development Tools
+
+### Maven
+
+- [Maven Core Concepts Summary](./docs/tools/maven/maven-core-concepts.md)
+- [Maven Best Practices](./docs/tools/maven/maven-best-practices.md)
+
+### Gradle
+
+[Gradle Core Concepts Summary](./docs/tools/gradle/gradle-core-concepts.md) (Optional, Maven is still more widely used in China)
+
+### Docker
+
+- [Docker Core Concepts Summary](./docs/tools/docker/docker-intro.md)
+- [Docker in Action](./docs/tools/docker/docker-in-action.md)
+
+### Git
+
+- [Git Core Concepts Summary](./docs/tools/git/git-intro.md)
+- [Useful GitHub Tips Summary](./docs/tools/git/github-tips.md)
+
+## System Design
+
+- [⭐Common System Design Interview Questions Summary](./docs/system-design/system-design-questions.md)
+- [⭐Common Design Pattern Interview Questions Summary](https://interview.javaguide.cn/system-design/design-pattern.html)
+
+### System Design Basics
+
+- [A Brief Tutorial on RESTful API](./docs/system-design/basis/RESTfulAPI.md)
+- [A Brief Tutorial on Software Engineering](./docs/system-design/basis/software-engineering.md)
+- [Code Naming Guide](./docs/system-design/basis/naming.md)
+- [Code Refactoring Guide](./docs/system-design/basis/refactoring.md)
+- [Unit Testing Guide](./docs/system-design/basis/unit-test.md)
+
+### Common Frameworks
+
+#### Spring/SpringBoot (Must-read :+1:)
+
+**Knowledge Points/Interview Questions Summary**:
+
+- [Summary of Common Spring Knowledge Points and Interview Questions](./docs/system-design/framework/spring/spring-knowledge-and-questions-summary.md)
+- [Summary of Common SpringBoot Knowledge Points and Interview Questions](./docs/system-design/framework/spring/springboot-knowledge-and-questions-summary.md)
+- [Summary of Common Spring/Spring Boot Annotations](./docs/system-design/framework/spring/spring-common-annotations.md)
+- [SpringBoot Beginner's Guide](https://github.com/Snailclimb/springboot-guide)
+
+**Detailed Explanation of Important Knowledge Points**:
+
+- [Detailed Explanation of IoC & AOP (Quick Understanding)](./docs/system-design/framework/spring/ioc-and-aop.md)
+- [Detailed Explanation of Spring Transactions](./docs/system-design/framework/spring/spring-transaction.md)
+- [Detailed Explanation of Design Patterns in Spring](./docs/system-design/framework/spring/spring-design-patterns-summary.md)
+- [Detailed Explanation of SpringBoot Auto-Configuration Principles](./docs/system-design/framework/spring/spring-boot-auto-assembly-principles.md)
+
+#### MyBatis
+
+[Summary of Common MyBatis Interview Questions](./docs/system-design/framework/mybatis/mybatis-interview.md)
+
+### Security
+
+#### Authentication and Authorization
+
+- [Detailed Explanation of Authentication and Authorization Fundamentals](./docs/system-design/security/basis-of-authority-certification.md)
+- [Detailed Explanation of JWT Basics](./docs/system-design/security/jwt-intro.md)
+- [Analysis of Advantages and Disadvantages of JWT and Common Problem Solutions](./docs/system-design/security/advantages-and-disadvantages-of-jwt.md)
+- [Detailed Explanation of SSO (Single Sign-On)](./docs/system-design/security/sso-intro.md)
+- [Detailed Explanation of Permission System Design](./docs/system-design/security/design-of-authority-system.md)
+
+#### Data Security
+
+- [Summary of Common Encryption Algorithms](./docs/system-design/security/encryption-algorithms.md)
+- [Summary of Sensitive Word Filtering Solutions](./docs/system-design/security/sentive-words-filter.md)
+- [Summary of Data Desensitization Solutions](./docs/system-design/security/data-desensitization.md)
+- [Why Both Front-end and Back-end Need to Perform Data Validation](./docs/system-design/security/data-validation.md)
+- [Why Can Passwords Only Be Reset When Forgotten, Not Told the Original Password?](./docs/system-design/security/why-password-reset-instead-of-retrieval.md)
+
+### Scheduled Tasks
+
+[Detailed Explanation of Java Scheduled Tasks](./docs/system-design/schedule-task.md)
+
+### Web Real-time Message Pushing
+
+[Detailed Explanation of Web Real-time Message Pushing](./docs/system-design/web-real-time-message-push.md)
+
+## Distributed System
+
+- [⭐High-Frequency Distributed System Interview Questions](https://interview.javaguide.cn/distributed-system/distributed-system.html)
+
+### Theory, Algorithms, and Protocols
+
+- [Interpretation of CAP Theory and BASE Theory](https://javaguide.cn/distributed-system/protocol/cap-and-base-theorem.html)
+- [Interpretation of Paxos Algorithm](https://javaguide.cn/distributed-system/protocol/paxos-algorithm.html)
+- [Interpretation of Raft Algorithm](https://javaguide.cn/distributed-system/protocol/raft-algorithm.html)
+- [Interpretation of ZAB Protocol](https://javaguide.cn/distributed-system/protocol/zab.html)
+- [Detailed Explanation of Gossip Protocol](https://javaguide.cn/distributed-system/protocol/gossip-protocol.html)
+- [Detailed Explanation of Consistent Hashing Algorithm](https://javaguide.cn/distributed-system/protocol/consistent-hashing.html)
+
+### RPC
+
+- [Summary of RPC Basics](https://javaguide.cn/distributed-system/rpc/rpc-intro.html)
+- [Summary of Common Dubbo Knowledge Points and Interview Questions](https://javaguide.cn/distributed-system/rpc/dubbo.html)
+
+### ZooKeeper
+
+> These two articles may have some overlapping content, it is recommended to read both.
+
+- [Summary of ZooKeeper Relevant Concepts (Beginner)](https://javaguide.cn/distributed-system/distributed-process-coordination/zookeeper/zookeeper-intro.html)
+- [Summary of ZooKeeper Relevant Concepts (Advanced)](https://javaguide.cn/distributed-system/distributed-process-coordination/zookeeper/zookeeper-plus.html)
+
+### API Gateway
+
+- [Summary of API Gateway Basics](https://javaguide.cn/distributed-system/api-gateway.html)
+- [Summary of Common Spring Cloud Gateway Knowledge Points and Interview Questions](./docs/distributed-system/spring-cloud-gateway-questions.md)
+
+### Distributed ID
+
+- [Introduction to Distributed ID and Summary of Implementation Solutions](https://javaguide.cn/distributed-system/distributed-id.html)
+- [Design Guide for Distributed ID](https://javaguide.cn/distributed-system/distributed-id-design.html)
+
+### Distributed Lock
+
+- [Introduction to Distributed Locks](https://javaguide.cn/distributed-system/distributed-lock.html)
+- [Summary of Common Distributed Lock Implementation Solutions](https://javaguide.cn/distributed-system/distributed-lock-implementations.html)
+
+### Distributed Transactions
+
+[Summary of Common Distributed Transaction Knowledge Points and Interview Questions](https://javaguide.cn/distributed-system/distributed-transaction.html)
+
+### Distributed Configuration Center
+
+[Summary of Common Distributed Configuration Center Knowledge Points and Interview Questions](./docs/distributed-system/distributed-configuration-center.md)
+
+## High Performance
+
+### Database Optimization
+
+- [Database Read-Write Separation and Database Sharding](./docs/high-performance/read-and-write-separation-and-library-subtable.md)
+- [Data Separation of Cold and Hot Data](./docs/high-performance/data-cold-hot-separation.md)
+- [Summary of Common SQL Optimization Methods](./docs/high-performance/sql-optimization.md)
+- [Introduction to Deep Pagination and Optimization Suggestions](./docs/high-performance/deep-pagination-optimization.md)
+
+### Load Balancing
+
+[Summary of Common Load Balancing Knowledge Points and Interview Questions](./docs/high-performance/load-balancing.md)
+
+### CDN
+
+[Summary of Common CDN (Content Delivery Network) Knowledge Points and Interview Questions](./docs/high-performance/cdn.md)
+
+### Message Queue
+
+- [Summary of Message Queue Basic Knowledge](./docs/high-performance/message-queue/message-queue.md)
+- [Summary of Common Disruptor Knowledge Points and Interview Questions](./docs/high-performance/message-queue/disruptor-questions.md)
+- [Summary of Common RabbitMQ Knowledge Points and Interview Questions](./docs/high-performance/message-queue/rabbitmq-questions.md)
+- [Summary of Common RocketMQ Knowledge Points and Interview Questions](./docs/high-performance/message-queue/rocketmq-questions.md)
+- [Summary of Common Kafka Knowledge Points and Interview Questions](./docs/high-performance/message-queue/kafka-questions-01.md)
+
+## High Availability
+
+[Guide to High Availability System Design](./docs/high-availability/high-availability-system-design.md)
+
+### Redundancy Design
+
+[Detailed Explanation of Redundancy Design](./docs/high-availability/redundancy.md)
+
+### Rate Limiting
+
+[Detailed Explanation of Service Rate Limiting](./docs/high-availability/limit-request.md)
+
+### Fallback & Circuit Breaker
+
+[Detailed Explanation of Fallback & Circuit Breaker](./docs/high-availability/fallback-and-circuit-breaker.md)
+
+### Timeout & Retry
+
+[Detailed Explanation of Timeout & Retry](./docs/high-availability/timeout-and-retry.md)
+
+### Clustering
+
+Deploying multiple instances of the same service to avoid single point of failure.
+
+### Disaster Recovery Design and Active-Active Deployment
+
+**Disaster Recovery** = Disaster Tolerance + Backup.
+
+- **Backup**: Backing up all important data generated by the system multiple times.
+- **Disaster Tolerance**: Establishing two completely identical systems in different locations. When the system in one location suddenly fails, the entire application system can be switched to the other one, so that the system can continue to provide services normally.
+
+**Active-Active Deployment** describes deploying services in different locations and simultaneously providing services externally. The main difference from traditional disaster recovery design is the "active-active" nature, i.e., all sites are simultaneously providing external services. Active-active deployment is to cope with unexpected situations such as fires, earthquakes and other natural or man-made disasters.
+
+## Star Trend
+
+
+
+## Official Public Account
+
+If you want to stay up-to-date with my latest articles and share my valuable content, you can follow my official public account.
+
+
+
+
diff --git a/README_JA.md b/README_JA.md
new file mode 100644
index 00000000000..b715a9cfb74
--- /dev/null
+++ b/README_JA.md
@@ -0,0 +1,432 @@
+**[English](./README_EN.md)** | **日本語** | **[简体中文](./README.md)**
+
+より快適でスピーディーな体験のため、オンライン閲覧プラットフォームでの閲覧をおすすめします!リンク: [javaguide.cn](https://javaguide.cn/)。
+
+## プロジェクト関連
+
+- [プロジェクト紹介](https://javaguide.cn/javaguide/intro.html)
+- [使い方の提案](https://javaguide.cn/javaguide/use-suggestion.html)
+- [コントリビューションガイド](https://javaguide.cn/javaguide/contribution-guideline.html)
+- [FAQ](https://javaguide.cn/javaguide/faq.html)
+
+## Java
+
+### 基礎
+
+**知識ポイント/面接問題のまとめ**: (必見 :+1:):
+
+- [Java 基礎のよく出る知識ポイント&面接問題まとめ(その 1)](./docs/java/basis/java-basic-questions-01.md)
+- [Java 基礎のよく出る知識ポイント&面接問題まとめ(その 2)](./docs/java/basis/java-basic-questions-02.md)
+- [Java 基礎のよく出る知識ポイント&面接問題まとめ(その 3)](./docs/java/basis/java-basic-questions-03.md)
+
+**重要な知識ポイントの解説**:
+
+- [Java はなぜ値渡ししかないのか?](./docs/java/basis/why-there-only-value-passing-in-java.md)
+- [Java のシリアライズ詳解](./docs/java/basis/serialization.md)
+- [ジェネリクス&ワイルドカード詳解](./docs/java/basis/generics-and-wildcards.md)
+- [Java リフレクション機構詳解](./docs/java/basis/reflection.md)
+- [Java プロキシパターン詳解](./docs/java/basis/proxy.md)
+- [BigDecimal 詳解](./docs/java/basis/bigdecimal.md)
+- [Java のマジッククラス Unsafe 詳解](./docs/java/basis/unsafe.md)
+- [Java SPI 機構詳解](./docs/java/basis/spi.md)
+- [Java のシンタックスシュガー詳解](./docs/java/basis/syntactic-sugar.md)
+
+### コレクション
+
+**知識ポイント/面接問題のまとめ**:
+
+- [Java コレクションのよく出る知識ポイント&面接問題まとめ(その 1)](./docs/java/collection/java-collection-questions-01.md) (必見 :+1:)
+- [Java コレクションのよく出る知識ポイント&面接問題まとめ(その 2)](./docs/java/collection/java-collection-questions-02.md) (必見 :+1:)
+- [Java コンテナ使用上の注意点まとめ](./docs/java/collection/java-collection-precautions-for-use.md)
+
+**ソースコード解析**:
+
+- [ArrayList コアソースコード+拡張メカニズム解析](./docs/java/collection/arraylist-source-code.md)
+- [LinkedList コアソースコード解析](./docs/java/collection/linkedlist-source-code.md)
+- [HashMap コアソースコード+基盤データ構造解析](./docs/java/collection/hashmap-source-code.md)
+
+# Java コレクション&並行処理シリーズ
+
+## コレクション
+
+- [ConcurrentHashMap コアソースコード+基盤データ構造解析](./docs/java/collection/concurrent-hash-map-source-code.md)
+- [LinkedHashMap コアソースコード解析](./docs/java/collection/linkedhashmap-source-code.md)
+- [CopyOnWriteArrayList コアソースコード解析](./docs/java/collection/copyonwritearraylist-source-code.md)
+- [ArrayBlockingQueue コアソースコード解析](./docs/java/collection/arrayblockingqueue-source-code.md)
+- [PriorityQueue コアソースコード解析](./docs/java/collection/priorityqueue-source-code.md)
+- [DelayQueue コアソースコード解析](./docs/java/collection/delayqueue-source-code.md)
+
+### IO
+
+- [IO 基礎知識まとめ](./docs/java/io/io-basis.md)
+- [IO デザインパターンまとめ](./docs/java/io/io-design-patterns.md)
+- [IO モデル詳解](./docs/java/io/io-model.md)
+- [NIO コア知識まとめ](./docs/java/io/nio-basis.md)
+
+### 並行処理
+
+**知識ポイント/面接問題のまとめ** : (必読 :+1:)
+
+- [Java 並行処理のよく出る知識ポイント&面接問題まとめ(その 1)](./docs/java/concurrent/java-concurrent-questions-01.md)
+- [Java 並行処理のよく出る知識ポイント&面接問題まとめ(その 2)](./docs/java/concurrent/java-concurrent-questions-02.md)
+- [Java 並行処理のよく出る知識ポイント&面接問題まとめ(その 3)](./docs/java/concurrent/java-concurrent-questions-03.md)
+
+**重要な知識ポイントの解説**:
+
+- [楽観ロックと悲観ロック詳解](./docs/java/concurrent/optimistic-lock-and-pessimistic-lock.md)
+- [CAS 詳解](./docs/java/concurrent/cas.md)
+- [JMM(Java メモリモデル)詳解](./docs/java/concurrent/jmm.md)
+- **スレッドプール**: [Java スレッドプール詳解](./docs/java/concurrent/java-thread-pool-summary.md)、[Java スレッドプールのベストプラクティス](./docs/java/concurrent/java-thread-pool-best-practices.md)
+- [ThreadLocal 詳解](./docs/java/concurrent/threadlocal.md)
+- [Java 並行コレクションまとめ](./docs/java/concurrent/java-concurrent-collections.md)
+- [Atomic クラスまとめ](./docs/java/concurrent/atomic-classes.md)
+- [AQS 詳解](./docs/java/concurrent/aqs.md)
+- [CompletableFuture 詳解](./docs/java/concurrent/completablefuture-intro.md)
+
+### JVM (必読 :+1:)
+
+JVM の部分は主に [JVM 仕様 - Java 8](https://docs.oracle.com/javase/specs/jvms/se8/html/index.html) と、周志明氏の著書 [《Java 仮想マシンの深い理解(第 3 版)》](https://book.douban.com/subject/34907497/)(何度も読むことを強くおすすめします!)を参考にしています。
+
+- **[Java メモリ領域](./docs/java/jvm/memory-area.md)**
+- **[JVM ガベージコレクション](./docs/java/jvm/jvm-garbage-collection.md)**
+- [クラスファイルの構造](./docs/java/jvm/class-file-structure.md)
+- **[クラスローディングのプロセス](./docs/java/jvm/class-loading-process.md)**
+- [クラスローダー](./docs/java/jvm/classloader.md)
+- [【未完成】最も重要な JVM パラメータまとめ(一部翻訳)](./docs/java/jvm/jvm-parameters-intro.md)
+- [【おまけ】わかりやすく学ぶ JVM](./docs/java/jvm/jvm-intro.md)
+- [JDK 監視・トラブルシューティングツール](./docs/java/jvm/jdk-monitoring-and-troubleshooting-tools.md)
+
+### 新機能
+
+- **Java 8**: [Java 8 新機能まとめ(翻訳)](./docs/java/new-features/java8-tutorial-translate.md)、[Java 8 のよく使う新機能まとめ](./docs/java/new-features/java8-common-new-features.md)
+- [Java 9 新機能概要](./docs/java/new-features/java9.md)
+- [Java 10 新機能概要](./docs/java/new-features/java10.md)
+- [Java 11 新機能概要](./docs/java/new-features/java11.md)
+- [Java 12 & 13 新機能概要](./docs/java/new-features/java12-13.md)
+- [Java 14 & 15 新機能概要](./docs/java/new-features/java14-15.md)
+- [Java 16 新機能概要](./docs/java/new-features/java16.md)
+- [Java 17 新機能概要](./docs/java/new-features/java17.md)
+- [Java 18 新機能概要](./docs/java/new-features/java18.md)
+- [Java 19 新機能概要](./docs/java/new-features/java19.md)
+- [Java 20 新機能概要](./docs/java/new-features/java20.md)
+
+# Java 21、22、23、24、25 の新機能概要
+
+## コンピュータ基礎
+
+### オペレーティングシステム
+
+- [オペレーティングシステムのよく出る知識ポイント&面接問題まとめ(その 1)](./docs/cs-basics/operating-system/operating-system-basic-questions-01.md)
+- [オペレーティングシステムのよく出る知識ポイント&面接問題まとめ(その 2)](./docs/cs-basics/operating-system/operating-system-basic-questions-02.md)
+- **Linux**:
+ - [バックエンド開発者が押さえておくべき Linux 基礎まとめ](./docs/cs-basics/operating-system/linux-intro.md)
+ - [シェルスクリプト基礎まとめ](./docs/cs-basics/operating-system/shell-intro.md)
+
+### ネットワーク
+
+**知識ポイント/面接問題のまとめ**:
+
+- [コンピュータネットワークのよく出る知識ポイント&面接問題まとめ(その 1)](./docs/cs-basics/network/other-network-questions.md)
+- [コンピュータネットワークのよく出る知識ポイント&面接問題まとめ(その 2)](./docs/cs-basics/network/other-network-questions2.md)
+- [謝希仁教授『コンピュータネットワーク』内容まとめ(補足)](./docs/cs-basics/network/computer-network-xiexiren-summary.md)
+
+**重要概念の解説**:
+
+- [OSI と TCP/IP ネットワーク階層モデル詳解(基礎)](./docs/cs-basics/network/osi-and-tcp-ip-model.md)
+- [よく使うアプリケーション層プロトコルまとめ(アプリケーション層)](./docs/cs-basics/network/application-layer-protocol.md)
+- [HTTP と HTTPS の比較(アプリケーション層)](./docs/cs-basics/network/http-vs-https.md)
+- [HTTP 1.0 と HTTP 1.1 の比較(アプリケーション層)](./docs/cs-basics/network/http1.0-vs-http1.1.md)
+- [よく出る HTTP ステータスコード(アプリケーション層)](./docs/cs-basics/network/http-status-codes.md)
+- [DNS ドメインネームシステム詳解(アプリケーション層)](./docs/cs-basics/network/dns.md)
+- [TCP の 3 ウェイハンドシェイクと 4 ウェイハンドシェイク(トランスポート層)](./docs/cs-basics/network/tcp-connection-and-disconnection.md)
+- [TCP 通信の信頼性保証(トランスポート層)](./docs/cs-basics/network/tcp-reliability-guarantee.md)
+- [ARP プロトコル詳解(ネットワーク層)](./docs/cs-basics/network/arp.md)
+- [NAT プロトコル詳解(ネットワーク層)](./docs/cs-basics/network/nat.md)
+- [よくあるネットワーク攻撃手段まとめ(セキュリティ)](./docs/cs-basics/network/network-attack-means.md)
+
+### データ構造
+
+**図解データ構造:**
+
+- [線形データ構造: 配列、連結リスト、スタック、キュー](./docs/cs-basics/data-structure/linear-data-structure.md)
+- [グラフ](./docs/cs-basics/data-structure/graph.md)
+- [ヒープ](./docs/cs-basics/data-structure/heap.md)
+- [木](./docs/cs-basics/data-structure/tree.md): [赤黒木](./docs/cs-basics/data-structure/red-black-tree.md)、B 木、B+ 木、B\* 木、LSM 木を重点的に解説
+
+その他のよく使うデータ構造:
+
+- [ブルームフィルター](./docs/cs-basics/data-structure/bloom-filter.md)
+
+### アルゴリズム
+
+アルゴリズムの部分は非常に重要です。アルゴリズムの学習方法がわからない場合は、以下を参考にしてください:
+
+- [おすすめのアルゴリズム学習書籍・リソース](https://www.zhihu.com/question/323359308/answer/1545320858)。
+- [LeetCode の問題はどう解くべきか?](https://www.zhihu.com/question/31092580/answer/1534887374)
+
+**よく出るアルゴリズム問題まとめ**:
+
+- [よく出る文字列アルゴリズム問題まとめ](./docs/cs-basics/algorithms/string-algorithm-problems.md)
+- [よく出る連結リストアルゴリズム問題まとめ](./docs/cs-basics/algorithms/linkedlist-algorithm-problems.md)
+- [『剣指 Offer』のコーディング問題(一部)](./docs/cs-basics/algorithms/the-sword-refers-to-offer.md)
+- [10 大古典ソートアルゴリズム](./docs/cs-basics/algorithms/10-classical-sorting-algorithms.md)
+
+さらに、[GeeksforGeeks](https://www.geeksforgeeks.org/fundamentals-of-algorithms/) には、よく使うアルゴリズムの包括的なまとめがあります。
+
+## データベース
+
+### 基礎
+
+- [データベース基礎まとめ](./docs/database/basis.md)
+- [NoSQL 基礎まとめ](./docs/database/nosql.md)
+- [文字セット詳解](./docs/database/character-set.md)
+- SQL:
+ - [SQL 構文基礎まとめ](./docs/database/sql/sql-syntax-summary.md)
+ - [よく出る SQL 面接問題まとめ](./docs/database/sql/sql-questions-01.md)
+
+### MySQL
+
+**知識ポイント/面接問題のまとめ:**
+
+# MySQL のよく出る知識ポイント&面接問題まとめ (必読 :+1:)
+
+- [MySQL のよく出る知識ポイント&面接問題まとめ](./docs/database/mysql/mysql-questions-01.md)
+- [MySQL 高性能最適化の規範に関する提案](./docs/database/mysql/mysql-high-performance-optimization-specification-recommendations.md)
+
+**重要な知識ポイント:**
+
+- [MySQL インデックス詳解](./docs/database/mysql/mysql-index.md)
+- [MySQL トランザクション分離レベル詳解(図解付き)](./docs/database/mysql/transaction-isolation-level.md)
+- [MySQL の 3 つのログ詳解(binlog、redo log、undo log)](./docs/database/mysql/mysql-logs.md)
+- [InnoDB ストレージエンジンによる MVCC の実装](./docs/database/mysql/innodb-implementation-of-mvcc.md)
+- [MySQL における SQL 文の実行プロセス](./docs/database/mysql/how-sql-executed-in-mysql.md)
+- [MySQL クエリキャッシュ詳解](./docs/database/mysql/mysql-query-cache.md)
+- [MySQL クエリ実行計画の分析](./docs/database/mysql/mysql-query-execution-plan.md)
+- [MySQL の自動増分主キーは常に連続するのか?](./docs/database/mysql/mysql-auto-increment-primary-key-continuous.md)
+- [データベースへの時間関連データ保存に関する提案](./docs/database/mysql/some-thoughts-on-database-storage-time.md)
+- [MySQL における暗黙の型変換が引き起こすインデックス無効化](./docs/database/mysql/index-invalidation-caused-by-implicit-conversion.md)
+
+### Redis
+
+**知識ポイント/面接問題のまとめ** (必読 :+1:):
+
+- [Redis のよく出る知識ポイント&面接問題まとめ(その 1)](./docs/database/redis/redis-questions-01.md)
+- [Redis のよく出る知識ポイント&面接問題まとめ(その 2)](./docs/database/redis/redis-questions-02.md)
+
+**重要な知識ポイント:**
+
+- [よく使う 3 つのキャッシュ読み書き戦略詳解](./docs/database/redis/3-commonly-used-cache-read-and-write-strategies.md)
+- [Redis をメッセージキューとして使えるか?どう実装するか?](./docs/database/redis/redis-stream-mq.md)
+- [Redis の 5 つの基本データ構造詳解](./docs/database/redis/redis-data-structures-01.md)
+- [Redis の 3 つの特殊データ構造詳解](./docs/database/redis/redis-data-structures-02.md)
+- [Redis 永続化メカニズム詳解](./docs/database/redis/redis-persistence.md)
+- [Redis メモリ断片化詳解](./docs/database/redis/redis-memory-fragmentation.md)
+- [Redis ブロッキングのよくある原因まとめ](./docs/database/redis/redis-common-blocking-problems-summary.md)
+- [Redis クラスタ詳解](./docs/database/redis/redis-cluster.md)
+
+### MongoDB
+
+- [MongoDB のよく出る知識ポイント&面接問題まとめ(その 1)](./docs/database/mongodb/mongodb-questions-01.md)
+- [MongoDB のよく出る知識ポイント&面接問題まとめ(その 2)](./docs/database/mongodb/mongodb-questions-02.md)
+
+## 検索エンジン
+
+[Elasticsearch のよく出る面接問題まとめ(有料)](./docs/database/elasticsearch/elasticsearch-questions-01.md)
+
+
+
+## 開発ツール
+
+### Maven
+
+- [Maven コアコンセプトまとめ](./docs/tools/maven/maven-core-concepts.md)
+- [Maven ベストプラクティス](./docs/tools/maven/maven-best-practices.md)
+
+### Gradle
+
+[Gradle コアコンセプトまとめ](./docs/tools/gradle/gradle-core-concepts.md)(任意。中国では依然として Maven のほうが広く使われています)
+
+### Docker
+
+- [Docker コアコンセプトまとめ](./docs/tools/docker/docker-intro.md)
+- [Docker 実践](./docs/tools/docker/docker-in-action.md)
+
+### Git
+
+- [Git コアコンセプトまとめ](./docs/tools/git/git-intro.md)
+- [役立つ GitHub の便利テクニックまとめ](./docs/tools/git/github-tips.md)
+
+## システム設計
+
+- [よく出るシステム設計の面接問題まとめ](./docs/system-design/system-design-questions.md)
+- [よく出るデザインパターンの面接問題まとめ](./docs/system-design/design-pattern.md)
+
+### 基礎
+
+- [RESTful API 簡易チュートリアル](./docs/system-design/basis/RESTfulAPI.md)
+- [ソフトウェア工学簡易チュートリアル](./docs/system-design/basis/software-engineering.md)
+- [コード命名ガイド](./docs/system-design/basis/naming.md)
+- [コードリファクタリングガイド](./docs/system-design/basis/refactoring.md)
+- [単体テストガイド](./docs/system-design/basis/unit-test.md)
+
+### よく使うフレームワーク
+
+#### Spring/SpringBoot (必読 :+1:)
+
+**知識ポイント/面接問題のまとめ**:
+
+- [Spring のよく出る知識ポイント&面接問題まとめ](./docs/system-design/framework/spring/spring-knowledge-and-questions-summary.md)
+- [SpringBoot のよく出る知識ポイント&面接問題まとめ](./docs/system-design/framework/spring/springboot-knowledge-and-questions-summary.md)
+- [Spring/SpringBoot のよく使うアノテーションまとめ](./docs/system-design/framework/spring/spring-common-annotations.md)
+- [SpringBoot 初心者ガイド](https://github.com/Snailclimb/springboot-guide)
+
+**重要な知識ポイントの詳解**:
+
+- [IoC & AOP 詳解(さっと理解する)](./docs/system-design/framework/spring/ioc-and-aop.md)
+- [Spring トランザクション詳解](./docs/system-design/framework/spring/spring-transaction.md)
+- [Spring におけるデザインパターン詳解](./docs/system-design/framework/spring/spring-design-patterns-summary.md)
+- [SpringBoot 自動構成の原理詳解](./docs/system-design/framework/spring/spring-boot-auto-assembly-principles.md)
+
+#### MyBatis
+
+[よく出る MyBatis 面接問題まとめ](./docs/system-design/framework/mybatis/mybatis-interview.md)
+
+### セキュリティ
+
+#### 認証と認可
+
+- [認証と認可の基礎詳解](./docs/system-design/security/basis-of-authority-certification.md)
+- [JWT 基礎詳解](./docs/system-design/security/jwt-intro.md)
+- [JWT のメリット・デメリットの分析とよくある問題の解決策](./docs/system-design/security/advantages-and-disadvantages-of-jwt.md)
+- [SSO(シングルサインオン)詳解](./docs/system-design/security/sso-intro.md)
+- [権限システム設計詳解](./docs/system-design/security/design-of-authority-system.md)
+
+#### データセキュリティ
+
+- [よく使う暗号化アルゴリズムまとめ](./docs/system-design/security/encryption-algorithms.md)
+- [禁止ワードフィルタリングのソリューションまとめ](./docs/system-design/security/sentive-words-filter.md)
+- [データマスキングのソリューションまとめ](./docs/system-design/security/data-desensitization.md)
+- [なぜフロントエンドとバックエンドの両方でデータ検証を行う必要があるのか](./docs/system-design/security/data-validation.md)
+
+### スケジュールタスク
+
+[Java スケジュールタスク詳解](./docs/system-design/schedule-task.md)
+
+### Web リアルタイムメッセージプッシュ
+
+[Web リアルタイムメッセージプッシュ詳解](./docs/system-design/web-real-time-message-push.md)
+
+## 分散システム
+
+### 理論、アルゴリズム、プロトコル
+
+- [CAP 理論と BASE 理論の解説](https://javaguide.cn/distributed-system/protocol/cap-and-base-theorem.html)
+- [Paxos アルゴリズムの解説](https://javaguide.cn/distributed-system/protocol/paxos-algorithm.html)
+- [Raft アルゴリズムの解説](https://javaguide.cn/distributed-system/protocol/raft-algorithm.html)
+- [Gossip プロトコル詳解](https://javaguide.cn/distributed-system/protocol/gossip-protocol.html)
+- [コンシステントハッシュアルゴリズム詳解](https://javaguide.cn/distributed-system/protocol/consistent-hashing.html)
+
+### RPC
+
+- [RPC 基礎まとめ](https://javaguide.cn/distributed-system/rpc/rpc-intro.html)
+- [Dubbo のよく出る知識ポイント&面接問題まとめ](https://javaguide.cn/distributed-system/rpc/dubbo.html)
+
+### ZooKeeper
+
+> この 2 つの記事は内容が一部重複している可能性がありますが、両方読むことをおすすめします。
+
+- [ZooKeeper 関連概念まとめ(入門)](https://javaguide.cn/distributed-system/distributed-process-coordination/zookeeper/zookeeper-intro.html)
+- [ZooKeeper 関連概念まとめ(応用)](https://javaguide.cn/distributed-system/distributed-process-coordination/zookeeper/zookeeper-plus.html)
+
+### API ゲートウェイ
+
+- [API ゲートウェイ基礎まとめ](https://javaguide.cn/distributed-system/api-gateway.html)
+- [Spring Cloud Gateway のよく出る知識ポイント&面接問題まとめ](./docs/distributed-system/spring-cloud-gateway-questions.md)
+
+### 分散 ID
+
+- [分散 ID 入門と実装ソリューションまとめ](https://javaguide.cn/distributed-system/distributed-id.html)
+- [分散 ID の設計ガイド](https://javaguide.cn/distributed-system/distributed-id-design.html)
+
+### 分散ロック
+
+# 分散ロック
+
+- [分散ロック入門](https://javaguide.cn/distributed-system/distributed-lock.html)
+- [よく使う分散ロック実装ソリューションまとめ](https://javaguide.cn/distributed-system/distributed-lock-implementations.html)
+
+### 分散トランザクション
+
+[よく出る分散トランザクションの知識ポイント&面接問題まとめ](https://javaguide.cn/distributed-system/distributed-transaction.html)
+
+### 分散設定センター
+
+[よく出る分散設定センターの知識ポイント&面接問題まとめ](./docs/distributed-system/distributed-configuration-center.md)
+
+## 高性能
+
+### データベース最適化
+
+- [データベースの読み書き分離とシャーディング(分库分表)](./docs/high-performance/read-and-write-separation-and-library-subtable.md)
+- [コールドデータとホットデータの分離](./docs/high-performance/data-cold-hot-separation.md)
+- [よく使う SQL 最適化手法まとめ](./docs/high-performance/sql-optimization.md)
+- [深いページネーション入門と最適化の提案](./docs/high-performance/deep-pagination-optimization.md)
+
+### ロードバランシング
+
+[よく出るロードバランシングの知識ポイント&面接問題まとめ](./docs/high-performance/load-balancing.md)
+
+### CDN
+
+[よく出る CDN(コンテンツデリバリーネットワーク)の知識ポイント&面接問題まとめ](./docs/high-performance/cdn.md)
+
+### メッセージキュー
+
+- [メッセージキュー基礎知識まとめ](./docs/high-performance/message-queue/message-queue.md)
+- [Disruptor のよく出る知識ポイント&面接問題まとめ](./docs/high-performance/message-queue/disruptor-questions.md)
+- [RabbitMQ のよく出る知識ポイント&面接問題まとめ](./docs/high-performance/message-queue/rabbitmq-questions.md)
+- [RocketMQ のよく出る知識ポイント&面接問題まとめ](./docs/high-performance/message-queue/rocketmq-questions.md)
+- [Kafka のよく出る知識ポイント&面接問題まとめ](./docs/high-performance/message-queue/kafka-questions-01.md)
+
+## 高可用性
+
+[高可用性システム設計ガイド](./docs/high-availability/high-availability-system-design.md)
+
+### 冗長設計
+
+[冗長設計詳解](./docs/high-availability/redundancy.md)
+
+### レート制限
+
+[サービスのレート制限詳解](./docs/high-availability/limit-request.md)
+
+### フォールバック&サーキットブレーカー
+
+[フォールバック&サーキットブレーカー詳解](./docs/high-availability/fallback-and-circuit-breaker.md)
+
+### タイムアウト&リトライ
+
+[タイムアウト&リトライ詳解](./docs/high-availability/timeout-and-retry.md)
+
+### クラスタリング
+
+同一サービスのインスタンスを複数デプロイすることで、単一障害点を回避します。
+
+### 災害復旧設計とアクティブ-アクティブ構成
+
+**災害復旧(Disaster Recovery)** = 災害耐性(Disaster Tolerance)+ バックアップ(Backup)。
+
+- **バックアップ**: システムが生成するすべての重要なデータを複数回バックアップすること。
+- **災害耐性**: 異なる場所に完全に同一のシステムを 2 つ構築すること。一方の場所のシステムが突然故障した場合、アプリケーションシステム全体をもう一方に切り替えられるため、システムが正常にサービスを提供し続けられます。
+
+**アクティブ-アクティブ構成(Active-Active Deployment)** は、異なる場所にサービスをデプロイし、同時に外部へサービスを提供する構成を指します。従来の災害復旧設計との主な違いは「アクティブ-アクティブ」、つまりすべてのサイトが同時に外部へサービスを提供している点です。アクティブ-アクティブ構成は、火災、地震などの自然災害や人為的災害といった予期せぬ事態に備えるためのものです。
+
+## Star のトレンド
+
+
+
+## 公式公衆号
+
+私の最新記事を見逃さず、価値ある内容を共有したい方は、私の公式公衆号をフォローしてください。
+
+
diff --git a/docs/.vuepress/client.ts b/docs/.vuepress/client.ts
new file mode 100644
index 00000000000..ce78c371142
--- /dev/null
+++ b/docs/.vuepress/client.ts
@@ -0,0 +1,48 @@
+import { defineClientConfig } from "vuepress/client";
+import { defineAsyncComponent, h } from "vue";
+import DeferredLayoutToggle from "./components/DeferredLayoutToggle.vue";
+import ClickImagePreview from "./components/ClickImagePreview.vue";
+import LazyMermaid from "./components/LazyMermaid.vue";
+import GlobalUnlock from "./components/unlock/GlobalUnlock.vue";
+
+const UnlockContent = defineAsyncComponent(
+ () => import("./components/unlock/UnlockContent.vue"),
+);
+
+const CHUNK_LOAD_ERROR_PATTERN =
+ /Failed to fetch dynamically imported module|Importing a module script failed|error loading dynamically imported module|Unable to preload CSS/i;
+
+const getCurrentLocation = (): string =>
+ `${window.location.pathname}${window.location.search}${window.location.hash}`;
+
+export default defineClientConfig({
+ enhance({ app, router }) {
+ app.component("Mermaid", LazyMermaid);
+ app.component("UnlockContent", UnlockContent);
+
+ router.onError((error, to) => {
+ if (typeof window === "undefined") return;
+
+ const message = error instanceof Error ? error.message : String(error);
+ if (!CHUNK_LOAD_ERROR_PATTERN.test(message)) return;
+
+ const target = to?.fullPath || getCurrentLocation();
+ const reloadKey = `javaguide:chunk-reload:${target}`;
+
+ if (window.sessionStorage.getItem(reloadKey) === "1") return;
+
+ window.sessionStorage.setItem(reloadKey, "1");
+ window.location.assign(target);
+ });
+
+ router.afterEach((to) => {
+ if (typeof window === "undefined") return;
+ window.sessionStorage.removeItem(`javaguide:chunk-reload:${to.fullPath}`);
+ });
+ },
+ rootComponents: [
+ () => h(DeferredLayoutToggle),
+ () => h(GlobalUnlock),
+ () => h(ClickImagePreview),
+ ],
+});
diff --git a/docs/.vuepress/components/ClickImagePreview.vue b/docs/.vuepress/components/ClickImagePreview.vue
new file mode 100644
index 00000000000..3eab943803f
--- /dev/null
+++ b/docs/.vuepress/components/ClickImagePreview.vue
@@ -0,0 +1,173 @@
+
+
diff --git a/README_EN.md b/README_EN.md
new file mode 100644
index 00000000000..9d2228cf75c
--- /dev/null
+++ b/README_EN.md
@@ -0,0 +1,449 @@
+# JavaGuide
+
+**English** | **[日本語](./README_JA.md)** | **[简体中文](./README.md)**
+
+Recommended to read online for a better experience and faster speed: [javaguide.cn](https://javaguide.cn/)
+
+## AI Application Development Interview Guide
+
+An open-source guide for backend developers on AI application development, AI programming practices, and interviews, covering core technologies and engineering practices such as LLM, Agent, RAG, MCP, Claude Code, Codex, and more. Benchmarking JavaGuide! If it helps, welcome to Star!
+
+- **Project URL**: [https://github.com/Snailclimb/AIGuide](https://github.com/Snailclimb/AIGuide)
+- **Online Reading**: [https://javaguide.cn/ai/](https://javaguide.cn/ai/)
+
+## Backend Interview Preparation
+
+- [⭐Java Backend Interview Preparation Plan (Covering General Backend System)](./docs/interview-preparation/backend-interview-plan.md) (Must-read :+1:)
+- [How to Efficiently Prepare for Java Interviews?](./docs/interview-preparation/teach-you-how-to-prepare-for-the-interview-hand-in-hand.md)
+- [Key Summary of Java Backend Interviews](./docs/interview-preparation/key-points-of-interview.md)
+- [Java Learning Roadmap (Latest, 4w+ Words)](./docs/interview-preparation/java-roadmap.md)
+- [Programmer Resume Writing Guide](./docs/interview-preparation/resume-guide.md)
+- [Project Experience Guide](./docs/interview-preparation/project-experience-guide.md)
+- [How to Deal with Interview Nervousness?](./docs/interview-preparation/how-to-handle-interview-nerves.md)
+- [What to Do Without Internship Experience in Campus Recruitment? How to Write About Internship Experience?](./docs/interview-preparation/internship-experience.md)
+
+## Java
+
+### Java Basics
+
+**Knowledge Points/Interview Questions Summary** (Must-read :+1:):
+
+- [Summary of Common Java Basics Knowledge Points & Interview Questions (Part 1)](./docs/java/basis/java-basic-questions-01.md)
+- [Summary of Common Java Basics Knowledge Points & Interview Questions (Part 2)](./docs/java/basis/java-basic-questions-02.md)
+- [Summary of Common Java Basics Knowledge Points & Interview Questions (Part 3)](./docs/java/basis/java-basic-questions-03.md)
+
+**Important Knowledge Points Explanation**:
+
+- [Why is There Only Pass-by-Value in Java?](./docs/java/basis/why-there-only-value-passing-in-java.md)
+- [Serialization in Java Explained](./docs/java/basis/serialization.md)
+- [Generics & Wildcards Explained](./docs/java/basis/generics-and-wildcards.md)
+- [Java Reflection Mechanism Explained](./docs/java/basis/reflection.md)
+- [Java Proxy Pattern Explained](./docs/java/basis/proxy.md)
+- [BigDecimal Explained](./docs/java/basis/bigdecimal.md)
+- [Java Magic Class Unsafe Explained](./docs/java/basis/unsafe.md)
+- [Java SPI Mechanism Explained](./docs/java/basis/spi.md)
+- [Java Syntactic Sugar Explained](./docs/java/basis/syntactic-sugar.md)
+
+### Collections
+
+**Knowledge Points/Interview Questions Summary**:
+
+- [Summary of Common Java Collection Knowledge Points & Interview Questions (Part 1)](./docs/java/collection/java-collection-questions-01.md) (Must-read :+1:)
+- [Summary of Common Java Collection Knowledge Points & Interview Questions (Part 2)](./docs/java/collection/java-collection-questions-02.md) (Must-read :+1:)
+- [Summary of Java Container Usage Precautions](./docs/java/collection/java-collection-precautions-for-use.md)
+
+**Source Code Analysis**:
+
+- [ArrayList Core Source Code + Expansion Mechanism Analysis](./docs/java/collection/arraylist-source-code.md)
+- [LinkedList Core Source Code Analysis](./docs/java/collection/linkedlist-source-code.md)
+- [HashMap Core Source Code + Underlying Data Structure Analysis](./docs/java/collection/hashmap-source-code.md)
+- [ConcurrentHashMap Core Source Code + Underlying Data Structure Analysis](./docs/java/collection/concurrent-hash-map-source-code.md)
+- [LinkedHashMap Core Source Code Analysis](./docs/java/collection/linkedhashmap-source-code.md)
+- [CopyOnWriteArrayList Core Source Code Analysis](./docs/java/collection/copyonwritearraylist-source-code.md)
+- [ArrayBlockingQueue Core Source Code Analysis](./docs/java/collection/arrayblockingqueue-source-code.md)
+- [PriorityQueue Core Source Code Analysis](./docs/java/collection/priorityqueue-source-code.md)
+- [DelayQueue Core Source Code Analysis](./docs/java/collection/delayqueue-source-code.md)
+
+### IO
+
+- [IO Basic Knowledge Summary](./docs/java/io/io-basis.md)
+- [IO Design Patterns Summary](./docs/java/io/io-design-patterns.md)
+- [IO Model Explanation](./docs/java/io/io-model.md)
+- [NIO Core Knowledge Summary](./docs/java/io/nio-basis.md)
+
+### Concurrency
+
+**Knowledge Points/Interview Questions Summary** (Must-read :+1:)
+
+- [Common Java Concurrency Knowledge Points & Interview Questions Summary (Part 1)](./docs/java/concurrent/java-concurrent-questions-01.md)
+- [Common Java Concurrency Knowledge Points & Interview Questions Summary (Part 2)](./docs/java/concurrent/java-concurrent-questions-02.md)
+- [Common Java Concurrency Knowledge Points & Interview Questions Summary (Part 3)](./docs/java/concurrent/java-concurrent-questions-03.md)
+
+**Important Knowledge Points Explanation**:
+
+- [Optimistic Lock and Pessimistic Lock Explanation](./docs/java/concurrent/optimistic-lock-and-pessimistic-lock.md)
+- [CAS Explanation](./docs/java/concurrent/cas.md)
+- [JMM (Java Memory Model) Explanation](./docs/java/concurrent/jmm.md)
+- **Thread Pool**: [Java Thread Pool Explanation](./docs/java/concurrent/java-thread-pool-summary.md), [Java Thread Pool Best Practices](./docs/java/concurrent/java-thread-pool-best-practices.md)
+- [ThreadLocal Explanation](./docs/java/concurrent/threadlocal.md)
+- [Java Concurrent Collections Summary](./docs/java/concurrent/java-concurrent-collections.md)
+- [Atomic Classes Summary](./docs/java/concurrent/atomic-classes.md)
+- [AQS Explanation](./docs/java/concurrent/aqs.md)
+- [CompletableFuture Explanation](./docs/java/concurrent/completablefuture-intro.md)
+
+### JVM (Must-read :+1:)
+
+The JVM part mainly refers to the [JVM Specification - Java 8](https://docs.oracle.com/javase/specs/jvms/se8/html/index.html) and Zhou Zhiming's book [《Deep Understanding of Java Virtual Machine (3rd Edition)》](https://book.douban.com/subject/34907497/) (strongly recommend to read it several times!).
+
+- **[Java Memory Area](./docs/java/jvm/memory-area.md)**
+- **[JVM Garbage Collection](./docs/java/jvm/jvm-garbage-collection.md)**
+- [Class File Structure](./docs/java/jvm/class-file-structure.md)
+- **[Class Loading Process](./docs/java/jvm/class-loading-process.md)**
+- [Class Loader](./docs/java/jvm/classloader.md)
+- [【To Be Completed】Most Important JVM Parameters Summary (Half Translated)](./docs/java/jvm/jvm-parameters-intro.md)
+- [【Bonus】Understand JVM in Plain Language](./docs/java/jvm/jvm-intro.md)
+- [JDK Monitoring and Troubleshooting Tools](./docs/java/jvm/jdk-monitoring-and-troubleshooting-tools.md)
+
+### New Features
+
+- **Java 8**: [Java 8 New Features Summary (Translated)](./docs/java/new-features/java8-tutorial-translate.md), [Common Java 8 New Features Summary](./docs/java/new-features/java8-common-new-features.md)
+- [Java 9 New Features Overview](./docs/java/new-features/java9.md)
+- [Java 10 New Features Overview](./docs/java/new-features/java10.md)
+- [Java 11 New Features Overview](./docs/java/new-features/java11.md)
+- [Java 12 & 13 New Features Overview](./docs/java/new-features/java12-13.md)
+- [Java 14 & 15 New Features Overview](./docs/java/new-features/java14-15.md)
+- [Java 16 New Features Overview](./docs/java/new-features/java16.md)
+- [Java 17 New Features Overview](./docs/java/new-features/java17.md)
+- [Java 18 New Features Overview](./docs/java/new-features/java18.md)
+- [Java 19 New Features Overview](./docs/java/new-features/java19.md)
+- [Java 20 New Features Overview](./docs/java/new-features/java20.md)
+- [Java 21 New Features Overview](./docs/java/new-features/java21.md)
+- [Java 22 & 23 New Features Overview](./docs/java/new-features/java22-23.md)
+- [Java 24 New Features Overview](./docs/java/new-features/java24.md)
+- [Java 25 New Features Overview](./docs/java/new-features/java25.md)
+
+## Computer Fundamentals
+
+### Operating Systems
+
+- [Summary of Common Operating System Knowledge Points & Interview Questions (Part 1)](./docs/cs-basics/operating-system/operating-system-basic-questions-01.md)
+- [Summary of Common Operating System Knowledge Points & Interview Questions (Part 2)](./docs/cs-basics/operating-system/operating-system-basic-questions-02.md)
+- **Linux**:
+ - [Summary of Essential Linux Basics for Backend Developers](./docs/cs-basics/operating-system/linux-intro.md)
+ - [Summary of Shell Scripting Basics](./docs/cs-basics/operating-system/shell-intro.md)
+
+### Networking
+
+**Knowledge Points/Interview Questions Summary**:
+
+- [Summary of Common Computer Network Knowledge Points & Interview Questions (Part 1)](./docs/cs-basics/network/other-network-questions.md)
+- [Summary of Common Computer Network Knowledge Points & Interview Questions (Part 2)](./docs/cs-basics/network/other-network-questions2.md)
+- [Summary of Professor Xie Xiren's "Computer Network" Content (Supplementary)](./docs/cs-basics/network/computer-network-xiexiren-summary.md)
+
+**Important Knowledge Points Explanation**:
+
+- [Detailed Explanation of the OSI and TCP/IP Network Layer Models (Basics)](./docs/cs-basics/network/osi-and-tcp-ip-model.md)
+- [Summary of Common Application Layer Protocols (Application Layer)](./docs/cs-basics/network/application-layer-protocol.md)
+- [HTTP vs HTTPS (Application Layer)](./docs/cs-basics/network/http-vs-https.md)
+- [HTTP 1.0 vs HTTP 1.1 (Application Layer)](./docs/cs-basics/network/http1.0-vs-http1.1.md)
+- [Common HTTP Status Codes (Application Layer)](./docs/cs-basics/network/http-status-codes.md)
+- [Detailed Explanation of the DNS Domain Name System (Application Layer)](./docs/cs-basics/network/dns.md)
+- [TCP Three-Way Handshake and Four-Way Termination (Transport Layer)](./docs/cs-basics/network/tcp-connection-and-disconnection.md)
+- [What's the Difference Between TCP Keepalive and HTTP Keep-Alive? (Transport Layer)](./docs/cs-basics/network/tcp-keepalive-vs-http-keepalive.md)
+- [TCP Transmission Reliability Guarantee (Transport Layer)](./docs/cs-basics/network/tcp-reliability-guarantee.md)
+- [If You Can Ping Through, Does TCP Definitely Connect? (Transport Layer)](./docs/cs-basics/network/can-ping-but-tcp-may-not-connect.md)
+- [Can TCP and UDP Use the Same Port? (Transport Layer)](./docs/cs-basics/network/can-tcp-and-udp-use-the-same-port.md)
+- [What's the Maximum Number of TCP Connections a Host Can Maintain? (Transport Layer)](./docs/cs-basics/network/maximum-number-of-tcp-connections-per-host.md)
+- [Detailed Explanation of the ARP Protocol (Network Layer)](./docs/cs-basics/network/arp.md)
+- [Detailed Explanation of the NAT Protocol (Network Layer)](./docs/cs-basics/network/nat.md)
+- [Summary of Common Network Attack Means (Security)](./docs/cs-basics/network/network-attack-means.md)
+
+### Data Structures
+
+**Illustrated Data Structures:**
+
+- [Linear Data Structures: Arrays, Linked Lists, Stacks, Queues](./docs/cs-basics/data-structure/linear-data-structure.md)
+- [Graphs](./docs/cs-basics/data-structure/graph.md)
+- [Heaps](./docs/cs-basics/data-structure/heap.md)
+- [Trees](./docs/cs-basics/data-structure/tree.md): Focus on [Red-Black Trees](./docs/cs-basics/data-structure/red-black-tree.md), B-, B+, B\* Trees, and LSM Trees
+
+Other Commonly Used Data Structures:
+
+- [Bloom Filters](./docs/cs-basics/data-structure/bloom-filter.md)
+
+### Algorithms
+
+The algorithm part is very important. If you don't know how to learn algorithms, you can refer to:
+
+- [Recommended Algorithm Learning Books and Resources](https://www.zhihu.com/question/323359308/answer/1545320858).
+- [How to Solve LeetCode Problems?](https://www.zhihu.com/question/31092580/answer/1534887374)
+
+**Summary of Common Algorithm Problems**:
+
+- [Summary of Several Common String Algorithm Problems](./docs/cs-basics/algorithms/string-algorithm-problems.md)
+- [Summary of Several Common Linked List Algorithm Problems](./docs/cs-basics/algorithms/linkedlist-algorithm-problems.md)
+- [Part of the Coding Questions from the "Sword Refers to Offer"](./docs/cs-basics/algorithms/the-sword-refers-to-offer.md)
+- [Ten Classic Sorting Algorithms](./docs/cs-basics/algorithms/10-classical-sorting-algorithms.md)
+
+Additionally, [GeeksforGeeks](https://www.geeksforgeeks.org/fundamentals-of-algorithms/) has a comprehensive summary of common algorithms.
+
+## Database
+
+### Database Basics
+
+- [Summary of Database Basics](./docs/database/basis.md)
+- [Summary of NoSQL Basics](./docs/database/nosql.md)
+- [Explanation of Character Sets](./docs/database/character-set.md)
+- SQL:
+ - [Summary of SQL Syntax Basics](./docs/database/sql/sql-syntax-summary.md)
+ - [Summary of Common SQL Interview Questions](./docs/database/sql/sql-questions-01.md)
+
+### MySQL
+
+**Knowledge Points/Interview Questions Summary:**
+
+- **[MySQL Common Knowledge Points & Interview Questions Summary](./docs/database/mysql/mysql-questions-01.md)** (Must-read :+1:)
+- [MySQL High-Performance Optimization Specification Recommendations](./docs/database/mysql/mysql-high-performance-optimization-specification-recommendations.md)
+
+**Important Knowledge Points:**
+
+- [MySQL Index Details](./docs/database/mysql/mysql-index.md)
+- [Summary of MySQL Index Invalidation Scenarios](./docs/database/mysql/mysql-index-invalidation.md)
+- [Detailed Explanation of MySQL Transaction Isolation Levels (with Pictures)](./docs/database/mysql/transaction-isolation-level.md)
+- [Detailed Explanation of MySQL's Three Logs (binlog, redo log, and undo log)](./docs/database/mysql/mysql-logs.md)
+- [InnoDB Storage Engine's Implementation of MVCC](./docs/database/mysql/innodb-implementation-of-mvcc.md)
+- [How SQL Statements are Executed in MySQL](./docs/database/mysql/how-sql-executed-in-mysql.md)
+- [Detailed Explanation of MySQL Query Cache](./docs/database/mysql/mysql-query-cache.md)
+- [MySQL Query Execution Plan Analysis](./docs/database/mysql/mysql-query-execution-plan.md)
+- [Are MySQL Auto-Increment Primary Keys Always Continuous?](./docs/database/mysql/mysql-auto-increment-primary-key-continuous.md)
+- [Suggestions on Storing Time-Related Data in MySQL](./docs/database/mysql/some-thoughts-on-database-storage-time.md)
+- [Index Invalidation Caused by Implicit Conversion in MySQL](./docs/database/mysql/index-invalidation-caused-by-implicit-conversion.md)
+
+### Redis
+
+**Knowledge Points/Interview Questions Summary** (Must-read :+1:):
+
+- [Redis Common Knowledge Points & Interview Questions Summary (Part 1)](./docs/database/redis/redis-questions-01.md)
+- [Redis Common Knowledge Points & Interview Questions Summary (Part 2)](./docs/database/redis/redis-questions-02.md)
+
+**Important Knowledge Points:**
+
+- [Detailed Explanation of 3 Common Cache Read and Write Strategies](./docs/database/redis/3-commonly-used-cache-read-and-write-strategies.md)
+- [Can Redis Be Used as a Message Queue? How to Implement It?](./docs/database/redis/redis-stream-mq.md)
+- [Detailed Explanation of Redis' 5 Basic Data Structures](./docs/database/redis/redis-data-structures-01.md)
+- [Detailed Explanation of Redis' 3 Special Data Structures](./docs/database/redis/redis-data-structures-02.md)
+- [Detailed Explanation of Redis Persistence Mechanism](./docs/database/redis/redis-persistence.md)
+- [Detailed Explanation of Redis Memory Fragmentation](./docs/database/redis/redis-memory-fragmentation.md)
+- [Summary of Common Causes of Redis Blocking](./docs/database/redis/redis-common-blocking-problems-summary.md)
+- [Detailed Explanation of Redis Cluster](./docs/database/redis/redis-cluster.md)
+
+### MongoDB
+
+- [MongoDB Common Knowledge Points & Interview Questions Summary (Part 1)](./docs/database/mongodb/mongodb-questions-01.md)
+- [MongoDB Common Knowledge Points & Interview Questions Summary (Part 2)](./docs/database/mongodb/mongodb-questions-02.md)
+
+## Search Engines
+
+[Elasticsearch Common Interview Questions Summary (Paid)](./docs/database/elasticsearch/elasticsearch-questions-01.md)
+
+
+
+## Development Tools
+
+### Maven
+
+- [Maven Core Concepts Summary](./docs/tools/maven/maven-core-concepts.md)
+- [Maven Best Practices](./docs/tools/maven/maven-best-practices.md)
+
+### Gradle
+
+[Gradle Core Concepts Summary](./docs/tools/gradle/gradle-core-concepts.md) (Optional, Maven is still more widely used in China)
+
+### Docker
+
+- [Docker Core Concepts Summary](./docs/tools/docker/docker-intro.md)
+- [Docker in Action](./docs/tools/docker/docker-in-action.md)
+
+### Git
+
+- [Git Core Concepts Summary](./docs/tools/git/git-intro.md)
+- [Useful GitHub Tips Summary](./docs/tools/git/github-tips.md)
+
+## System Design
+
+- [⭐Common System Design Interview Questions Summary](./docs/system-design/system-design-questions.md)
+- [⭐Common Design Pattern Interview Questions Summary](https://interview.javaguide.cn/system-design/design-pattern.html)
+
+### System Design Basics
+
+- [A Brief Tutorial on RESTful API](./docs/system-design/basis/RESTfulAPI.md)
+- [A Brief Tutorial on Software Engineering](./docs/system-design/basis/software-engineering.md)
+- [Code Naming Guide](./docs/system-design/basis/naming.md)
+- [Code Refactoring Guide](./docs/system-design/basis/refactoring.md)
+- [Unit Testing Guide](./docs/system-design/basis/unit-test.md)
+
+### Common Frameworks
+
+#### Spring/SpringBoot (Must-read :+1:)
+
+**Knowledge Points/Interview Questions Summary**:
+
+- [Summary of Common Spring Knowledge Points and Interview Questions](./docs/system-design/framework/spring/spring-knowledge-and-questions-summary.md)
+- [Summary of Common SpringBoot Knowledge Points and Interview Questions](./docs/system-design/framework/spring/springboot-knowledge-and-questions-summary.md)
+- [Summary of Common Spring/Spring Boot Annotations](./docs/system-design/framework/spring/spring-common-annotations.md)
+- [SpringBoot Beginner's Guide](https://github.com/Snailclimb/springboot-guide)
+
+**Detailed Explanation of Important Knowledge Points**:
+
+- [Detailed Explanation of IoC & AOP (Quick Understanding)](./docs/system-design/framework/spring/ioc-and-aop.md)
+- [Detailed Explanation of Spring Transactions](./docs/system-design/framework/spring/spring-transaction.md)
+- [Detailed Explanation of Design Patterns in Spring](./docs/system-design/framework/spring/spring-design-patterns-summary.md)
+- [Detailed Explanation of SpringBoot Auto-Configuration Principles](./docs/system-design/framework/spring/spring-boot-auto-assembly-principles.md)
+
+#### MyBatis
+
+[Summary of Common MyBatis Interview Questions](./docs/system-design/framework/mybatis/mybatis-interview.md)
+
+### Security
+
+#### Authentication and Authorization
+
+- [Detailed Explanation of Authentication and Authorization Fundamentals](./docs/system-design/security/basis-of-authority-certification.md)
+- [Detailed Explanation of JWT Basics](./docs/system-design/security/jwt-intro.md)
+- [Analysis of Advantages and Disadvantages of JWT and Common Problem Solutions](./docs/system-design/security/advantages-and-disadvantages-of-jwt.md)
+- [Detailed Explanation of SSO (Single Sign-On)](./docs/system-design/security/sso-intro.md)
+- [Detailed Explanation of Permission System Design](./docs/system-design/security/design-of-authority-system.md)
+
+#### Data Security
+
+- [Summary of Common Encryption Algorithms](./docs/system-design/security/encryption-algorithms.md)
+- [Summary of Sensitive Word Filtering Solutions](./docs/system-design/security/sentive-words-filter.md)
+- [Summary of Data Desensitization Solutions](./docs/system-design/security/data-desensitization.md)
+- [Why Both Front-end and Back-end Need to Perform Data Validation](./docs/system-design/security/data-validation.md)
+- [Why Can Passwords Only Be Reset When Forgotten, Not Told the Original Password?](./docs/system-design/security/why-password-reset-instead-of-retrieval.md)
+
+### Scheduled Tasks
+
+[Detailed Explanation of Java Scheduled Tasks](./docs/system-design/schedule-task.md)
+
+### Web Real-time Message Pushing
+
+[Detailed Explanation of Web Real-time Message Pushing](./docs/system-design/web-real-time-message-push.md)
+
+## Distributed System
+
+- [⭐High-Frequency Distributed System Interview Questions](https://interview.javaguide.cn/distributed-system/distributed-system.html)
+
+### Theory, Algorithms, and Protocols
+
+- [Interpretation of CAP Theory and BASE Theory](https://javaguide.cn/distributed-system/protocol/cap-and-base-theorem.html)
+- [Interpretation of Paxos Algorithm](https://javaguide.cn/distributed-system/protocol/paxos-algorithm.html)
+- [Interpretation of Raft Algorithm](https://javaguide.cn/distributed-system/protocol/raft-algorithm.html)
+- [Interpretation of ZAB Protocol](https://javaguide.cn/distributed-system/protocol/zab.html)
+- [Detailed Explanation of Gossip Protocol](https://javaguide.cn/distributed-system/protocol/gossip-protocol.html)
+- [Detailed Explanation of Consistent Hashing Algorithm](https://javaguide.cn/distributed-system/protocol/consistent-hashing.html)
+
+### RPC
+
+- [Summary of RPC Basics](https://javaguide.cn/distributed-system/rpc/rpc-intro.html)
+- [Summary of Common Dubbo Knowledge Points and Interview Questions](https://javaguide.cn/distributed-system/rpc/dubbo.html)
+
+### ZooKeeper
+
+> These two articles may have some overlapping content, it is recommended to read both.
+
+- [Summary of ZooKeeper Relevant Concepts (Beginner)](https://javaguide.cn/distributed-system/distributed-process-coordination/zookeeper/zookeeper-intro.html)
+- [Summary of ZooKeeper Relevant Concepts (Advanced)](https://javaguide.cn/distributed-system/distributed-process-coordination/zookeeper/zookeeper-plus.html)
+
+### API Gateway
+
+- [Summary of API Gateway Basics](https://javaguide.cn/distributed-system/api-gateway.html)
+- [Summary of Common Spring Cloud Gateway Knowledge Points and Interview Questions](./docs/distributed-system/spring-cloud-gateway-questions.md)
+
+### Distributed ID
+
+- [Introduction to Distributed ID and Summary of Implementation Solutions](https://javaguide.cn/distributed-system/distributed-id.html)
+- [Design Guide for Distributed ID](https://javaguide.cn/distributed-system/distributed-id-design.html)
+
+### Distributed Lock
+
+- [Introduction to Distributed Locks](https://javaguide.cn/distributed-system/distributed-lock.html)
+- [Summary of Common Distributed Lock Implementation Solutions](https://javaguide.cn/distributed-system/distributed-lock-implementations.html)
+
+### Distributed Transactions
+
+[Summary of Common Distributed Transaction Knowledge Points and Interview Questions](https://javaguide.cn/distributed-system/distributed-transaction.html)
+
+### Distributed Configuration Center
+
+[Summary of Common Distributed Configuration Center Knowledge Points and Interview Questions](./docs/distributed-system/distributed-configuration-center.md)
+
+## High Performance
+
+### Database Optimization
+
+- [Database Read-Write Separation and Database Sharding](./docs/high-performance/read-and-write-separation-and-library-subtable.md)
+- [Data Separation of Cold and Hot Data](./docs/high-performance/data-cold-hot-separation.md)
+- [Summary of Common SQL Optimization Methods](./docs/high-performance/sql-optimization.md)
+- [Introduction to Deep Pagination and Optimization Suggestions](./docs/high-performance/deep-pagination-optimization.md)
+
+### Load Balancing
+
+[Summary of Common Load Balancing Knowledge Points and Interview Questions](./docs/high-performance/load-balancing.md)
+
+### CDN
+
+[Summary of Common CDN (Content Delivery Network) Knowledge Points and Interview Questions](./docs/high-performance/cdn.md)
+
+### Message Queue
+
+- [Summary of Message Queue Basic Knowledge](./docs/high-performance/message-queue/message-queue.md)
+- [Summary of Common Disruptor Knowledge Points and Interview Questions](./docs/high-performance/message-queue/disruptor-questions.md)
+- [Summary of Common RabbitMQ Knowledge Points and Interview Questions](./docs/high-performance/message-queue/rabbitmq-questions.md)
+- [Summary of Common RocketMQ Knowledge Points and Interview Questions](./docs/high-performance/message-queue/rocketmq-questions.md)
+- [Summary of Common Kafka Knowledge Points and Interview Questions](./docs/high-performance/message-queue/kafka-questions-01.md)
+
+## High Availability
+
+[Guide to High Availability System Design](./docs/high-availability/high-availability-system-design.md)
+
+### Redundancy Design
+
+[Detailed Explanation of Redundancy Design](./docs/high-availability/redundancy.md)
+
+### Rate Limiting
+
+[Detailed Explanation of Service Rate Limiting](./docs/high-availability/limit-request.md)
+
+### Fallback & Circuit Breaker
+
+[Detailed Explanation of Fallback & Circuit Breaker](./docs/high-availability/fallback-and-circuit-breaker.md)
+
+### Timeout & Retry
+
+[Detailed Explanation of Timeout & Retry](./docs/high-availability/timeout-and-retry.md)
+
+### Clustering
+
+Deploying multiple instances of the same service to avoid single point of failure.
+
+### Disaster Recovery Design and Active-Active Deployment
+
+**Disaster Recovery** = Disaster Tolerance + Backup.
+
+- **Backup**: Backing up all important data generated by the system multiple times.
+- **Disaster Tolerance**: Establishing two completely identical systems in different locations. When the system in one location suddenly fails, the entire application system can be switched to the other one, so that the system can continue to provide services normally.
+
+**Active-Active Deployment** describes deploying services in different locations and simultaneously providing services externally. The main difference from traditional disaster recovery design is the "active-active" nature, i.e., all sites are simultaneously providing external services. Active-active deployment is to cope with unexpected situations such as fires, earthquakes and other natural or man-made disasters.
+
+## Star Trend
+
+
+
+## Official Public Account
+
+If you want to stay up-to-date with my latest articles and share my valuable content, you can follow my official public account.
+
+
+
+
diff --git a/README_JA.md b/README_JA.md
new file mode 100644
index 00000000000..b715a9cfb74
--- /dev/null
+++ b/README_JA.md
@@ -0,0 +1,432 @@
+**[English](./README_EN.md)** | **日本語** | **[简体中文](./README.md)**
+
+より快適でスピーディーな体験のため、オンライン閲覧プラットフォームでの閲覧をおすすめします!リンク: [javaguide.cn](https://javaguide.cn/)。
+
+## プロジェクト関連
+
+- [プロジェクト紹介](https://javaguide.cn/javaguide/intro.html)
+- [使い方の提案](https://javaguide.cn/javaguide/use-suggestion.html)
+- [コントリビューションガイド](https://javaguide.cn/javaguide/contribution-guideline.html)
+- [FAQ](https://javaguide.cn/javaguide/faq.html)
+
+## Java
+
+### 基礎
+
+**知識ポイント/面接問題のまとめ**: (必見 :+1:):
+
+- [Java 基礎のよく出る知識ポイント&面接問題まとめ(その 1)](./docs/java/basis/java-basic-questions-01.md)
+- [Java 基礎のよく出る知識ポイント&面接問題まとめ(その 2)](./docs/java/basis/java-basic-questions-02.md)
+- [Java 基礎のよく出る知識ポイント&面接問題まとめ(その 3)](./docs/java/basis/java-basic-questions-03.md)
+
+**重要な知識ポイントの解説**:
+
+- [Java はなぜ値渡ししかないのか?](./docs/java/basis/why-there-only-value-passing-in-java.md)
+- [Java のシリアライズ詳解](./docs/java/basis/serialization.md)
+- [ジェネリクス&ワイルドカード詳解](./docs/java/basis/generics-and-wildcards.md)
+- [Java リフレクション機構詳解](./docs/java/basis/reflection.md)
+- [Java プロキシパターン詳解](./docs/java/basis/proxy.md)
+- [BigDecimal 詳解](./docs/java/basis/bigdecimal.md)
+- [Java のマジッククラス Unsafe 詳解](./docs/java/basis/unsafe.md)
+- [Java SPI 機構詳解](./docs/java/basis/spi.md)
+- [Java のシンタックスシュガー詳解](./docs/java/basis/syntactic-sugar.md)
+
+### コレクション
+
+**知識ポイント/面接問題のまとめ**:
+
+- [Java コレクションのよく出る知識ポイント&面接問題まとめ(その 1)](./docs/java/collection/java-collection-questions-01.md) (必見 :+1:)
+- [Java コレクションのよく出る知識ポイント&面接問題まとめ(その 2)](./docs/java/collection/java-collection-questions-02.md) (必見 :+1:)
+- [Java コンテナ使用上の注意点まとめ](./docs/java/collection/java-collection-precautions-for-use.md)
+
+**ソースコード解析**:
+
+- [ArrayList コアソースコード+拡張メカニズム解析](./docs/java/collection/arraylist-source-code.md)
+- [LinkedList コアソースコード解析](./docs/java/collection/linkedlist-source-code.md)
+- [HashMap コアソースコード+基盤データ構造解析](./docs/java/collection/hashmap-source-code.md)
+
+# Java コレクション&並行処理シリーズ
+
+## コレクション
+
+- [ConcurrentHashMap コアソースコード+基盤データ構造解析](./docs/java/collection/concurrent-hash-map-source-code.md)
+- [LinkedHashMap コアソースコード解析](./docs/java/collection/linkedhashmap-source-code.md)
+- [CopyOnWriteArrayList コアソースコード解析](./docs/java/collection/copyonwritearraylist-source-code.md)
+- [ArrayBlockingQueue コアソースコード解析](./docs/java/collection/arrayblockingqueue-source-code.md)
+- [PriorityQueue コアソースコード解析](./docs/java/collection/priorityqueue-source-code.md)
+- [DelayQueue コアソースコード解析](./docs/java/collection/delayqueue-source-code.md)
+
+### IO
+
+- [IO 基礎知識まとめ](./docs/java/io/io-basis.md)
+- [IO デザインパターンまとめ](./docs/java/io/io-design-patterns.md)
+- [IO モデル詳解](./docs/java/io/io-model.md)
+- [NIO コア知識まとめ](./docs/java/io/nio-basis.md)
+
+### 並行処理
+
+**知識ポイント/面接問題のまとめ** : (必読 :+1:)
+
+- [Java 並行処理のよく出る知識ポイント&面接問題まとめ(その 1)](./docs/java/concurrent/java-concurrent-questions-01.md)
+- [Java 並行処理のよく出る知識ポイント&面接問題まとめ(その 2)](./docs/java/concurrent/java-concurrent-questions-02.md)
+- [Java 並行処理のよく出る知識ポイント&面接問題まとめ(その 3)](./docs/java/concurrent/java-concurrent-questions-03.md)
+
+**重要な知識ポイントの解説**:
+
+- [楽観ロックと悲観ロック詳解](./docs/java/concurrent/optimistic-lock-and-pessimistic-lock.md)
+- [CAS 詳解](./docs/java/concurrent/cas.md)
+- [JMM(Java メモリモデル)詳解](./docs/java/concurrent/jmm.md)
+- **スレッドプール**: [Java スレッドプール詳解](./docs/java/concurrent/java-thread-pool-summary.md)、[Java スレッドプールのベストプラクティス](./docs/java/concurrent/java-thread-pool-best-practices.md)
+- [ThreadLocal 詳解](./docs/java/concurrent/threadlocal.md)
+- [Java 並行コレクションまとめ](./docs/java/concurrent/java-concurrent-collections.md)
+- [Atomic クラスまとめ](./docs/java/concurrent/atomic-classes.md)
+- [AQS 詳解](./docs/java/concurrent/aqs.md)
+- [CompletableFuture 詳解](./docs/java/concurrent/completablefuture-intro.md)
+
+### JVM (必読 :+1:)
+
+JVM の部分は主に [JVM 仕様 - Java 8](https://docs.oracle.com/javase/specs/jvms/se8/html/index.html) と、周志明氏の著書 [《Java 仮想マシンの深い理解(第 3 版)》](https://book.douban.com/subject/34907497/)(何度も読むことを強くおすすめします!)を参考にしています。
+
+- **[Java メモリ領域](./docs/java/jvm/memory-area.md)**
+- **[JVM ガベージコレクション](./docs/java/jvm/jvm-garbage-collection.md)**
+- [クラスファイルの構造](./docs/java/jvm/class-file-structure.md)
+- **[クラスローディングのプロセス](./docs/java/jvm/class-loading-process.md)**
+- [クラスローダー](./docs/java/jvm/classloader.md)
+- [【未完成】最も重要な JVM パラメータまとめ(一部翻訳)](./docs/java/jvm/jvm-parameters-intro.md)
+- [【おまけ】わかりやすく学ぶ JVM](./docs/java/jvm/jvm-intro.md)
+- [JDK 監視・トラブルシューティングツール](./docs/java/jvm/jdk-monitoring-and-troubleshooting-tools.md)
+
+### 新機能
+
+- **Java 8**: [Java 8 新機能まとめ(翻訳)](./docs/java/new-features/java8-tutorial-translate.md)、[Java 8 のよく使う新機能まとめ](./docs/java/new-features/java8-common-new-features.md)
+- [Java 9 新機能概要](./docs/java/new-features/java9.md)
+- [Java 10 新機能概要](./docs/java/new-features/java10.md)
+- [Java 11 新機能概要](./docs/java/new-features/java11.md)
+- [Java 12 & 13 新機能概要](./docs/java/new-features/java12-13.md)
+- [Java 14 & 15 新機能概要](./docs/java/new-features/java14-15.md)
+- [Java 16 新機能概要](./docs/java/new-features/java16.md)
+- [Java 17 新機能概要](./docs/java/new-features/java17.md)
+- [Java 18 新機能概要](./docs/java/new-features/java18.md)
+- [Java 19 新機能概要](./docs/java/new-features/java19.md)
+- [Java 20 新機能概要](./docs/java/new-features/java20.md)
+
+# Java 21、22、23、24、25 の新機能概要
+
+## コンピュータ基礎
+
+### オペレーティングシステム
+
+- [オペレーティングシステムのよく出る知識ポイント&面接問題まとめ(その 1)](./docs/cs-basics/operating-system/operating-system-basic-questions-01.md)
+- [オペレーティングシステムのよく出る知識ポイント&面接問題まとめ(その 2)](./docs/cs-basics/operating-system/operating-system-basic-questions-02.md)
+- **Linux**:
+ - [バックエンド開発者が押さえておくべき Linux 基礎まとめ](./docs/cs-basics/operating-system/linux-intro.md)
+ - [シェルスクリプト基礎まとめ](./docs/cs-basics/operating-system/shell-intro.md)
+
+### ネットワーク
+
+**知識ポイント/面接問題のまとめ**:
+
+- [コンピュータネットワークのよく出る知識ポイント&面接問題まとめ(その 1)](./docs/cs-basics/network/other-network-questions.md)
+- [コンピュータネットワークのよく出る知識ポイント&面接問題まとめ(その 2)](./docs/cs-basics/network/other-network-questions2.md)
+- [謝希仁教授『コンピュータネットワーク』内容まとめ(補足)](./docs/cs-basics/network/computer-network-xiexiren-summary.md)
+
+**重要概念の解説**:
+
+- [OSI と TCP/IP ネットワーク階層モデル詳解(基礎)](./docs/cs-basics/network/osi-and-tcp-ip-model.md)
+- [よく使うアプリケーション層プロトコルまとめ(アプリケーション層)](./docs/cs-basics/network/application-layer-protocol.md)
+- [HTTP と HTTPS の比較(アプリケーション層)](./docs/cs-basics/network/http-vs-https.md)
+- [HTTP 1.0 と HTTP 1.1 の比較(アプリケーション層)](./docs/cs-basics/network/http1.0-vs-http1.1.md)
+- [よく出る HTTP ステータスコード(アプリケーション層)](./docs/cs-basics/network/http-status-codes.md)
+- [DNS ドメインネームシステム詳解(アプリケーション層)](./docs/cs-basics/network/dns.md)
+- [TCP の 3 ウェイハンドシェイクと 4 ウェイハンドシェイク(トランスポート層)](./docs/cs-basics/network/tcp-connection-and-disconnection.md)
+- [TCP 通信の信頼性保証(トランスポート層)](./docs/cs-basics/network/tcp-reliability-guarantee.md)
+- [ARP プロトコル詳解(ネットワーク層)](./docs/cs-basics/network/arp.md)
+- [NAT プロトコル詳解(ネットワーク層)](./docs/cs-basics/network/nat.md)
+- [よくあるネットワーク攻撃手段まとめ(セキュリティ)](./docs/cs-basics/network/network-attack-means.md)
+
+### データ構造
+
+**図解データ構造:**
+
+- [線形データ構造: 配列、連結リスト、スタック、キュー](./docs/cs-basics/data-structure/linear-data-structure.md)
+- [グラフ](./docs/cs-basics/data-structure/graph.md)
+- [ヒープ](./docs/cs-basics/data-structure/heap.md)
+- [木](./docs/cs-basics/data-structure/tree.md): [赤黒木](./docs/cs-basics/data-structure/red-black-tree.md)、B 木、B+ 木、B\* 木、LSM 木を重点的に解説
+
+その他のよく使うデータ構造:
+
+- [ブルームフィルター](./docs/cs-basics/data-structure/bloom-filter.md)
+
+### アルゴリズム
+
+アルゴリズムの部分は非常に重要です。アルゴリズムの学習方法がわからない場合は、以下を参考にしてください:
+
+- [おすすめのアルゴリズム学習書籍・リソース](https://www.zhihu.com/question/323359308/answer/1545320858)。
+- [LeetCode の問題はどう解くべきか?](https://www.zhihu.com/question/31092580/answer/1534887374)
+
+**よく出るアルゴリズム問題まとめ**:
+
+- [よく出る文字列アルゴリズム問題まとめ](./docs/cs-basics/algorithms/string-algorithm-problems.md)
+- [よく出る連結リストアルゴリズム問題まとめ](./docs/cs-basics/algorithms/linkedlist-algorithm-problems.md)
+- [『剣指 Offer』のコーディング問題(一部)](./docs/cs-basics/algorithms/the-sword-refers-to-offer.md)
+- [10 大古典ソートアルゴリズム](./docs/cs-basics/algorithms/10-classical-sorting-algorithms.md)
+
+さらに、[GeeksforGeeks](https://www.geeksforgeeks.org/fundamentals-of-algorithms/) には、よく使うアルゴリズムの包括的なまとめがあります。
+
+## データベース
+
+### 基礎
+
+- [データベース基礎まとめ](./docs/database/basis.md)
+- [NoSQL 基礎まとめ](./docs/database/nosql.md)
+- [文字セット詳解](./docs/database/character-set.md)
+- SQL:
+ - [SQL 構文基礎まとめ](./docs/database/sql/sql-syntax-summary.md)
+ - [よく出る SQL 面接問題まとめ](./docs/database/sql/sql-questions-01.md)
+
+### MySQL
+
+**知識ポイント/面接問題のまとめ:**
+
+# MySQL のよく出る知識ポイント&面接問題まとめ (必読 :+1:)
+
+- [MySQL のよく出る知識ポイント&面接問題まとめ](./docs/database/mysql/mysql-questions-01.md)
+- [MySQL 高性能最適化の規範に関する提案](./docs/database/mysql/mysql-high-performance-optimization-specification-recommendations.md)
+
+**重要な知識ポイント:**
+
+- [MySQL インデックス詳解](./docs/database/mysql/mysql-index.md)
+- [MySQL トランザクション分離レベル詳解(図解付き)](./docs/database/mysql/transaction-isolation-level.md)
+- [MySQL の 3 つのログ詳解(binlog、redo log、undo log)](./docs/database/mysql/mysql-logs.md)
+- [InnoDB ストレージエンジンによる MVCC の実装](./docs/database/mysql/innodb-implementation-of-mvcc.md)
+- [MySQL における SQL 文の実行プロセス](./docs/database/mysql/how-sql-executed-in-mysql.md)
+- [MySQL クエリキャッシュ詳解](./docs/database/mysql/mysql-query-cache.md)
+- [MySQL クエリ実行計画の分析](./docs/database/mysql/mysql-query-execution-plan.md)
+- [MySQL の自動増分主キーは常に連続するのか?](./docs/database/mysql/mysql-auto-increment-primary-key-continuous.md)
+- [データベースへの時間関連データ保存に関する提案](./docs/database/mysql/some-thoughts-on-database-storage-time.md)
+- [MySQL における暗黙の型変換が引き起こすインデックス無効化](./docs/database/mysql/index-invalidation-caused-by-implicit-conversion.md)
+
+### Redis
+
+**知識ポイント/面接問題のまとめ** (必読 :+1:):
+
+- [Redis のよく出る知識ポイント&面接問題まとめ(その 1)](./docs/database/redis/redis-questions-01.md)
+- [Redis のよく出る知識ポイント&面接問題まとめ(その 2)](./docs/database/redis/redis-questions-02.md)
+
+**重要な知識ポイント:**
+
+- [よく使う 3 つのキャッシュ読み書き戦略詳解](./docs/database/redis/3-commonly-used-cache-read-and-write-strategies.md)
+- [Redis をメッセージキューとして使えるか?どう実装するか?](./docs/database/redis/redis-stream-mq.md)
+- [Redis の 5 つの基本データ構造詳解](./docs/database/redis/redis-data-structures-01.md)
+- [Redis の 3 つの特殊データ構造詳解](./docs/database/redis/redis-data-structures-02.md)
+- [Redis 永続化メカニズム詳解](./docs/database/redis/redis-persistence.md)
+- [Redis メモリ断片化詳解](./docs/database/redis/redis-memory-fragmentation.md)
+- [Redis ブロッキングのよくある原因まとめ](./docs/database/redis/redis-common-blocking-problems-summary.md)
+- [Redis クラスタ詳解](./docs/database/redis/redis-cluster.md)
+
+### MongoDB
+
+- [MongoDB のよく出る知識ポイント&面接問題まとめ(その 1)](./docs/database/mongodb/mongodb-questions-01.md)
+- [MongoDB のよく出る知識ポイント&面接問題まとめ(その 2)](./docs/database/mongodb/mongodb-questions-02.md)
+
+## 検索エンジン
+
+[Elasticsearch のよく出る面接問題まとめ(有料)](./docs/database/elasticsearch/elasticsearch-questions-01.md)
+
+
+
+## 開発ツール
+
+### Maven
+
+- [Maven コアコンセプトまとめ](./docs/tools/maven/maven-core-concepts.md)
+- [Maven ベストプラクティス](./docs/tools/maven/maven-best-practices.md)
+
+### Gradle
+
+[Gradle コアコンセプトまとめ](./docs/tools/gradle/gradle-core-concepts.md)(任意。中国では依然として Maven のほうが広く使われています)
+
+### Docker
+
+- [Docker コアコンセプトまとめ](./docs/tools/docker/docker-intro.md)
+- [Docker 実践](./docs/tools/docker/docker-in-action.md)
+
+### Git
+
+- [Git コアコンセプトまとめ](./docs/tools/git/git-intro.md)
+- [役立つ GitHub の便利テクニックまとめ](./docs/tools/git/github-tips.md)
+
+## システム設計
+
+- [よく出るシステム設計の面接問題まとめ](./docs/system-design/system-design-questions.md)
+- [よく出るデザインパターンの面接問題まとめ](./docs/system-design/design-pattern.md)
+
+### 基礎
+
+- [RESTful API 簡易チュートリアル](./docs/system-design/basis/RESTfulAPI.md)
+- [ソフトウェア工学簡易チュートリアル](./docs/system-design/basis/software-engineering.md)
+- [コード命名ガイド](./docs/system-design/basis/naming.md)
+- [コードリファクタリングガイド](./docs/system-design/basis/refactoring.md)
+- [単体テストガイド](./docs/system-design/basis/unit-test.md)
+
+### よく使うフレームワーク
+
+#### Spring/SpringBoot (必読 :+1:)
+
+**知識ポイント/面接問題のまとめ**:
+
+- [Spring のよく出る知識ポイント&面接問題まとめ](./docs/system-design/framework/spring/spring-knowledge-and-questions-summary.md)
+- [SpringBoot のよく出る知識ポイント&面接問題まとめ](./docs/system-design/framework/spring/springboot-knowledge-and-questions-summary.md)
+- [Spring/SpringBoot のよく使うアノテーションまとめ](./docs/system-design/framework/spring/spring-common-annotations.md)
+- [SpringBoot 初心者ガイド](https://github.com/Snailclimb/springboot-guide)
+
+**重要な知識ポイントの詳解**:
+
+- [IoC & AOP 詳解(さっと理解する)](./docs/system-design/framework/spring/ioc-and-aop.md)
+- [Spring トランザクション詳解](./docs/system-design/framework/spring/spring-transaction.md)
+- [Spring におけるデザインパターン詳解](./docs/system-design/framework/spring/spring-design-patterns-summary.md)
+- [SpringBoot 自動構成の原理詳解](./docs/system-design/framework/spring/spring-boot-auto-assembly-principles.md)
+
+#### MyBatis
+
+[よく出る MyBatis 面接問題まとめ](./docs/system-design/framework/mybatis/mybatis-interview.md)
+
+### セキュリティ
+
+#### 認証と認可
+
+- [認証と認可の基礎詳解](./docs/system-design/security/basis-of-authority-certification.md)
+- [JWT 基礎詳解](./docs/system-design/security/jwt-intro.md)
+- [JWT のメリット・デメリットの分析とよくある問題の解決策](./docs/system-design/security/advantages-and-disadvantages-of-jwt.md)
+- [SSO(シングルサインオン)詳解](./docs/system-design/security/sso-intro.md)
+- [権限システム設計詳解](./docs/system-design/security/design-of-authority-system.md)
+
+#### データセキュリティ
+
+- [よく使う暗号化アルゴリズムまとめ](./docs/system-design/security/encryption-algorithms.md)
+- [禁止ワードフィルタリングのソリューションまとめ](./docs/system-design/security/sentive-words-filter.md)
+- [データマスキングのソリューションまとめ](./docs/system-design/security/data-desensitization.md)
+- [なぜフロントエンドとバックエンドの両方でデータ検証を行う必要があるのか](./docs/system-design/security/data-validation.md)
+
+### スケジュールタスク
+
+[Java スケジュールタスク詳解](./docs/system-design/schedule-task.md)
+
+### Web リアルタイムメッセージプッシュ
+
+[Web リアルタイムメッセージプッシュ詳解](./docs/system-design/web-real-time-message-push.md)
+
+## 分散システム
+
+### 理論、アルゴリズム、プロトコル
+
+- [CAP 理論と BASE 理論の解説](https://javaguide.cn/distributed-system/protocol/cap-and-base-theorem.html)
+- [Paxos アルゴリズムの解説](https://javaguide.cn/distributed-system/protocol/paxos-algorithm.html)
+- [Raft アルゴリズムの解説](https://javaguide.cn/distributed-system/protocol/raft-algorithm.html)
+- [Gossip プロトコル詳解](https://javaguide.cn/distributed-system/protocol/gossip-protocol.html)
+- [コンシステントハッシュアルゴリズム詳解](https://javaguide.cn/distributed-system/protocol/consistent-hashing.html)
+
+### RPC
+
+- [RPC 基礎まとめ](https://javaguide.cn/distributed-system/rpc/rpc-intro.html)
+- [Dubbo のよく出る知識ポイント&面接問題まとめ](https://javaguide.cn/distributed-system/rpc/dubbo.html)
+
+### ZooKeeper
+
+> この 2 つの記事は内容が一部重複している可能性がありますが、両方読むことをおすすめします。
+
+- [ZooKeeper 関連概念まとめ(入門)](https://javaguide.cn/distributed-system/distributed-process-coordination/zookeeper/zookeeper-intro.html)
+- [ZooKeeper 関連概念まとめ(応用)](https://javaguide.cn/distributed-system/distributed-process-coordination/zookeeper/zookeeper-plus.html)
+
+### API ゲートウェイ
+
+- [API ゲートウェイ基礎まとめ](https://javaguide.cn/distributed-system/api-gateway.html)
+- [Spring Cloud Gateway のよく出る知識ポイント&面接問題まとめ](./docs/distributed-system/spring-cloud-gateway-questions.md)
+
+### 分散 ID
+
+- [分散 ID 入門と実装ソリューションまとめ](https://javaguide.cn/distributed-system/distributed-id.html)
+- [分散 ID の設計ガイド](https://javaguide.cn/distributed-system/distributed-id-design.html)
+
+### 分散ロック
+
+# 分散ロック
+
+- [分散ロック入門](https://javaguide.cn/distributed-system/distributed-lock.html)
+- [よく使う分散ロック実装ソリューションまとめ](https://javaguide.cn/distributed-system/distributed-lock-implementations.html)
+
+### 分散トランザクション
+
+[よく出る分散トランザクションの知識ポイント&面接問題まとめ](https://javaguide.cn/distributed-system/distributed-transaction.html)
+
+### 分散設定センター
+
+[よく出る分散設定センターの知識ポイント&面接問題まとめ](./docs/distributed-system/distributed-configuration-center.md)
+
+## 高性能
+
+### データベース最適化
+
+- [データベースの読み書き分離とシャーディング(分库分表)](./docs/high-performance/read-and-write-separation-and-library-subtable.md)
+- [コールドデータとホットデータの分離](./docs/high-performance/data-cold-hot-separation.md)
+- [よく使う SQL 最適化手法まとめ](./docs/high-performance/sql-optimization.md)
+- [深いページネーション入門と最適化の提案](./docs/high-performance/deep-pagination-optimization.md)
+
+### ロードバランシング
+
+[よく出るロードバランシングの知識ポイント&面接問題まとめ](./docs/high-performance/load-balancing.md)
+
+### CDN
+
+[よく出る CDN(コンテンツデリバリーネットワーク)の知識ポイント&面接問題まとめ](./docs/high-performance/cdn.md)
+
+### メッセージキュー
+
+- [メッセージキュー基礎知識まとめ](./docs/high-performance/message-queue/message-queue.md)
+- [Disruptor のよく出る知識ポイント&面接問題まとめ](./docs/high-performance/message-queue/disruptor-questions.md)
+- [RabbitMQ のよく出る知識ポイント&面接問題まとめ](./docs/high-performance/message-queue/rabbitmq-questions.md)
+- [RocketMQ のよく出る知識ポイント&面接問題まとめ](./docs/high-performance/message-queue/rocketmq-questions.md)
+- [Kafka のよく出る知識ポイント&面接問題まとめ](./docs/high-performance/message-queue/kafka-questions-01.md)
+
+## 高可用性
+
+[高可用性システム設計ガイド](./docs/high-availability/high-availability-system-design.md)
+
+### 冗長設計
+
+[冗長設計詳解](./docs/high-availability/redundancy.md)
+
+### レート制限
+
+[サービスのレート制限詳解](./docs/high-availability/limit-request.md)
+
+### フォールバック&サーキットブレーカー
+
+[フォールバック&サーキットブレーカー詳解](./docs/high-availability/fallback-and-circuit-breaker.md)
+
+### タイムアウト&リトライ
+
+[タイムアウト&リトライ詳解](./docs/high-availability/timeout-and-retry.md)
+
+### クラスタリング
+
+同一サービスのインスタンスを複数デプロイすることで、単一障害点を回避します。
+
+### 災害復旧設計とアクティブ-アクティブ構成
+
+**災害復旧(Disaster Recovery)** = 災害耐性(Disaster Tolerance)+ バックアップ(Backup)。
+
+- **バックアップ**: システムが生成するすべての重要なデータを複数回バックアップすること。
+- **災害耐性**: 異なる場所に完全に同一のシステムを 2 つ構築すること。一方の場所のシステムが突然故障した場合、アプリケーションシステム全体をもう一方に切り替えられるため、システムが正常にサービスを提供し続けられます。
+
+**アクティブ-アクティブ構成(Active-Active Deployment)** は、異なる場所にサービスをデプロイし、同時に外部へサービスを提供する構成を指します。従来の災害復旧設計との主な違いは「アクティブ-アクティブ」、つまりすべてのサイトが同時に外部へサービスを提供している点です。アクティブ-アクティブ構成は、火災、地震などの自然災害や人為的災害といった予期せぬ事態に備えるためのものです。
+
+## Star のトレンド
+
+
+
+## 公式公衆号
+
+私の最新記事を見逃さず、価値ある内容を共有したい方は、私の公式公衆号をフォローしてください。
+
+
diff --git a/docs/.vuepress/client.ts b/docs/.vuepress/client.ts
new file mode 100644
index 00000000000..ce78c371142
--- /dev/null
+++ b/docs/.vuepress/client.ts
@@ -0,0 +1,48 @@
+import { defineClientConfig } from "vuepress/client";
+import { defineAsyncComponent, h } from "vue";
+import DeferredLayoutToggle from "./components/DeferredLayoutToggle.vue";
+import ClickImagePreview from "./components/ClickImagePreview.vue";
+import LazyMermaid from "./components/LazyMermaid.vue";
+import GlobalUnlock from "./components/unlock/GlobalUnlock.vue";
+
+const UnlockContent = defineAsyncComponent(
+ () => import("./components/unlock/UnlockContent.vue"),
+);
+
+const CHUNK_LOAD_ERROR_PATTERN =
+ /Failed to fetch dynamically imported module|Importing a module script failed|error loading dynamically imported module|Unable to preload CSS/i;
+
+const getCurrentLocation = (): string =>
+ `${window.location.pathname}${window.location.search}${window.location.hash}`;
+
+export default defineClientConfig({
+ enhance({ app, router }) {
+ app.component("Mermaid", LazyMermaid);
+ app.component("UnlockContent", UnlockContent);
+
+ router.onError((error, to) => {
+ if (typeof window === "undefined") return;
+
+ const message = error instanceof Error ? error.message : String(error);
+ if (!CHUNK_LOAD_ERROR_PATTERN.test(message)) return;
+
+ const target = to?.fullPath || getCurrentLocation();
+ const reloadKey = `javaguide:chunk-reload:${target}`;
+
+ if (window.sessionStorage.getItem(reloadKey) === "1") return;
+
+ window.sessionStorage.setItem(reloadKey, "1");
+ window.location.assign(target);
+ });
+
+ router.afterEach((to) => {
+ if (typeof window === "undefined") return;
+ window.sessionStorage.removeItem(`javaguide:chunk-reload:${to.fullPath}`);
+ });
+ },
+ rootComponents: [
+ () => h(DeferredLayoutToggle),
+ () => h(GlobalUnlock),
+ () => h(ClickImagePreview),
+ ],
+});
diff --git a/docs/.vuepress/components/ClickImagePreview.vue b/docs/.vuepress/components/ClickImagePreview.vue
new file mode 100644
index 00000000000..3eab943803f
--- /dev/null
+++ b/docs/.vuepress/components/ClickImagePreview.vue
@@ -0,0 +1,173 @@
+
+  +
+